【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
PandaVT/datatager_legal_split_cases
收藏Hugging Face2024-06-05 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/PandaVT/datatager_legal_split_cases
下载链接
链接失效反馈官方服务:
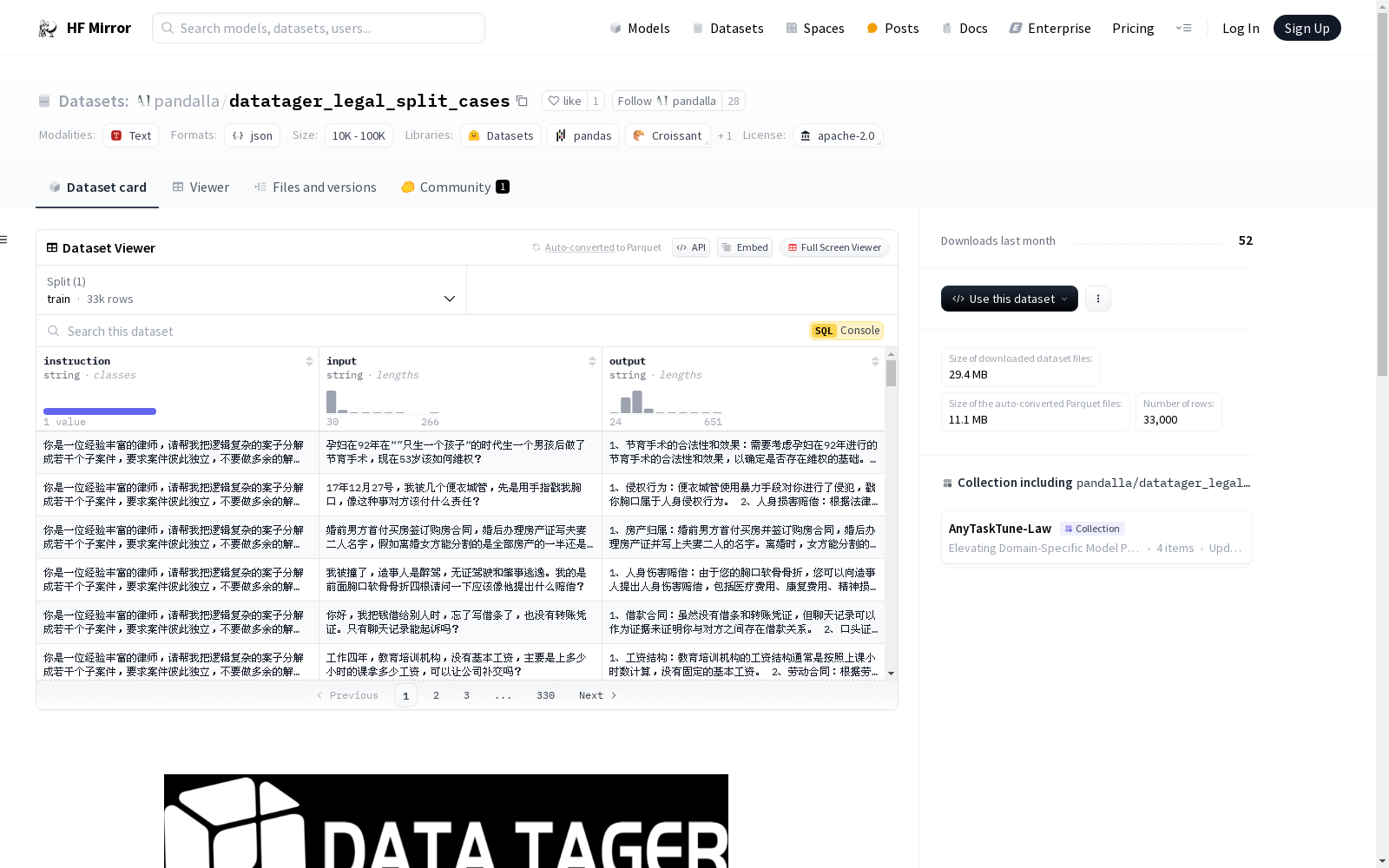
资源简介:
Legal Split数据集是由DataTager团队组织的一个集合,旨在提高分析复杂案件的效率。该数据集将复杂案件分解为多个相对独立的子案件,每个子案件聚焦于特定的法律问题或争议。这种方法有助于精确识别和分析每个子案件中的具体法律问题,从而提高法律从业者处理案件的效率。该数据集是开发法律AI工具的重要资源,可以增强处理涉及多个法律问题的复杂案件的效率。AI系统可以利用该数据集帮助律师和法官彻底梳理不同子案件中的法律问题、相关证据和其他关键信息,使法律从业者能够更快地做出更明智的决策。它还可以用于教育目的,培训法学院学生和初级律师识别和处理复杂案件中的交织子案件,增强他们的案件分析和法律研究能力。
The Legal Split Dataset is a curated collection organized by the DataTager team, aimed at enhancing the efficiency of complex legal case analysis. This dataset decomposes complex legal cases into multiple relatively independent sub-cases, each focusing on a specific legal issue or dispute. This approach enables the accurate identification and analysis of specific legal issues within each sub-case, thereby improving the efficiency of legal practitioners in handling cases. As a critical resource for developing legal AI tools, this dataset can boost the efficiency of addressing complex cases involving multiple legal issues. AI systems can leverage this dataset to help lawyers and judges thoroughly sort out legal issues, relevant evidence and other key information across different sub-cases, enabling legal practitioners to make more informed decisions at a faster pace. It can also be used for educational purposes, training law students and junior lawyers to identify and handle intertwined sub-cases in complex cases, and strengthening their capabilities in case analysis and legal research.
