AuthorAwareDetectionBench
收藏Hugging Face2025-12-25 更新2025-12-26 收录
下载链接:
https://huggingface.co/datasets/leejamesssss/AuthorAwareDetectionBench
下载链接
链接失效反馈官方服务:
资源简介:
AuthorAwareDetectionBench是一个用于研究社会语言学属性(包括性别、CEFR熟练度、学术领域和语言环境)对AI文本检测器性能影响的基准数据集。该数据集包含61,656个由12种不同现代大型语言模型(如Qwen 2.5、Llama 3.1/3.2、Mistral等)生成的文本样本,这些文本模拟了来自ICNALE语料库的人类作者的人口统计特征。数据集提供了详细的元数据,包括生成模型信息、提示类型、作者标识符以及各种社会语言学属性,为AI生成文本检测的偏见分析提供了受控环境。
创建时间:
2025-12-23
原始信息汇总
数据集概述
基本信息
- 数据集名称: AuthorAwareDetectionBench
- 发布平台: Hugging Face
- 许可证: CC BY-NC 4.0 (AI文本与元数据),MIT (代码)
- 任务类别: 文本分类
- 语言: 英语
- 数据规模: 10K < n < 100K
- 标签: AI检测、社会语言学、公平性、ICNALE
核心描述
该数据集是ACL 2025论文《Who Writes What: Unveiling the Impact of Author Roles on AI-generated Text Detection》的官方基准。旨在研究社会语言学属性(包括性别、CEFR熟练度、学术领域和语言环境)如何影响AI文本检测器的性能。数据集通过使用12种不同的LLM,基于ICNALE语料库中人类作者的人口统计特征生成平行文本来构建,为偏见分析提供了一个受控环境。
数据集统计
- 总样本数: 61,656 (均为AI生成文本)
- 生成模型: 12种现代LLM (包括Qwen 2.5, Llama 3.1/3.2, Mistral等)
- 作者属性: 性别、CEFR熟练度、学术体裁、语言环境
- 基础语料库: ICNALE Written English Corpus 2.6
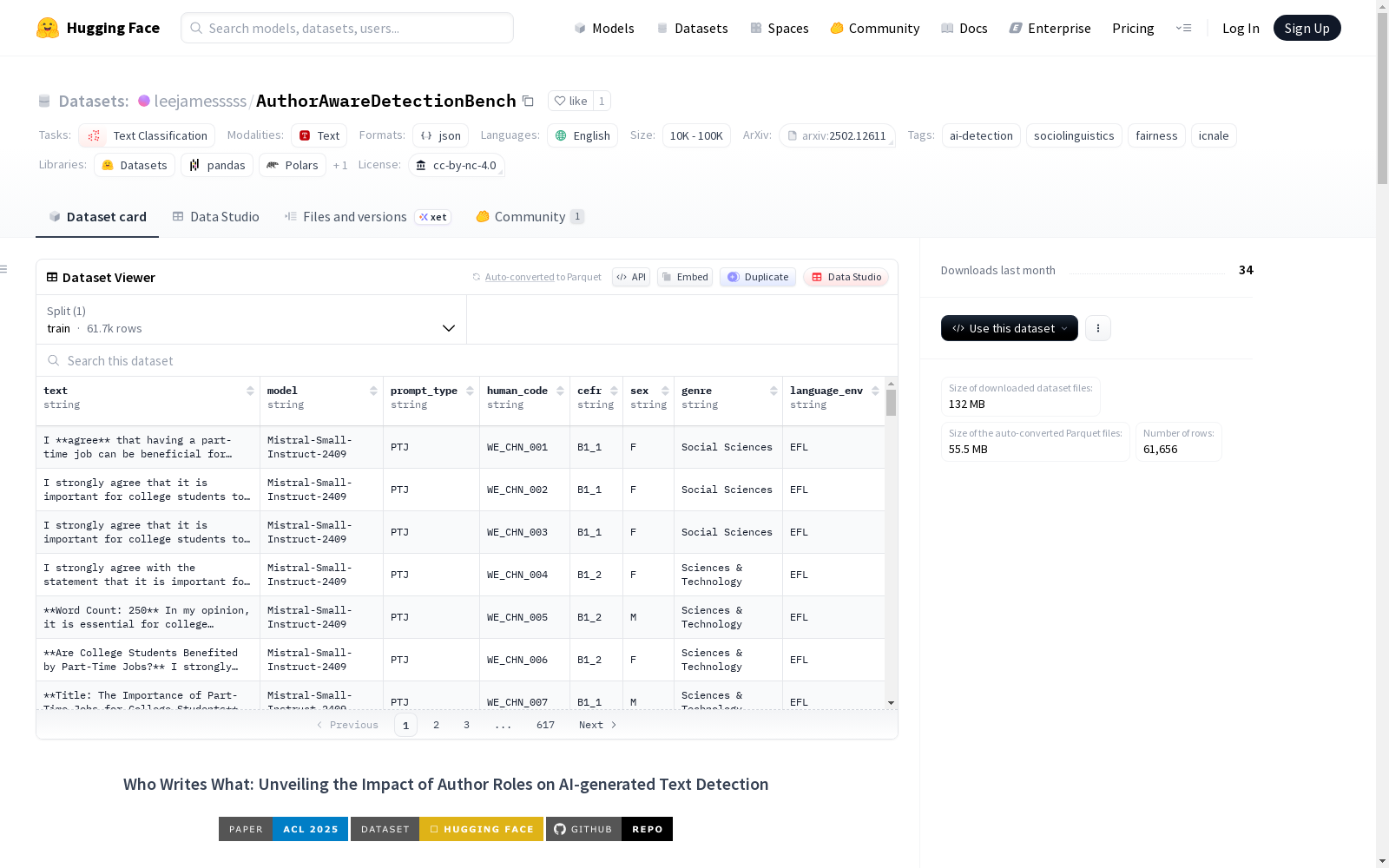
数据字段
| 字段名 | 描述 |
|---|---|
text |
AI模型生成的内容。 |
model |
用于生成文本的特定AI模型 (例如 Mistral-Small-Instruct-2409)。 |
prompt_type |
写作主题: PTJ (兼职工作) 或 SMK (禁烟)。 |
human_code |
与元数据中原始人类作者对应的顺序标识符。 |
cefr |
作者的CEFR熟练度等级 (例如 A2, B1, XX 表示母语者)。 |
sex |
作者的性别: F (女性) 或 M (男性)。 |
genre |
作者的学术体裁/领域。 |
