HEART-BENCH
收藏Hugging Face2026-05-05 更新2026-05-06 收录
下载链接:
https://huggingface.co/datasets/HEART-BENCH/HEART-BENCH
下载链接
链接失效反馈官方服务:
资源简介:
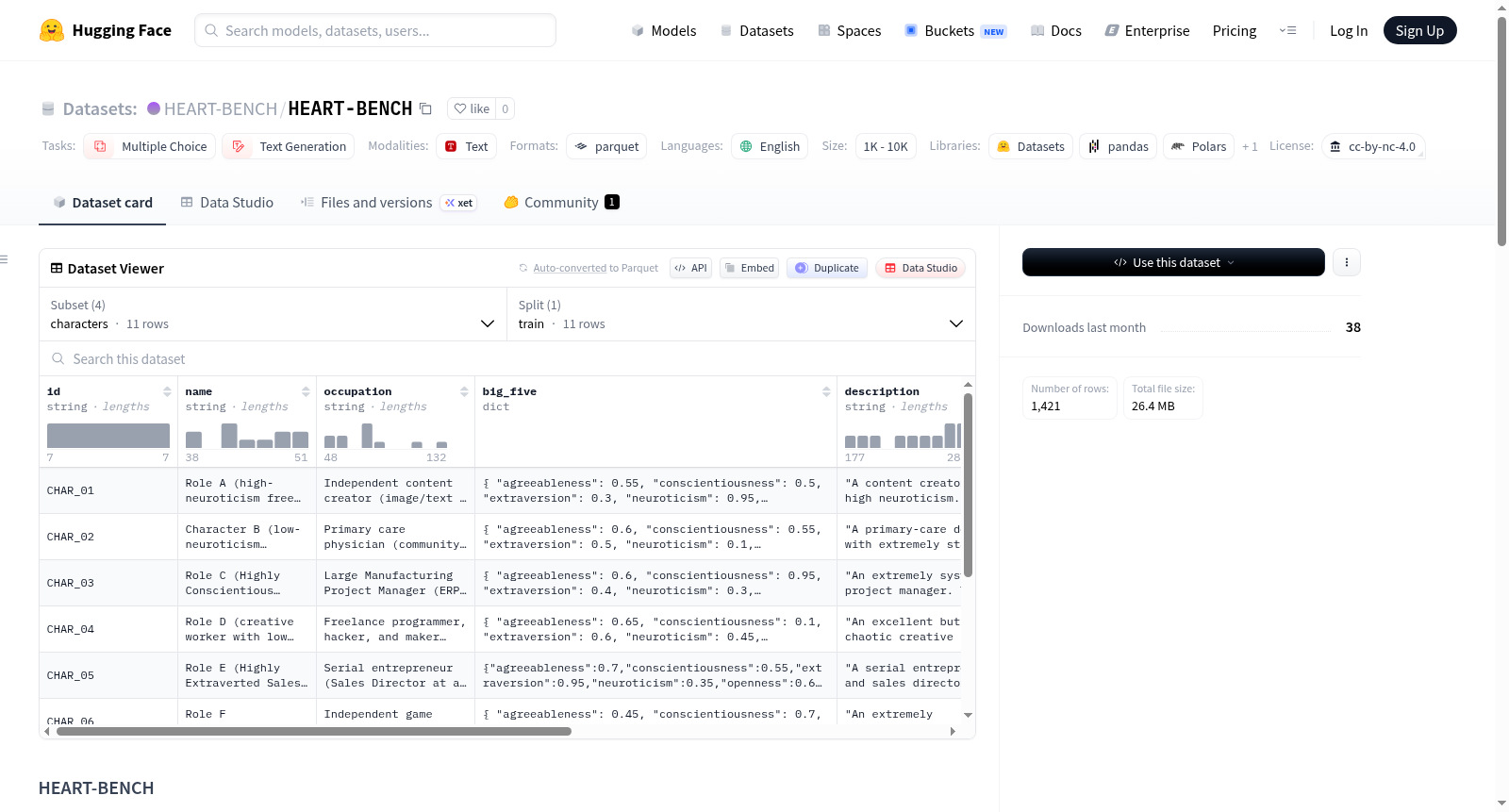
HEART-BENCH 是一个用于评估人类生命周期中类似人类决策的基准数据集,围绕11个具有正交大五人格特征的角色、64个生命阶段场景以及673个带有对应多项选择题的(角色、场景)真实配对构建而成。数据集包含三个主要配置:scenarios(64个跨8个发展阶段的生命场景,每个阶段8个场景)、ground_truth(673个带有注释内心意识和最终决策的(角色、场景)配对)和mcq(从真实配对中提取的673个多项选择题,干扰项来自其他角色的决策)。每个配置都有详细的字段说明,包括场景ID、发展阶段、年龄范围、描述文本、内心意识结构、最终决策等。数据集适用于多项选择题生成和文本生成任务,语言为英语,规模在1K到10K之间。
HEART-BENCH is a benchmark dataset for evaluating human-like decision-making across the human lifespan, constructed around 11 characters with orthogonal Big Five personality traits, 64 life-stage scenarios, and 673 real (character, scenario) pairs with corresponding multiple-choice questions. The dataset includes three main configurations: scenarios (64 life scenarios across 8 developmental stages, 8 scenarios per stage), ground_truth (673 (character, scenario) pairs annotated with inner thoughts and final decisions), and mcq (673 multiple-choice questions extracted from real pairs, with distractors derived from other characters decisions). Each configuration has detailed field descriptions, including scenario ID, developmental stage, age range, description text, inner thought structure, final decision, etc. The dataset is suitable for multiple-choice question generation and text generation tasks, in English, with a scale between 1K to 10K.
创建时间:
2026-05-04
原始信息汇总
数据集概述:HEART-BENCH
HEART-BENCH 是一个用于评估跨生命周期人类类似决策能力的基准数据集。它围绕11个具有正交大五人格特征的虚拟角色、64个生命阶段场景,以及673个带有对应多项选择题的(角色,场景)真实答案对构建。
数据集配置
该数据集包含以下三个可加载的配置:
| 配置名 | 行数 | 描述 |
