VoxEval
收藏arXiv2025-01-09 更新2025-01-14 收录
下载链接:
http://arxiv.org/abs/2501.04962v1
下载链接
链接失效反馈官方服务:
资源简介:
VoxEval是一个专门设计用于评估端到端语音语言模型(SLMs)知识理解能力的语音问答基准数据集。该数据集由香港中文大学、腾讯光速工作室和新加坡国立大学的研究团队创建,旨在通过纯语音交互测试模型在不同音频条件下的鲁棒性。数据集基于MMLU文本数据集构建,通过OpenAI的TTS API将文本问题转换为语音格式,并引入了多种音频输入条件(如不同说话者、语速、音调变化等)以模拟真实世界的对话场景。VoxEval特别关注数学问题等复杂主题的语音评估,填补了现有评估方法的空白。该数据集的应用领域包括语音交互模型的开发与优化,旨在提升模型在真实环境中的知识理解与对话能力。
VoxEval is a speech question-answering benchmark dataset specifically designed to evaluate the knowledge comprehension capabilities of end-to-end speech language models (SLMs). It was developed by research teams from The Chinese University of Hong Kong, Tencent LightSpeed Studios, and the National University of Singapore, with the goal of testing the robustness of models under diverse audio conditions via pure speech interaction. Constructed based on the MMLU text dataset, VoxEval converts text questions into speech format using OpenAI's TTS API, and introduces multiple audio input conditions such as different speakers, speech rates and pitch variations to simulate real-world conversational scenarios. VoxEval particularly focuses on speech evaluation for complex topics including mathematical problems, filling a critical gap in existing evaluation methodologies. Its application fields cover the development and optimization of speech interaction models, aiming to improve the knowledge comprehension and conversational abilities of models in real-world environments.
提供机构:
香港中文大学, 腾讯光速工作室, 新加坡国立大学
创建时间:
2025-01-09
搜集汇总
数据集介绍
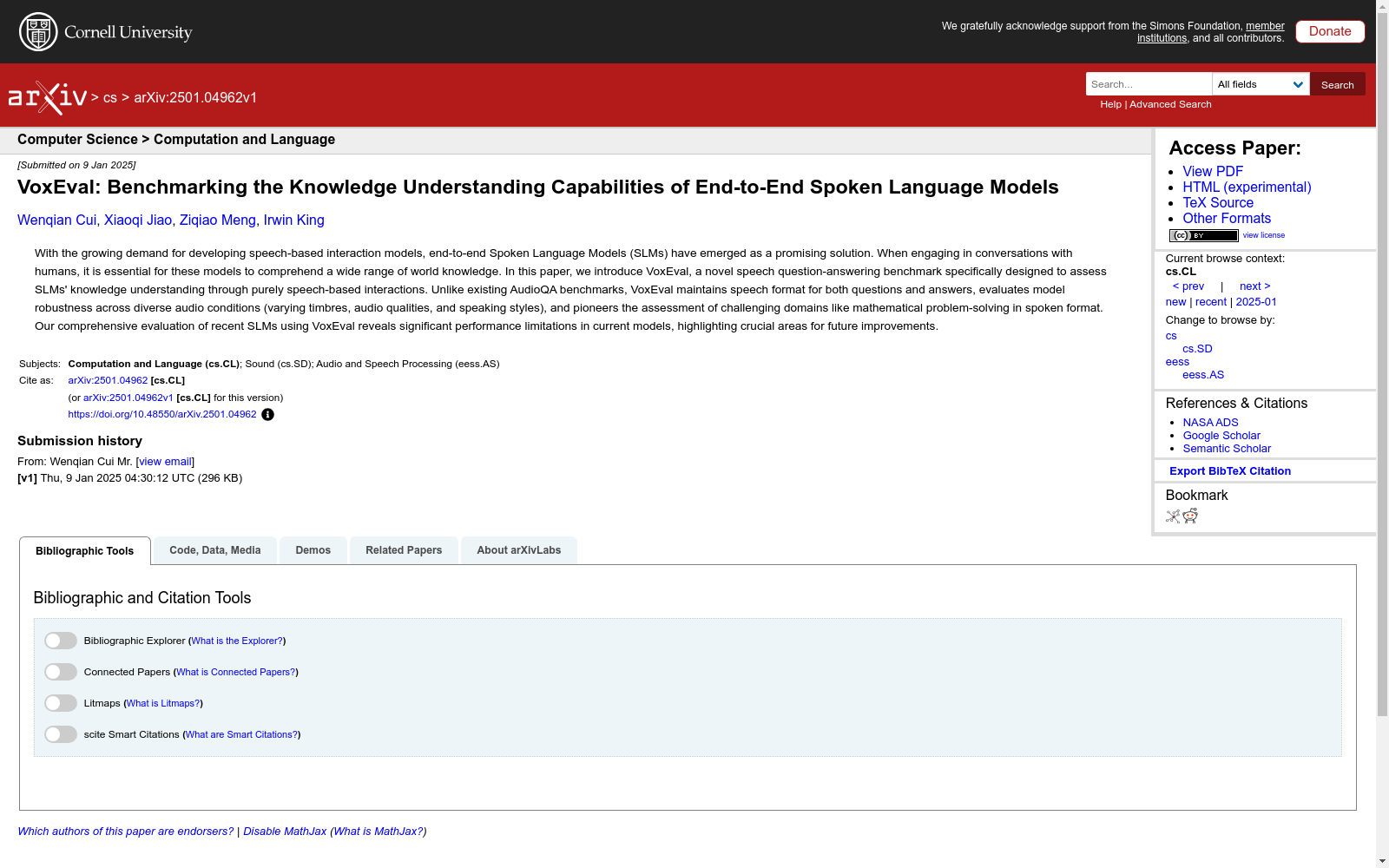
构建方式
VoxEval数据集的构建基于MMLU(Massive Multitask Language Understanding)数据集,通过将MMLU中的文本问题转换为语音格式,使用OpenAI的文本到语音(TTS)API生成音频。MMLU数据集涵盖了广泛的学科领域,包括STEM、社会科学和人文学科,确保了VoxEval在知识理解评估上的全面性。为了模拟真实世界的语音交互场景,VoxEval还引入了多种输入音频条件,如不同说话者、语速、音高变化以及背景噪声等,以评估模型在不同音频条件下的鲁棒性。