language_env |
作者的语言环境 (例如 EFL, ESL, ENS)。 |
数据访问方式
1. 仅AI生成数据
可通过Hugging Face datasets库直接加载AI生成部分的数据:
python
from datasets import load_dataset
dataset = load_dataset("leejamesssss/AuthorAwareDetectionBench", split="train")
2. 完整基准复现 (人类文本 + AI文本)
由于ICNALE使用条款限制,本仓库不提供原始人类文本。完整复现需遵循以下步骤:
- 准备数据:
- 从官方渠道下载ICNALE Written English Corpus (WE v2.6模块的
WE_0_Unclassified_Unmerged文件夹)。 - 从本数据集的Files and versions页面下载
ai_generated_dataset.jsonl。 - 克隆GitHub仓库
https://github.com/leejamesss/AuthorAwareDetection.git以获取处理脚本和元数据。
- 从官方渠道下载ICNALE Written English Corpus (WE v2.6模块的
- 合并数据集:
- 使用仓库中的脚本
data/scripts/merge_data.py,将下载的人类文本、元数据文件(human_metadata.csv)与AI生成数据文件进行对齐和合并。
- 使用仓库中的脚本
相关资源
- 论文: https://aclanthology.org/2025.acl-long.1292.pdf
- 主页: https://github.com/leejamesss/AuthorAwareDetection
- 代码仓库: https://github.com/leejamesss/AuthorAwareDetection
搜集汇总
数据集介绍
构建方式
在人工智能文本检测领域,现有研究往往忽视了作者社会语言学特征对检测性能的潜在影响。AuthorAwareDetectionBench数据集的构建旨在填补这一空白,其核心方法是以ICNALE书面英语语料库为基础,选取其中具有明确性别、语言能力、学术领域及语言环境属性的人类作者文本作为参照。研究者随后运用包括Qwen 2.5、Llama系列及Mistral在内的12种前沿大语言模型,依据人类作者的属性档案生成与之平行的模拟文本,从而构建了一个包含超过六万条样本的、属性可控的AI生成文本集合,为系统性分析检测器偏见创造了条件。
使用方法
使用该数据集主要可通过两种途径。最便捷的方式是直接通过Hugging Face平台加载已发布的纯AI生成文本部分,用于训练或评估检测模型。若需复现包含人类对照文本的完整基准测试,则需遵循既定流程:首先从官方渠道获取ICNALE语料库中的人类文本,再结合本数据集提供的AI文本与元数据,运行项目仓库中提供的合并脚本进行对齐与整合。这种设计既遵守了原始人类语料的使用条款,又确保了研究的可复现性,使用者可根据具体研究目标灵活选择数据范围。
