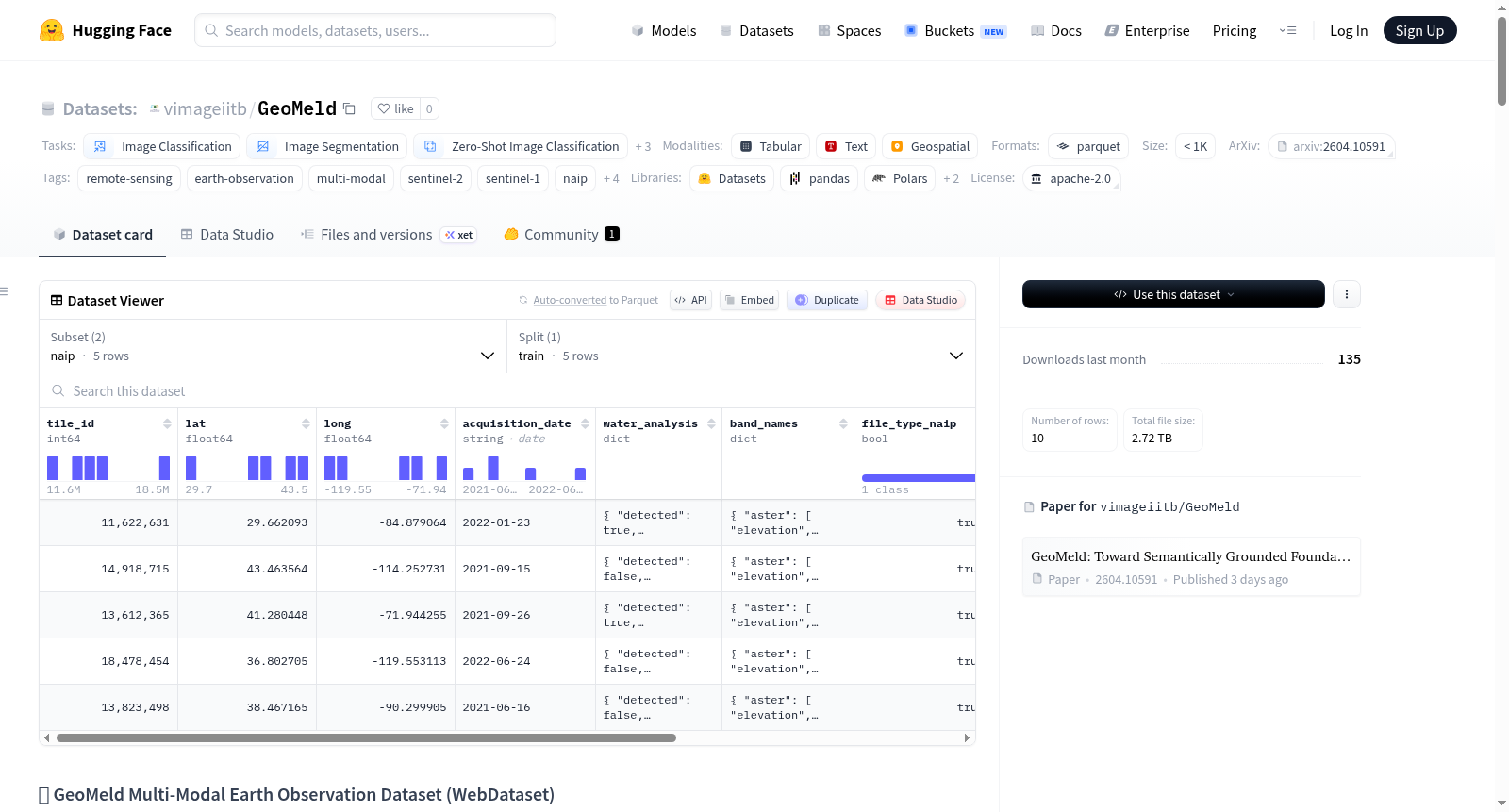
GeoMeld
收藏GeoMeld 多模态地球观测数据集概述
数据集基本信息
- 数据集名称: GeoMeld Multi-Modal Earth Observation Dataset (WebDataset)
- 发布机构/作者: Maram Hasan 等
- 关联论文: GeoMeld: Toward Semantically Grounded Foundation Models for Remote Sensing (CVPR Workshop on Foundation and Large Vision Models in Remote Sensing (MORSE), 2026)
- 论文链接: https://arxiv.org/abs/2604.10591
- 代码仓库: https://github.com/MaramAI/GeoMeld/
- 许可协议: Apache-2.0
- 任务类别: 图像分类、图像分割、零样本图像分类、文本到图像、图像到文本、特征提取
- 标签: 遥感、地球观测、多模态、sentinel-2、sentinel-1、naip、土地覆盖、图像描述、webdataset、hdf5
数据集规模与构成
- 样本数量: 约 250 万个空间对齐的样本。
- 数据总量: 约 50GB(以 WebDataset
.tar分片形式存储)。 - 数据子集:
- NAIP 子集: 包含高分辨率 NAIP 影像。
- 非 NAIP 子集: 仅包含中分辨率数据。
- 数据格式: 数据被归档为 WebDataset (
.tar) 分片,每个分片包含.h5(HDF5) 文件。
数据内容与模态
每个样本是一个跨多分辨率空间对齐的多模态元组。
空间分辨率与数据源
-
高分辨率 (~1米):
- 数据源: 美国国家农业影像计划 (NAIP)。
- 地面采样距离 (GSD): 1米。
- 影像尺寸: 1280 × 1280 像素。
- 覆盖范围: 美国本土。
- 波段: RGB(红、绿、蓝)。
-
中分辨率 (10米,标准化网格):
- 网格尺寸: 128 × 128 像素。
- 包含模态:
- Sentinel-2 (S2): 多光谱光学影像。
- Sentinel-1 (S1): SAR 后向散射。
- ASTER-DEM: 高程和地形坡度。
- 冠层高度。
- 土地覆盖产品: Dynamic World, ESA WorldCover。
数据模态详情(按 HDF5 文件键名)
| 模态键名 | NAIP 子集形状 (_n.tar) |
非 NAIP 子集形状 | 数据类型 | 描述 |
|---|---|---|---|---|
naip |
(3, 1280, 1280) | — | uint16 |
NAIP RGB 影像(1米 GSD) |
sentinel2 |
(9, 128, 128) | (12, 128, 128) | float32 |
Sentinel-2 多光谱影像。非 NAIP 子集含 B1–B12 波段;NAIP 子集含 B1–B12(除 B2–B4)波段。 |
sentinel1 |
(8, 128, 128) | (8, 128, 128) | float32 |
