katanaml-org/invoices-donut-data-v1
收藏Hugging Face2023-05-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/katanaml-org/invoices-donut-data-v1
下载链接
链接失效反馈官方服务:
资源简介:
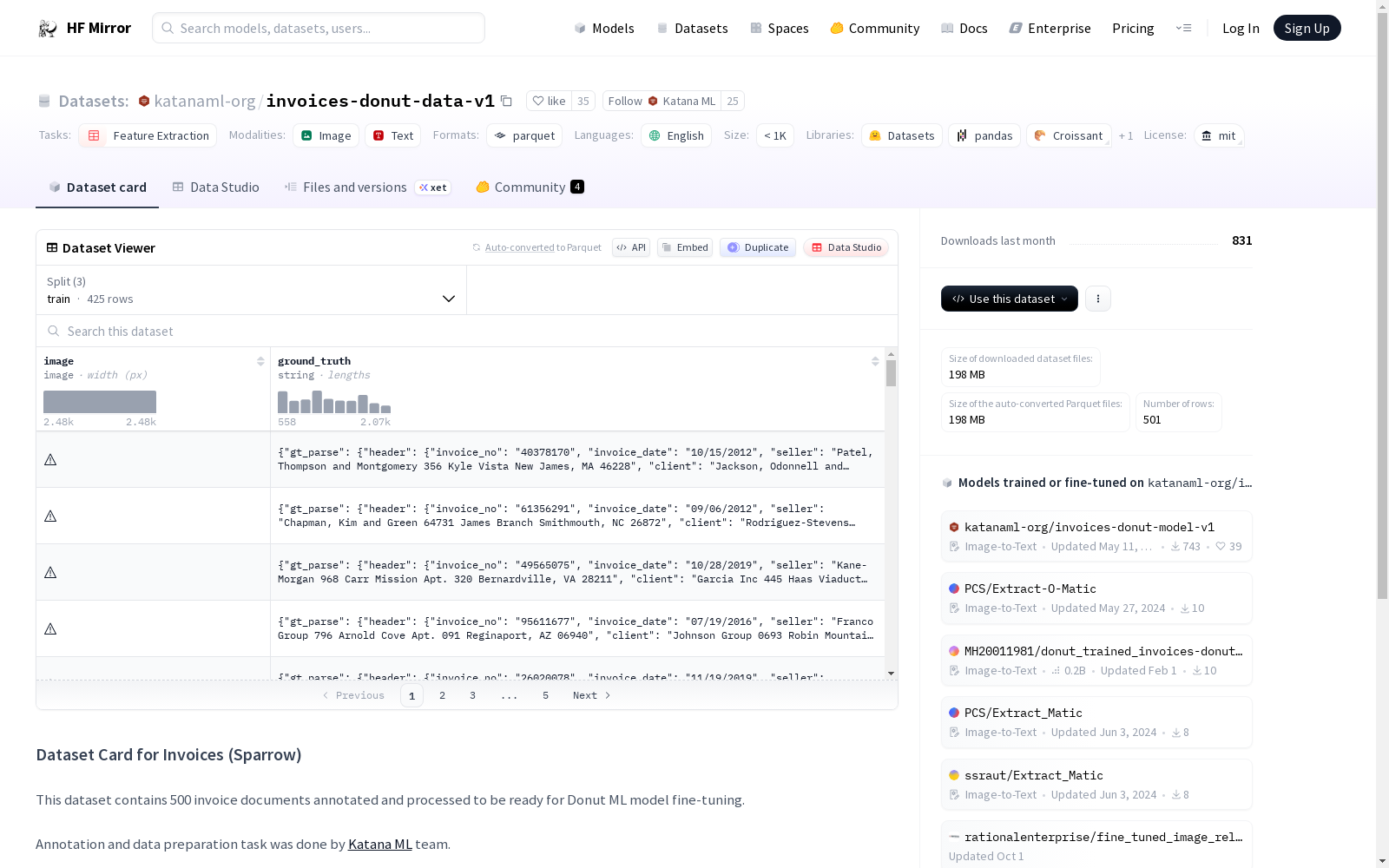
该数据集包含500份发票文档,这些文档已经过注释和处理,准备用于Donut ML模型的微调。注释和数据准备任务由Katana ML团队完成。Sparrow是Katana ML的开源数据提取解决方案。原始数据集信息可在Mendeley Data上找到。
This dataset comprises 500 invoice documents that have been annotated and processed, and is prepared for fine-tuning of the Donut ML model. The annotation and data preparation tasks were completed by the Katana ML team. Sparrow is an open-source data extraction solution developed by Katana ML. Information about the original dataset is available on Mendeley Data.