特点
VoxEval数据集的特点在于其完全基于语音的问答形式,区别于传统的文本或音频-文本混合问答任务。该数据集不仅涵盖了广泛的学科知识,还特别关注了数学问题的语音表达,填补了现有评估方法在语音格式下数学推理能力评估的空白。此外,VoxEval通过引入多种音频条件(如不同说话者、语速、音高变化等),确保了模型在复杂音频环境下的鲁棒性评估。这些特点使得VoxEval成为一个极具挑战性的语音语言模型评估基准。
使用方法
VoxEval数据集的使用方法主要包括通过语音输入问题并接收语音输出的问答形式。研究人员可以使用该数据集评估端到端语音语言模型(SLMs)在纯语音交互场景下的知识理解能力。具体而言,用户可以通过不同的音频条件(如不同说话者、语速、音高等)输入问题,并观察模型在不同条件下的表现。此外,VoxEval还支持对复杂主题(如数学问题)的评估,帮助研究人员识别模型在语音格式下的推理能力短板。通过系统化的评估,VoxEval为语音语言模型的改进提供了重要的参考依据。
背景与挑战
背景概述
VoxEval是由香港中文大学、新加坡国立大学和腾讯光速工作室的研究团队于2024年提出的一个语音问答基准测试数据集,旨在评估端到端语音语言模型(SLMs)在纯语音交互中的知识理解能力。随着语音交互模型的需求日益增长,SLMs作为一种直接参与语音对话的模型,逐渐成为研究热点。VoxEval的独特之处在于其完全基于语音格式的问答设计,涵盖了多样化的音频条件(如音色、音频质量和说话风格的变化),并首次引入了数学问题求解等复杂领域的评估。该数据集的构建基于MMLU(Massive Multitask Language Understanding)数据集,通过将文本问题转化为语音格式,进一步推动了语音语言模型在真实对话场景中的应用。VoxEval的发布为SLMs的研究提供了重要的评估工具,揭示了当前模型在知识理解和语音交互中的局限性。
当前挑战
VoxEval数据集在构建和应用过程中面临多重挑战。首先,在领域问题方面,VoxEval旨在解决语音语言模型在知识理解中的核心问题,尤其是在复杂领域(如数学问题求解)中的表现。然而,当前模型在处理语音格式的数学问题时表现不佳,主要因为数学表达式在语音中的表达方式与文本存在显著差异,导致模型难以准确理解和生成答案。其次,在数据集构建过程中,研究人员需要将文本问题转化为语音格式,并确保生成的语音数据在多样化音频条件下保持一致性。这一过程涉及复杂的语音合成技术,尤其是在处理数学表达式时,需要将阿拉伯数字、运算符和单位等转换为自然语言表达,这对语音合成系统的准确性提出了极高要求。此外,VoxEval还要求模型在不同音色、音频质量和说话风格下保持鲁棒性,这对模型的泛化能力提出了严峻挑战。
常用场景
经典使用场景
VoxEval数据集主要用于评估端到端语音语言模型(SLMs)在纯语音交互中的知识理解能力。其经典使用场景包括通过语音问答任务测试模型在不同音频条件下的鲁棒性,涵盖多种音色、音频质量和说话风格。此外,VoxEval还首次引入了对数学问题求解等复杂领域的语音格式评估,为SLMs在真实对话场景中的表现提供了全面的测试平台。
解决学术问题
VoxEval解决了当前语音语言模型在知识理解能力评估中的关键问题。传统的AudioQA基准测试通常依赖于文本格式的问答对,无法全面反映模型在纯语音交互中的表现。VoxEval通过保持问题和答案的语音格式,填补了这一空白,并进一步评估了模型在不同音频条件下的鲁棒性。此外,VoxEval还首次将数学问题求解等复杂领域纳入评估范围,揭示了当前模型在语音格式下处理复杂知识的局限性,为未来的研究指明了方向。
衍生相关工作
VoxEval的推出催生了一系列相关研究工作,尤其是在语音语言模型的评估和优化领域。基于VoxEval的评估结果,研究人员提出了多种改进模型鲁棒性和知识理解能力的方法。例如,一些研究专注于提升模型在复杂音频条件下的表现,而另一些研究则致力于改进模型在语音格式下处理数学问题等复杂知识的能力。此外,VoxEval还为其他语音问答基准测试的设计提供了参考,推动了语音语言模型评估方法的多样化发展。
以上内容由遇见数据集搜集并总结生成