提供机构:
PandaVT
原始信息汇总
Legal Split Cases Dataset
描述
Legal Split 数据集是由 DataTager 团队整理的,旨在提高分析复杂案件的效率。该数据集将复杂案件分解为几个相对独立的子案件,每个子案件聚焦于特定的法律问题或争议。这种方法有助于精确识别和分析每个子案件中的特定法律问题,从而提高法律从业者处理案件的效率。
用途
该数据集是开发法律 AI 工具的重要资源,可以提高处理涉及多个法律问题的复杂案件在法律咨询中的效率。AI 系统可以使用此数据集帮助律师和法官彻底梳理不同子案件中涉及的法律问题、相关证据和其他关键信息,使法律从业者能够更快地做出更明智的决策。它还可以用于教育目的,培训法学生和初级律师识别和处理复杂案件中的交织子案件,增强他们的案件分析和法律研究能力。
引用
请在您的工作中按以下方式引用此数据集:
@misc{ Extract Medical Information Dataset, author = {DataTager}, title = {Extract Medical Information Dataset}, year = {2024}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {https://github.com/PandaVT/DataTager} }
搜集汇总
数据集介绍
构建方式
在法律领域的深度分析需求驱动下,DataTager团队精心构建了Legal Split Cases数据集。该数据集通过将复杂的法律案件分解为多个相对独立的子案件,每个子案件聚焦于特定的法律问题或争议点。这种构建方式旨在通过精确识别和分析每个子案件中的具体法律问题,从而提升法律从业者在处理案件时的效率。
特点
Legal Split Cases数据集的显著特点在于其结构化的案件分解方法,使得复杂的法律案件得以简化为多个易于处理的子案件。这种分解不仅有助于法律从业者快速定位关键法律问题,还为法律AI工具的开发提供了丰富的数据资源。此外,该数据集的开放性使得其能够广泛应用于法律教育、法律研究和法律咨询等多个领域。
使用方法
Legal Split Cases数据集可作为法律AI工具开发的重要资源,帮助律师和法官在处理涉及多个法律问题的复杂案件时,快速梳理相关法律问题、证据和其他关键信息。此外,该数据集还可用于法律教育,训练法学生和初级律师识别和处理复杂案件中的交织子案件,提升其案件分析和法律研究能力。
背景与挑战
背景概述
在法律领域,处理复杂案件往往涉及多个相互关联的法律问题,这不仅增加了法律从业者的负担,也影响了案件处理的效率。为了应对这一挑战,DataTager团队于2024年创建了Legal Split Cases Dataset。该数据集通过将复杂案件分解为多个相对独立的子案件,每个子案件聚焦于特定的法律问题或争议,从而帮助法律从业者更精确地识别和分析每个子案件中的法律问题。这一创新方法不仅提升了案件处理的效率,还为法律AI工具的开发提供了重要资源,推动了法律领域的技术进步。
当前挑战
尽管Legal Split Cases Dataset在提升法律案件处理效率方面展现了巨大潜力,但其构建过程中仍面临诸多挑战。首先,如何准确地将复杂案件分解为独立的子案件,确保每个子案件中的法律问题清晰且不重叠,是一个技术难题。其次,数据集的构建需要大量的法律专业知识,以确保分解后的子案件能够真实反映原始案件的复杂性。此外,数据集的标注和验证过程也需耗费大量时间和资源,以保证数据的高质量和可靠性。这些挑战不仅影响了数据集的构建效率,也对法律AI工具的准确性和实用性提出了更高的要求。
常用场景
经典使用场景
在法律领域,PandaVT/datatager_legal_split_cases数据集的经典使用场景主要体现在法律AI工具的开发上。该数据集通过将复杂案件分解为多个独立子案件,每个子案件聚焦于特定的法律问题或争议,从而帮助AI系统在法律咨询中更高效地处理涉及多重法律问题的复杂案件。
衍生相关工作
基于PandaVT/datatager_legal_split_cases数据集,衍生了一系列经典工作,包括法律AI系统的开发、法律教育资源的优化以及法律研究方法的创新。这些工作不仅提升了法律实践的效率,还推动了法律领域的技术进步,为法律教育和研究提供了新的视角和工具。
数据集最近研究
最新研究方向
在法律领域的快速发展中,PandaVT/datatager_legal_split_cases数据集的出现为法律AI工具的开发提供了新的契机。该数据集通过将复杂案件分解为多个独立的子案件,聚焦于特定的法律问题或争议,极大地提升了法律从业者在处理案件时的效率。前沿研究方向主要集中在利用该数据集训练AI系统,以辅助律师和法官在复杂的法律咨询中快速梳理法律问题、相关证据及其他关键信息,从而实现更迅速、更精准的决策支持。此外,该数据集还为法律教育提供了宝贵的资源,有助于培养法学生和初级律师在处理复杂案件时的分析和研究能力。
以上内容由遇见数据集搜集并总结生成


