AnyInsertion
收藏Hugging Face2025-04-24 更新2025-04-25 收录
下载链接:
https://huggingface.co/datasets/WensongSong/AnyInsertion
下载链接
链接失效反馈官方服务:
资源简介:
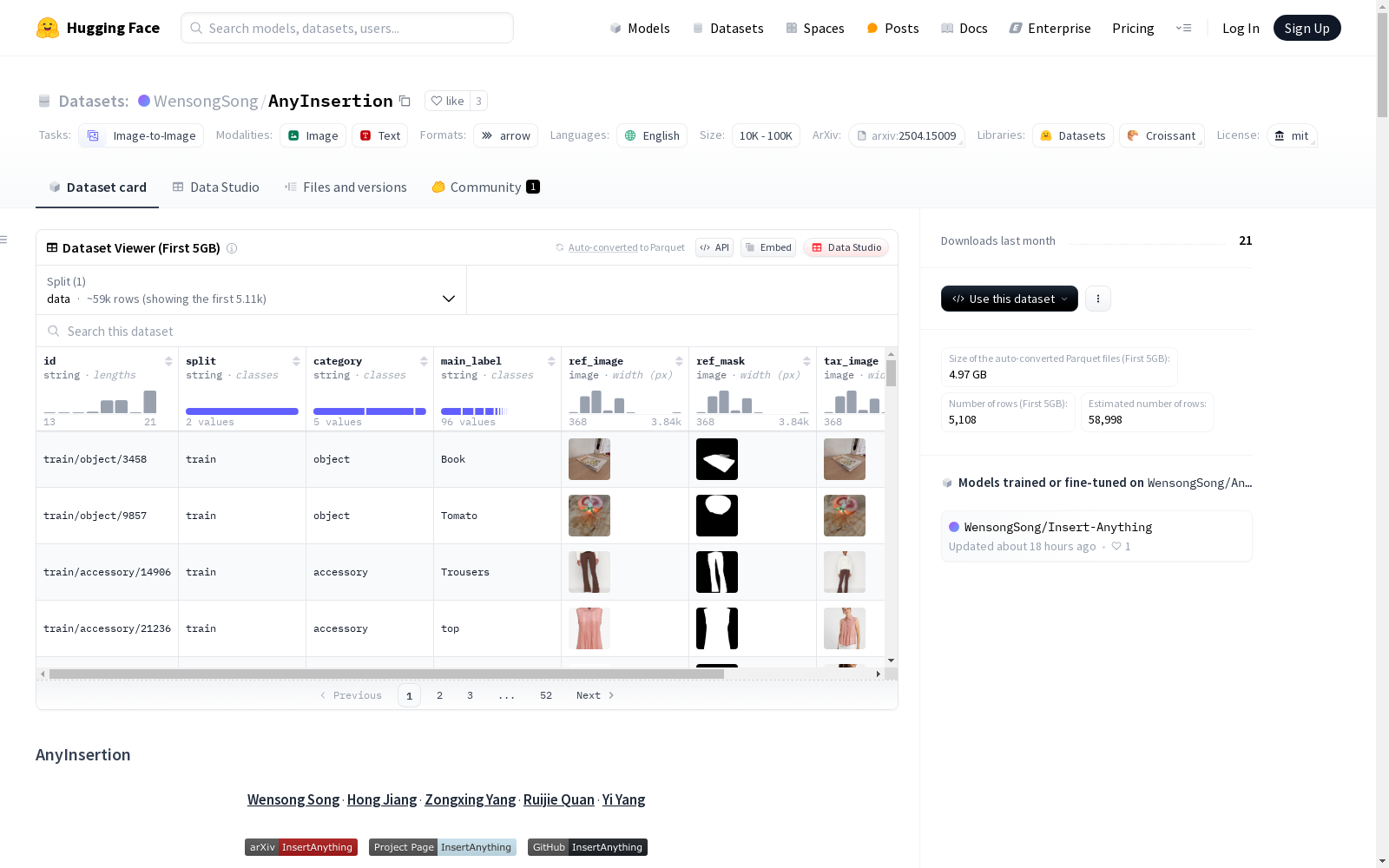
AnyInsertion数据集是基于论文《Insert Anything: Image Insertion via In-Context Editing in DiT》提出的。该数据集包含训练集和测试集,训练集包含159,908个样本,分为两种提示类型:58,188个遮罩提示图像对和101,720个文本提示图像对;测试集包含158个数据对,包括120个遮罩提示对和38个文本提示对。数据集覆盖了多种类别,包括人类主体、日用品、服装、家具和各种物体。
创建时间:
2025-04-23
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,图像编辑与合成技术的进步亟需高质量数据集的支撑。AnyInsertion数据集通过精心设计的采集流程,构建了包含15.9万训练样本和158测试样本的大规模图像对集合。该数据集采用双模态提示机制,包含58,188组掩码-图像对和101,720组文本-图像对,所有样本均经过严格的标注流程和多重质量校验。数据采集覆盖人类主体、日常用品、服装配饰、家具物件等多元场景,通过专业标注团队对参考图像、目标图像及其对应掩码进行像素级标注,确保数据精度满足Diffusion Transformer模型的训练需求。
使用方法
该数据集通过Hugging Face平台提供标准化访问接口,用户安装datasets库后可直接加载Arrow格式数据。典型使用流程包含三个步骤:通过load_dataset函数加载指定版本数据集;按split参数划分训练测试集;通过字典键访问图像和掩码数据。数据集支持灵活的数据筛选操作,用户可按类别标签快速构建子集。图像数据以PIL对象形式返回,可便捷转换为NumPy数组或PyTorch张量。为提升使用效率,建议结合PyTorch的DataLoader实现批量加载,并利用内置filter方法进行特定类别样本的提取,完整的使用示例已在项目GitHub仓库提供。
背景与挑战
背景概述
AnyInsertion数据集由浙江大学、哈佛大学和南洋理工大学的研究团队于2025年联合发布,旨在推动图像插入与编辑领域的研究。该数据集作为论文《Insert Anything: Image Insertion via In-Context Editing in DiT》的核心组成部分,聚焦于通过上下文感知的扩散变换模型实现精准图像元素插入。数据集包含15.9万训练样本和158测试样本,涵盖人物、服饰、家具等多类别对象,通过掩码提示和文本提示两种模态,为生成式模型的场景理解与内容合成提供了丰富的学习素材。其创新性在于将传统图像修复任务拓展至任意元素的语义级插入,显著提升了模型在复杂场景下的编辑能力。
