CAMEO
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/amu-cai/CAMEO
下载链接
链接失效反馈官方服务:
资源简介:
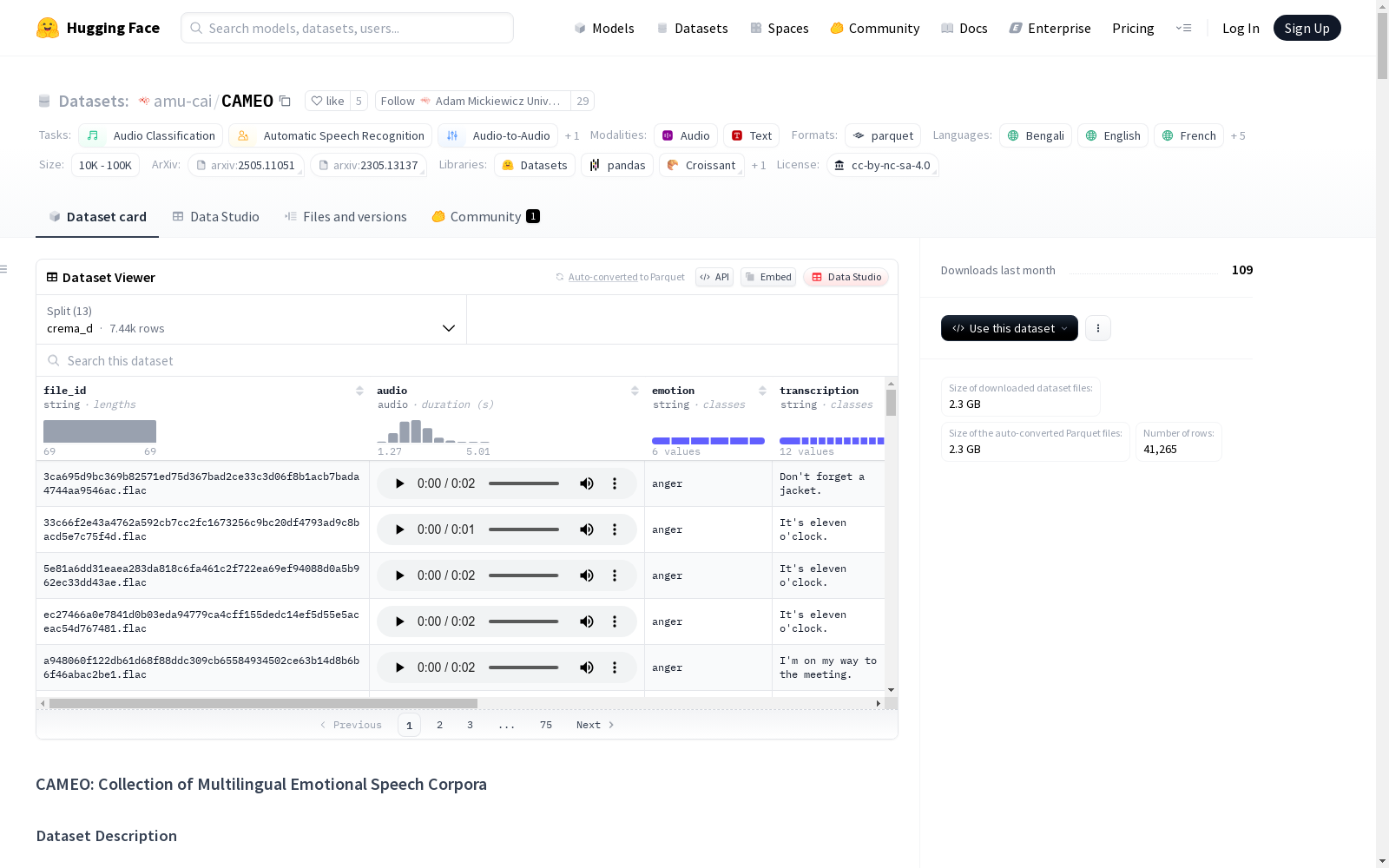
CAMEO是一个多语言情感语音数据集的精选集合,旨在促进情感识别和其他语音相关任务的研究。该数据集包含13个经过精心挑选的数据集,涵盖8种语言,总计41,265个音频样本。数据集包含了17种独特的情感状态,其中93.45%被标注为7种主要情感:愤怒、厌恶、恐惧、幸福、中性、悲伤和惊讶。数据集的创建过程包括数据获取、数据标准化、元数据序列化和分发与文档化。CAMEO数据集旨在解决现有数据集缺乏标准化和跨语言鲁棒性的问题,为研究人员提供一个全面且可重复的基准,以评估和比较跨语言模型的性能。
CAMEO is a curated collection of multilingual emotional speech datasets intended to advance research in emotion recognition and other speech-related tasks. This collection comprises 13 carefully selected datasets covering 8 languages, with a total of 41,265 audio samples. It encompasses 17 distinct emotional states, 93.45% of which are annotated with 7 primary emotions: anger, disgust, fear, happiness, neutral, sadness, and surprise. The development workflow of the CAMEO dataset includes data acquisition, data standardization, metadata serialization, distribution and documentation. The CAMEO dataset aims to address the limitations of existing datasets in terms of standardization and cross-lingual robustness, providing researchers with a comprehensive and reproducible benchmark for evaluating and comparing the performance of cross-lingual models.