|---|---|---|
scenarios |
64 | 涵盖8个发展阶段(从学龄期到进入中年期)的生命阶段场景,每个阶段包含8个场景。 |
ground_truth |
673 | (角色,场景)配对,包含标注的内在意识与最终决策。 |
mcq |
673 | 基于真实答案派生的多项选择题,干扰项来自其他角色的决策。 |
注意:
characters配置(11个角色档案、大五人格特质、每个角色约1000个情景记忆)正在重新上传中,将在模式清理后恢复。
加载方式
使用Hugging Face的datasets库加载数据集:
python from datasets import load_dataset
scenarios = load_dataset("HEART-BENCH/HEART-BENCH", "scenarios", split="train") ground_truth = load_dataset("HEART-BENCH/HEART-BENCH", "ground_truth", split="train") mcq = load_dataset("HEART-BENCH/HEART-BENCH", "mcq", split="train")
数据结构
scenarios 配置
id(str):场景IDstage(str):发展阶段age_range(str):年龄范围age(int):具体年龄name(str):场景名称category(str):场景类别intensity(str):场景强度description_for_agent(str):给智能体的场景描述context_text(str):背景文本trigger_event(str):触发事件setting(struct):场景设置
ground_truth 配置
character_id(str):角色IDscenario_id(str):场景IDstage(str):发展阶段inner_consciousness(struct):内在意识,包含:summary:摘要core_reasoning:核心推理emotional_tone:情感基调value_orientation:价值取向
final_decision(str):最终决策
mcq 配置
question_id(str):问题IDcharacter_id(str):角色IDscenario_id(str):场景IDstage(str):发展阶段correct_answer(str):正确答案options(list of structs):选项列表,每个选项包含:label:选项标签content:选项内容is_correct:是否为正确答案is_generated:是否为生成的选项source_character:来源角色
配置关联方式
mcq和ground_truth配置中的每一行通过(character_id, scenario_id)进行关联。characters配置(即将恢复)通过characters.id提供每个角色的档案与记忆数据,可与其他配置进行连接。
搜集汇总
数据集介绍
构建方式
HEART-BENCH数据集以人类生命周期中决策过程的仿真为核心,系统性地构建了基于大五人格理论的11个正交性格角色,并设计了涵盖从学龄至中年初期的8个发展阶段的64个生活情境场景。每个场景均配有详尽的环境描述、触发事件与背景文本。研究人员通过将特定角色与场景配对,形成了673组包含内在意识(包括总结、核心推理、情感基调与价值取向)及最终决策的真值数据,并基于这些真值生成了多项选择题,干扰项则来源于其他角色在相同场景下的决策。
特点
