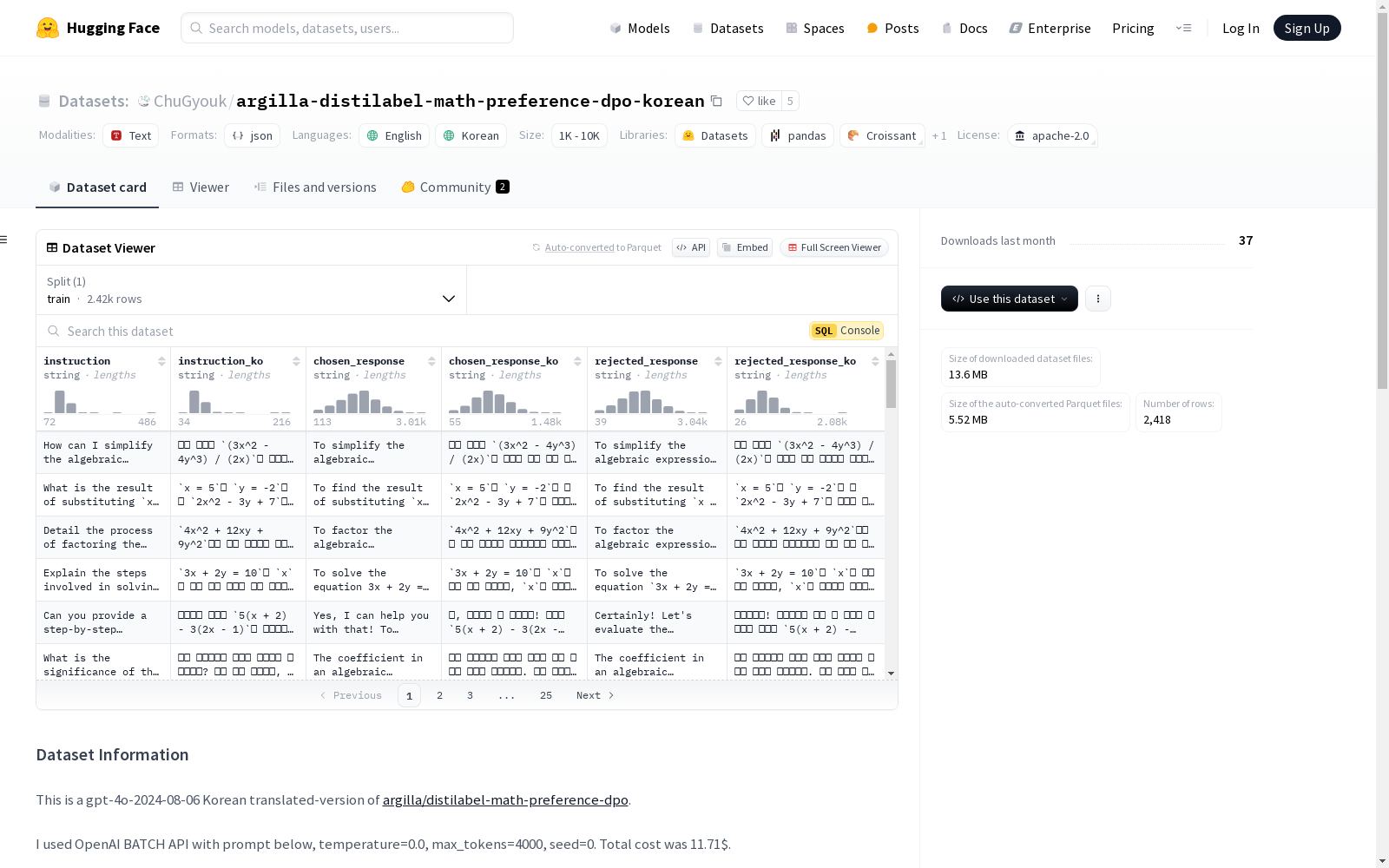
argilla-distilabel-math-preference-dpo-korean
收藏数据集信息
这是一个gpt-4o-2024-08-06版本的韩语翻译版数据集,源自argilla/distilabel-math-preference-dpo。
该数据集使用OpenAI BATCH API进行翻译,参数设置为temperature=0.0,max_tokens=4000,seed=0,总成本为11.71美元。
需要注意的是,第1317条数据因不符合给定格式,进行了修改。例如,<translated_question>标记被翻译为<의문>。
翻译提示
你的任务是将英语文本翻译成韩语,用于直接偏好优化训练数据。这些数据包括一个问题、一个选定回答和一个拒绝回答。你的目标是准确翻译内容,同时保留原文的意思和结构。
以下是需要翻译的内容:
问题: <question> {QUESTION} </question>
选定回答: <chosen_response> {CHOSEN_RESPONSE} </chosen_response>
拒绝回答: <rejected_response> {REJECTED_RESPONSE} </rejected_response>
请按照以下步骤进行翻译:
- 将问题从英语翻译成韩语。
- 将选定回答从英语翻译成韩语。
- 将拒绝回答从英语翻译成韩语。
翻译时请遵循以下指南:
- 准确地将文本从英语翻译成韩语,保持原文的意思和语气。
- 不要翻译数学表达式或方程式。保持它们在原文中的样子。
- 保持任何格式,如空格、换行或项目符号,在你的翻译中。
- 在你的翻译中保持选定回答和拒绝回答的区别。这种区别在韩语版本中也应该是清晰的。
请以以下格式提供你的翻译:
<translated_question> [在此处插入问题的韩语翻译] </translated_question>
<translated_chosen_response> [在此处插入选定回答的韩语翻译] </translated_chosen_response>
<translated_rejected_response> [在此处插入拒绝回答的韩语翻译] </translated_rejected_response>
确保选定回答和拒绝回答之间的区别在你的翻译中保持清晰。同时,确保选定回答和拒绝回答之间的区别在韩语翻译中保持清晰。使一个回答优于另一个回答的细微差别应该被保留。如果有任何文化特定参考或习语没有直接的韩语等价词,请提供最接近的适当翻译,并在必要时在括号中添加简要解释。