提供机构:
katanaml-org
原始信息汇总
数据集概述
数据集信息
- 特征:
image: 图像数据ground_truth: 字符串数据
- 分割:
train: 234024421字节, 425个样本test: 14512665字节, 26个样本validation: 27661738字节, 50个样本
- 下载大小: 197512750字节
- 数据集大小: 276198824字节
- 许可证: MIT
- 任务类别: 特征提取
- 语言: 英语
- 名称: Sparrow Invoice Dataset
- 大小类别: n<1K
数据集描述
- 包含500份已标注并处理好的发票文档,适用于Donut ML模型的微调。
搜集汇总
数据集介绍
构建方式
在文档智能领域,高质量标注数据是训练高效模型的基础。该数据集由Katana ML团队精心构建,基于Marek Kozłowski与Paweł Weichbroth于2021年发布的电子发票原始样本,经过专业标注与预处理,转化为适用于Donut模型微调的格式。构建过程涵盖图像与文本对的整理,确保数据的一致性与可用性,最终形成包含500份发票文档的标准化集合,为结构化信息提取研究提供了可靠资源。
特点
本数据集聚焦于发票文档的自动化处理,其核心特点在于专为Donut模型设计,具备图像与文本对的结构化特征。数据规模适中,涵盖训练、验证与测试三个标准划分,共计501个样本,确保了模型评估的严谨性。所有文档均以英文呈现,标注质量经过专业团队校验,支持特征提取任务,为文档理解与关键信息抽取提供了精准的基准数据。
使用方法
在文档信息提取任务中,该数据集可直接用于微调基于Transformer的Donut模型。使用者可通过加载图像与对应的ground_truth文本,训练模型学习从发票图像中识别并生成结构化文本。数据集已按标准比例分割,便于进行模型训练、验证与性能测试。借助HuggingFace平台,研究人员可便捷访问数据,加速文档智能领域的实验与开发进程。
背景与挑战
背景概述
在文档智能领域,电子发票的自动化信息提取一直是提升企业运营效率的关键技术。katanaml-org/invoices-donut-data-v1数据集由Katana ML团队于2021年构建,基于Marek Kozłowski和Paweł Weichbroth发布的原始电子发票样本。该数据集旨在为Donut模型提供精细调优的标注数据,核心研究问题聚焦于从复杂发票文档中准确提取结构化信息,从而推动光学字符识别与自然语言处理技术的融合应用,对金融科技与自动化流程管理领域产生了显著影响。
当前挑战
该数据集致力于解决电子发票信息提取中的多模态理解挑战,包括处理多样化的发票布局、模糊的文本质量以及跨语言语义解析等难题。在构建过程中,团队面临标注一致性与数据隐私保护的考验,需在有限样本规模下确保注释的精确度,同时平衡开源数据与商业敏感性之间的冲突,这些因素共同构成了数据集实用化部署的核心障碍。
常用场景
经典使用场景
在文档智能领域,该数据集为发票文档的结构化信息提取提供了标准化训练资源。其经典使用场景在于支持基于深度学习的端到端模型,如Donut(Document Understanding Transformer),进行细粒度微调,以自动识别发票中的关键字段,包括供应商名称、日期、金额和商品条目等。通过结合图像与文本标注,模型能够直接从扫描或数字发票图像中解析语义内容,显著提升了文档处理的自动化水平与准确性。
实际应用
在实际应用中,该数据集支撑了企业财务自动化、供应链管理和审计流程的优化。例如,金融机构和物流公司可基于训练模型批量处理发票,自动录入数据至ERP系统,减少人工干预并降低错误率。此外,它还能赋能税务申报、费用报销等场景,实现实时文档分析与合规检查,提升运营效率并降低成本,体现了人工智能在传统行业数字化转型中的关键价值。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作,主要包括基于Donut架构的改进模型,如集成多语言支持或增强布局理解的变体。同时,社区也探索了结合预训练视觉Transformer与序列生成技术的方法,以提升对复杂发票格式的鲁棒性。这些工作不仅扩展了数据集的适用边界,还推动了开源工具如Sparrow的发展,形成了从数据到部署的完整生态系统,持续促进文档智能领域的实践与创新。
以上内容由遇见数据集搜集并总结生成