Sentinel-1 SAR 后向散射(VV, VH, HH, HV 的升轨和降轨) |
aster |
(2, 128, 128) | (2, 128, 128) | float32 |
ASTER 高程和坡度 |
canopy_height |
(2, 128, 128) | (2, 128, 128) | float32 |
冠层高度及其标准差 |
标签与元数据
| 键名 | 形状 | 数据类型 | 描述 |
|---|---|---|---|
esa_worldcover |
(1, 128, 128) | uint8 |
ESA WorldCover 土地覆盖标签 |
dynamic_world |
(1, 128, 128) | uint8 |
Dynamic World 土地覆盖标签 |
metadata |
JSON | — | 地理和上下文属性 |
元数据字段示例
metadata 字段为 JSON 格式,包含以下示例属性:
json
{
"tile_id": 1232154454,
"lat": 71.5545,
"long": 71.0397,
"acquisition_date": "2020-09-24",
"terrain_class": "Flat",
"file_type_naip": true,
"osm_tags": {
"building": "yes",
"highway": "residential"
},
"water_analysis": {
"detected": true,
"percentage": 4.98
}
}
其中,file_type_naip 字段用于标识样本是否属于 NAIP 子集。
数据集特点与用途
- 核心特点: 大规模、多模态、空间对齐、包含语义接地描述。
- 主要用途: 支持多模态表示学习、视觉-语言建模、地球观测中的跨传感器泛化。
- 技术优势: 采用 WebDataset 格式,支持从 Hugging Face Hub 直接流式读取,无需下载全部数据,便于大规模训练。
文件命名约定
- 高分辨率分片 (NAIP): 文件名包含后缀
_n(例如:geomeld-00004_n.tar)。 - 中分辨率分片 (非 NAIP): 文件名不包含
_n后缀(例如:geomeld-00008.tar)。
引用格式
bibtex @misc{hasan2026geomeldsemanticallygroundedfoundation, title={GeoMeld: Toward Semantically Grounded Foundation Models for Remote Sensing}, author={Maram Hasan and Md Aminur Hossain and Savitra Roy and Souparna Bhowmik and Ayush V. Patel and Mainak Singha and Subhasis Chaudhuri and Muhammad Haris Khan and Biplab Banerjee}, year={2026}, eprint={2604.10591}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2604.10591}, }