提供机构:
亚当·密茨凯维奇大学
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
CAMEO数据集的构建采用了系统化的多阶段流程,以确保数据的完整性和标准化。首先,研究人员从原始来源手动下载了13个多语言情感语音数据集,确保遵守各数据集的许可条款。随后,所有音频文件被统一转换为16位、16 kHz采样率的FLAC格式,以保持一致性。在元数据处理方面,研究团队从相关文档和出版物中提取了情感标签、说话者标识等关键信息,并进行了跨数据集的归一化处理。对于转录文本,使用Whisper Large v2模型进行音频-文本对齐,并经过人工验证以确保准确性。最终,所有元数据采用JSON Lines格式序列化,并赋予每个音频样本唯一标识符,形成结构化的数据集合。
特点
CAMEO数据集最显著的特点是其多语言覆盖性和情感多样性。该集合包含13个数据集,涵盖英语、法语、意大利语等8种语言,共计41,265个音频样本。其中93.45%的样本标注了愤怒、厌恶、恐惧等七种基本情感状态,同时包含17种细分情感类别。数据集特别注重说话者元数据的完整性,94.53%的样本包含说话者标识,92.87%标注了性别信息,男女比例均衡(女性43.57%,男性49.30%)。所有数据均采用统一的FLAC音频格式和标准化的元数据结构,并附带详细的文档说明和开源评估代码,为跨语言情感语音研究提供了基准平台。
使用方法
使用CAMEO数据集时,研究人员可通过Hugging Face平台直接访问完整的语料库及其标准化元数据。数据集特别设计为零样本评估基准,不建议进行训练-测试分割,以保持语言和情感的多样性。评估时需遵循统一的文本指令模板(如Listing 1所示),要求模型仅基于音频特征预测情感状态。为处理模型输出的变体,研究团队开发了基于Levenshtein相似度的后处理策略,设定0.57的阈值来匹配标准情感标签。平台提供的公开排行榜支持多模型比较,评估指标包括宏平均F1值、加权F1值和准确率。用户还可利用开源代码复现基准结果,或扩展新的数据集和评估方法。
背景与挑战
背景概述
CAMEO(Collection of Multilingual Emotional Speech Corpora)是由波兰亚当·密茨凯维奇大学的Iwona Christop和Maciej Czajka等研究人员于2025年推出的多语言情感语音数据集。该数据集旨在推动语音情感识别(SER)领域的研究,特别是在多语言环境下的情感识别任务。CAMEO整合了13个情感语音数据集,涵盖8种语言,总计41,265个音频样本,并提供了标准化的元数据和评估工具。其核心研究问题是解决情感语音数据集在标准化、可访问性和多语言适用性方面的不足,为跨语言情感识别研究提供了重要基础。
当前挑战
CAMEO数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,语音情感识别本身具有较高的复杂性,情感表达受语言、文化和个人差异的影响,导致模型在多语言环境下的泛化能力不足。此外,情感标注的主观性也增加了模型训练的难度。在构建过程中,研究人员需要解决数据集之间的异质性问题,包括不同的情感标签体系、音频格式和元数据标准。同时,确保数据集的合法访问和标准化处理也是一大挑战,特别是对于不同许可证下的数据集进行整合和规范化。
常用场景
经典使用场景
在语音情感识别(SER)领域,CAMEO数据集通过整合多语言情感语音数据,为研究者提供了一个标准化的基准平台。其经典使用场景包括跨语言情感识别模型的训练与评估,尤其在对比不同语言和文化背景下情感表达的差异时,CAMEO的多样性和标准化标注显著提升了研究的可重复性和可比性。
解决学术问题
CAMEO解决了情感语音研究中的两大核心问题:数据集碎片化与标注不一致性。通过系统化整合13个数据集、统一8种语言的标注标准,该数据集为跨语言情感识别模型的开发提供了可靠基础。其公开的评测框架和排行榜进一步推动了学术共同体在模型泛化性、多模态融合等方向的探索。
衍生相关工作
围绕CAMEO已衍生出多项创新研究,如Qwen2-Audio模型在跨语言情感识别中的性能验证工作。数据集的结构化设计还启发了EmoBox等工具箱的优化,推动了多语种情感计算资源的整合。其公开的评测框架更成为后续研究比较模型鲁棒性的重要参照系。
以上内容由遇见数据集搜集并总结生成