背景与挑战
背景概述
随着人工智能生成文本的广泛应用,其检测技术成为自然语言处理领域的关键议题。AuthorAwareDetectionBench数据集由研究人员Jiatao Li和Xiaojun Wan于2025年构建,并在ACL 2025会议上正式发布。该数据集旨在探究作者社会语言学特征——包括性别、语言熟练度、学术领域及语言环境——对AI生成文本检测性能的影响。通过整合ICNALE语料库中的人类作者元数据,并利用12种大型语言模型生成平行文本,该数据集为分析检测模型中的潜在偏见提供了可控实验环境,推动了AI文本检测领域向更公平、更细致的方向发展。
当前挑战
该数据集致力于解决AI生成文本检测中的公平性问题,其核心挑战在于揭示检测模型对不同作者群体可能存在的系统性偏差。具体而言,检测算法在应对不同性别、语言水平或文化背景的作者时,性能表现可能出现显著差异,这种偏差若不加以识别和纠正,将加剧技术应用中的不平等现象。在构建过程中,研究者面临的主要挑战包括如何精确对齐人类作者元数据与AI生成文本,以及如何在遵守ICNALE语料库使用条款的前提下,设计可复现的基准测试流程,确保数据集的科学性与合规性。
常用场景
经典使用场景
在自然语言处理领域,随着大型语言模型生成文本的普及,AI文本检测成为确保内容真实性与学术诚信的关键任务。AuthorAwareDetectionBench数据集通过整合12种现代大型语言模型生成的文本,并标注作者的社会语言学属性,为研究者提供了一个系统评估检测模型性能的基准平台。该数据集常用于训练和测试AI文本检测算法,特别是在探究不同作者角色对检测结果影响的实验中,为模型公平性与鲁棒性分析提供了数据支撑。
解决学术问题
该数据集旨在解决AI文本检测研究中长期被忽视的作者特征影响问题。通过引入性别、语言熟练度、学术领域和语言环境等多维度社会语言学属性,数据集揭示了检测模型在不同作者群体中可能存在的性能偏差。这有助于学术界深入理解检测算法的局限性,推动建立更公平、更普适的检测框架,从而在自然语言处理与社会计算交叉领域促进算法公平性研究的发展。
实际应用
在实际应用中,该数据集为教育评估、内容审核和学术诚信维护等场景提供了重要参考。教育机构可利用其评估学生作业中AI生成内容的检测准确性,同时考虑不同语言背景学生的公平性。内容平台则可借助数据集优化检测模型,减少对特定作者群体的误判,提升自动化审核系统的可靠性与包容性,从而在现实世界中推动负责任AI技术的部署。
数据集最近研究
最新研究方向
在人工智能生成文本检测领域,传统方法往往忽视作者社会语言学特征对检测性能的潜在影响。AuthorAwareDetectionBench的推出,标志着该领域开始系统性地探索性别、语言熟练度、学术领域及语言环境等多维作者属性如何塑造文本特征,进而影响检测器的公平性与准确性。这一研究方向紧密关联当前大语言模型广泛渗透学术写作与内容创作的热点背景,其核心意义在于揭示检测算法中可能存在的隐性偏见,为构建更具包容性和鲁棒性的下一代AI文本检测框架提供了实证基础与评估基准。
以上内容由遇见数据集搜集并总结生成