该数据集的显著特色在于其人格心理学与生命周期理论的深度融合,通过对八个人生阶段的细致划分,精准捕捉了人类决策在时间维度上的演变规律。每个角色的构建不仅依赖大五人格特质的正交分布,还储备了约1000个情境记忆,从而在模拟人类决策时具备高度一致性和心理真实性。此外,数据集提供多模态数据配置,涵盖场景、真值与选择题,并支持通过角色-场景唯一标识符实现数据间的关联与扩展。
使用方法
研究人员可通过HuggingFace Datasets库便捷加载该数据集的三个核心配置:scenarios用于获取64个生活场景描述,ground_truth提供角色-场景配对的完整认知与决策真值,mcq则包含基于真值衍生的多项选择题。各配置间通过character_id与scenario_id字段进行关联,便于用户构建复杂的人性化决策模型评估流程。待人物角色配置恢复后,还可进一步整合每位角色的大五人格档案与情节记忆数据进行综合分析。
背景与挑战
背景概述
HEART-BENCH是一个专为评估类人决策能力而设计的数据集,由研究团队基于大五人格理论构建,创建时间可追溯至2023年前后。该数据集通过定义11个具有正交大五人格特征的角色,并精心设计64个跨生命周期的生活场景,形成了673个包含真实决策与内在意识的基准样本。其核心研究问题在于探索人工智能系统能否在不同年龄阶段模拟人类决策过程,从而推动情感计算、认知建模与人机交互领域的发展。由于其独特的视角和精细的标注,HEART-BENCH为理解人类决策的复杂性提供了标准化的评估工具,对相关领域具有重要的推动意义。
当前挑战
HEART-BENCH所面临的挑战首先在于解决如何将抽象的人格特质与复杂社会情境中的决策行为进行量化建模的领域难题。传统数据集多聚焦于静态分类任务,而此处需捕捉生命历程中决策的动态性与情境依赖性,这对模型的语义理解和常识推理提出了极高要求。其次,在构建过程中,确保角色人格的一致性、场景的代表性以及内在意识与最终决策的逻辑连贯性极为困难。大规模合成记忆数据的生成与质量验证、多轮迭代标注的标准化管理,以及对抗生成干扰项以避免测试污染,均为实施中的关键技术瓶颈。
常用场景
经典使用场景
HEART-BENCH数据集的核心用途在于评估和提升人工智能系统在人类生命周期决策中的类人推理能力。该基准围绕11个拥有正交大五人格特征的角色、64个覆盖从学龄到中年八个发展阶段的生活场景,以及673个带有内省意识与最终决策的(角色,场景)真实配对数据构建而成。研究者通常利用该数据集的多选题配置来检验模型能否根据人格特质与生命阶段情境,准确预测个体的内心独白与行为选择,从而衡量智能体在模拟人类认知和社会情感推理方面的表现。
衍生相关工作
围绕HEART-BENCH数据集已衍生出若干具有代表性的研究工作。基于其多选题配置,研究者开发了人格引导的推理范式,通过注入角色的大五人格特征向量来增强预训练语言模型的类人决策准确性。另一方向的工作探索了意识模拟框架,利用数据集中内省意识的结构化字段(包括核心推理、情感基调与价值取向)训练模型生成符合特定人格的深度心理表征。此外,有学者将该基准扩展到跨文化情境验证,通过调整场景描述中的社会规范参数来检验模型在不同文化背景下预测人类决策的鲁棒性。
数据集最近研究
最新研究方向
HEART-BENCH作为一项聚焦于人类生命周期决策模拟的基准数据集,正引领认知科学与人工智能交叉领域的前沿探索。其基于大五人格框架构建的11个正交角色与64个涵盖八个发展阶段的场景,为评估模型在复杂社会情境中的类人推理能力提供了标准化测试平台。当前研究热点集中于利用该数据集的673组真相标注与多选题配置,推动大语言模型在价值取向、情绪推断及动态决策等维度的突破,尤其关注模型是否具备随年龄阶段变化的适应性认知机制。这一工作不仅深化了对人工智能社会智能的评估范式,也为发展心理学中的终身决策理论提供了可量化的计算实验场景,其开源属性更促进了多学科协作下基准测试的公平性与可复现性。
以上内容由遇见数据集搜集并总结生成


