Incantation dataset
收藏数据集概述
该数据集是 Incantation 项目的一个早期公开预览子集,专注于《艾尔登法环》游戏中的战斗场景,包含玩家与 Boss 之间交互的手动收集视频片段及结构化元数据。
数据集基本信息
- 名称: Incantation Elden Ring Combat Captions
- 许可证: 其他(非标准)
- 语言: 英语
- 任务类型: 视频分类、视频文本到文本、文本生成
- 标签: 视频字幕、动作识别、游戏视频、艾尔登法环、咒术
- 预览子集: 仅供格式参考、原型验证和社区引用,并非最终完整数据集。
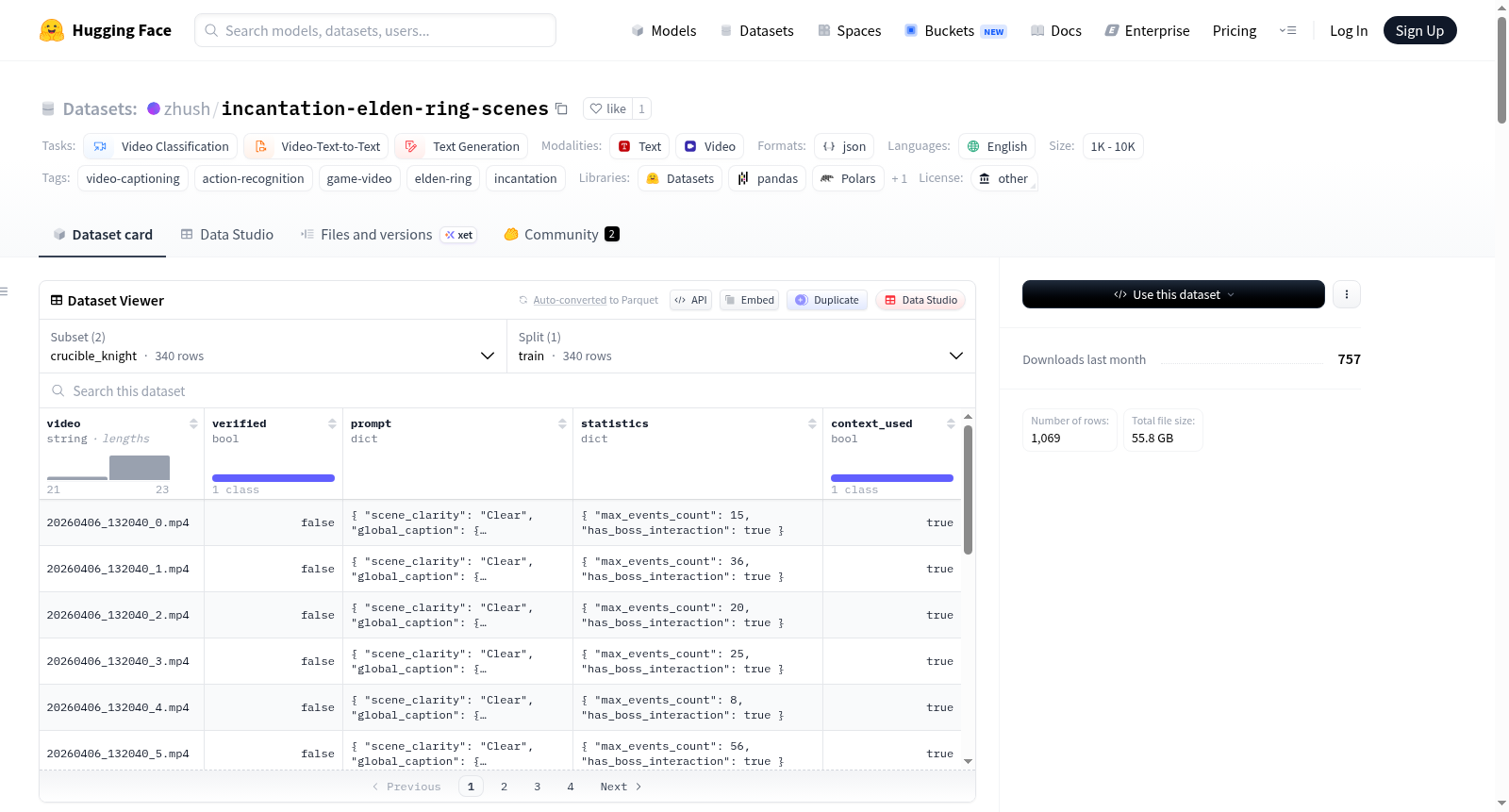
数据规模与配置
数据集当前包含两个配置(Config),每个配置对应一个 Boss 场景:
| 配置名称 | 元数据行数(JSONL) | 视频文件数(MP4) |
|---|---|---|
margit |
729 行 | 729 个 |
crucible_knight |
340 行 | 340 个 |
总计: 1069 个视频片段。
数据结构
数据集采用场景中心(scene-centric)的目录布局:
margit/ meta_data.jsonl videos/ *.mp4 crucible_knight/ meta_data.jsonl videos/ *.mp4
每个视频片段对应一条 JSONL 记录,主要字段包括:
video: 视频文件名,实际 MP4 文件位于对应场景的videos/目录下。verified: 标注是否经过人工验证。prompt.scene_clarity: 场景质量标签(如 "Clear")。prompt.global_caption: 片段级摘要,包括简短描述、长描述、可见对象、开始和结束时间。prompt.participants: 每个实体(玩家、Boss)的时间线,按时间顺序列出动作片段,包含开始/结束时间、动作描述、是否交互及交互对象。statistics: 统计信息,如最大事件数、是否包含 Boss 交互。context_used: 是否使用了上下文信息进行标注。
数据收集方式