当前挑战
该数据集首要挑战在于解决生成式模型中元素插入的语义一致性问题,要求模型在保持目标图像光照、透视和风格统一的同时,实现插入元素与场景的自然融合。构建过程中的技术难点包括:多源图像对齐需要精确的几何校正与色彩匹配;掩码标注需平衡边缘精度与人工成本;跨类别样本的多样性导致模型需具备强泛化能力。测试集中仅含158个样本,对评估模型的零样本迁移能力提出更高要求,而服饰类样本的纹理细节保留仍是当前未完全解决的学术难题。
常用场景
经典使用场景
在计算机视觉领域,AnyInsertion数据集为图像编辑和生成任务提供了丰富的资源。该数据集通过包含多种类别的图像和对应的掩码,支持基于掩码提示和文本提示的图像插入任务。研究人员可以利用这些数据训练和评估模型在复杂场景中进行精确图像编辑的能力,特别是在需要将特定元素无缝插入到目标图像中的场景。
解决学术问题
AnyInsertion数据集解决了图像生成和编辑领域中的关键问题,特别是在基于上下文的图像插入任务中。通过提供大量高质量的图像和掩码对,该数据集为研究如何在不破坏图像整体一致性的情况下插入新元素提供了实验基础。其多样化的类别覆盖了从日常物品到复杂场景的各种情况,为模型泛化能力的评估提供了可靠的数据支持。
实际应用
在实际应用中,AnyInsertion数据集的能力可以广泛应用于广告设计、电子商务图像处理和增强现实等领域。例如,在电子商务平台中,商家可以利用基于该数据集训练的模型,快速生成展示商品在不同场景下的效果图。这种技术显著提高了产品展示的效率和多样性,同时降低了专业图像处理的成本。
数据集最近研究
最新研究方向
在计算机视觉与生成式人工智能的交叉领域,AnyInsertion数据集为图像编辑技术提供了新的研究范式。该数据集通过mask-prompt和text-prompt两种模态,支持基于Diffusion Transformer(DiT)的上下文感知图像插入研究,这一方向正逐渐成为视觉内容生成领域的前沿热点。其多类别覆盖特性为跨域物体融合、语义一致性保持等关键问题提供了丰富的实验基准,特别是在时尚设计、虚拟场景构建等应用场景展现出重要价值。随着2025年v1版本的发布,该数据集已推动学术界在可控图像生成、细粒度编辑等方向取得突破性进展,为构建下一代智能图像编辑系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