所有视频片段均通过人工驱动的工作流程进行收集、筛选、组织和审核,而非无差别地网络爬取。收集过程强调具有可见玩家-Boss 交互且具有可用动作结构的战斗片段。
预期用途
该数据集可用于以下研究领域:
- 训练基于动作或语言描述的条件化交互视频生成模型
- 训练单一共享视角下的多实体世界模型
- 从视频-动作轨迹中训练或评估游戏智能体
- 研究时间动作定位、战斗事件解析和视频字幕生成
- 为游戏世界或具身智能体构建基于语言的控制接口原型
数据加载
可以使用 Hugging Face datasets 库加载不同配置:
python from datasets import load_dataset
margit = load_dataset("zhush/incantation-elden-ring-scenes", "margit") crucible_knight = load_dataset("zhush/incantation-elden-ring-scenes", "crucible_knight")
加载后需将 video 字段中的文件名与对应场景目录(如 margit/videos/)拼接以访问实际视频文件。
与 Incantation 论文的关系
该预览子集与 Incantation 研究项目相关,但并非最终论文所使用的完整数据集。完整发布版预计将包含更多《艾尔登法环》Boss、《拳皇》数据、代码和模型检查点。
局限性
- 仅为预览子集,不代表最终项目的动作分布、Boss 覆盖、世界或数据规模
- 元数据以研究为目的设计,可能包含不完美的字幕或未验证的行
- 视频片段分布受人工收集和筛选影响,并非平衡的基准测试
- 包含商业游戏实况,下游使用者应遵守相关研究、法律和平台限制
法律声明
《艾尔登法环》是 FromSoftware, Inc. 和 Bandai Namco Entertainment Inc. 的商标。该数据集是学术研究产物,与游戏开发商或发行商无关,未经其认可或赞助。
- 1Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models上海交通大学; 英伟达研究院; 中国科学技术大学; 中国科学院大学; 新加坡国立大学; 滑铁卢大学; 香港科技大学; 香港大学; 中国电子科技集团公司 · 2026年


