mteb/urbansound8K
收藏Hugging Face2026-02-05 更新2026-02-07 收录
下载链接:
https://hf-mirror.com/datasets/mteb/urbansound8K
下载链接
链接失效反馈官方服务:
资源简介:
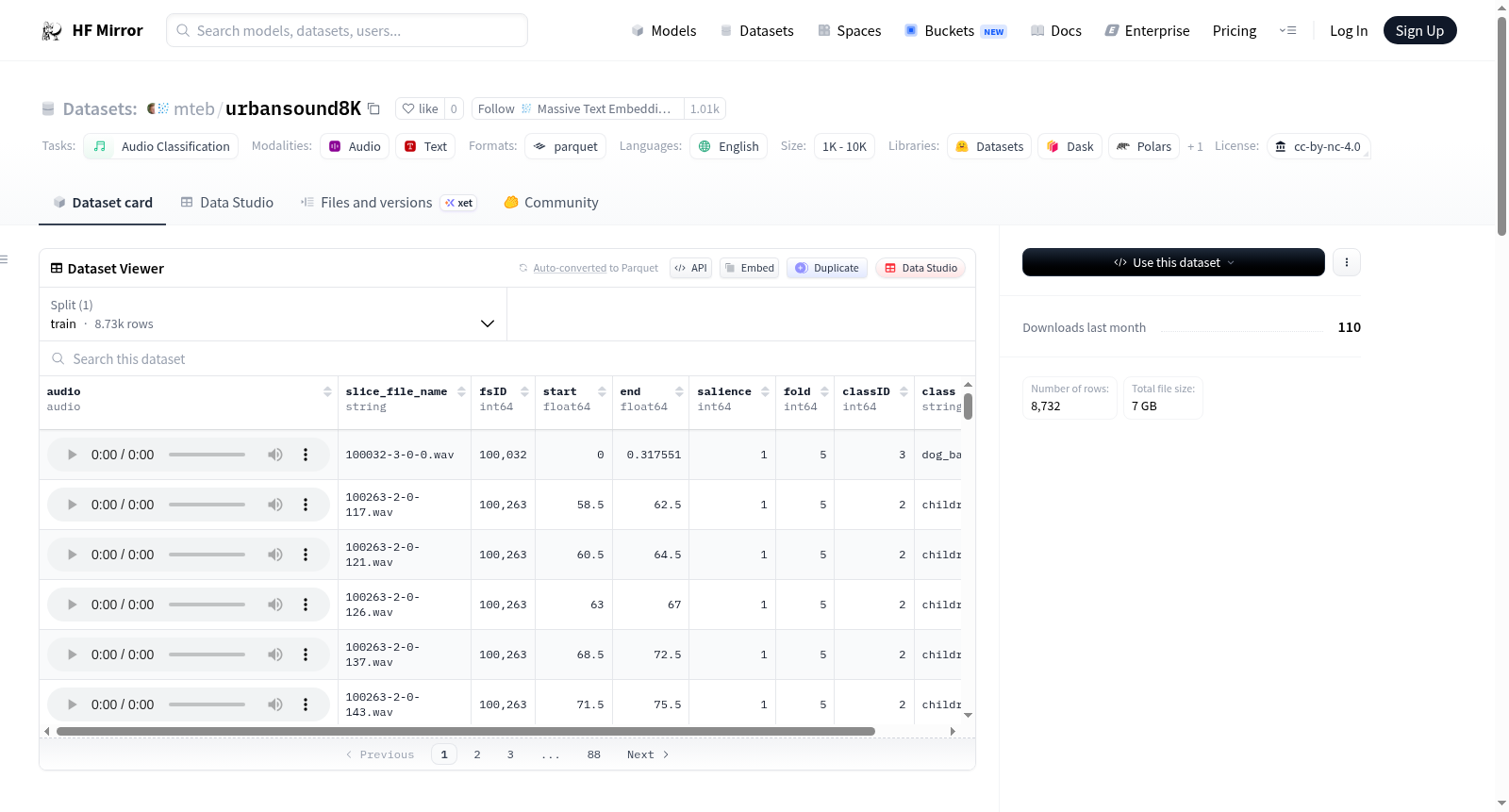
UrbanSound8K数据集是一个用于音频分类的数据集,包含8732个标记的城市声音片段(<=4秒),分为10个类别:空调声、汽车喇叭声、儿童玩耍声、狗叫声、钻孔声、发动机怠速声、枪声、破碎锤声、警笛声和街头音乐声。这些类别来自城市声音分类法。所有片段均来自上传至Freesound.org的现场录音。文件已预先分为十个折叠(fold1-fold10),以便于复现和与文献中报告的自动分类结果进行比较。除了声音片段外,还提供了一个包含每个片段元数据的CSV文件。数据集中的音频文件为WAV格式,采样率、位深度和通道数与原始文件相同(可能因文件而异)。元数据文件包括音频文件名、Freesound ID、开始和结束时间、显著性评级、折叠编号、类别ID和类别名称等信息。为避免常见错误,README强调不要重新洗牌数据,应使用预定义的10折交叉验证,并报告平均分数以确保结果的可比性。数据集来源于Freesound.org的现场录音,用于城市声音研究。
The UrbanSound8K dataset is an audio classification dataset containing 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes: air_conditioner, car_horn, children_playing, dog_bark, drilling, engine_idling, gun_shot, jackhammer, siren, and street_music. The classes are drawn from the urban sound taxonomy. All excerpts are taken from field recordings uploaded to Freesound.org. The files are pre-sorted into ten folds (fold1-fold10) to aid in the reproduction of and comparison with prior automatic classification results. In addition to the sound excerpts, a CSV file containing metadata for each excerpt is provided. The audio files are in WAV format, with sampling rate, bit depth, and number of channels matching the original files (which may vary). The metadata includes the audio file name, Freesound ID, start and end times, salience rating, fold number, class ID, and class name. The README cautions against common pitfalls such as reshuffling the data or evaluating on a single split, recommending the use of predefined 10-fold cross-validation and reporting average scores for comparable results. The dataset is sourced from Freesound.org field recordings and is intended for urban sound research.
提供机构:
mteb
搜集汇总
数据集介绍
构建方式
在环境声学领域,UrbanSound8K数据集的构建体现了严谨的学术规范。该数据集源自Freesound.org平台上的实地录音,研究者从中精心截取了时长不超过4秒的音频片段。这些片段依据城市声音分类学被划分为10个类别,涵盖了从空调声到街道音乐等典型城市声景。为确保研究可复现性,所有8732个样本被预先划分为十个互斥的折叠(fold),每个折叠均包含完整的类别分布,这种结构设计为后续的交叉验证提供了标准化基础。
特点
该数据集的核心特征在于其高度的生态效度与精细的标注体系。所有音频样本均直接采集自真实城市环境,保留了原始录音的采样率、位深度和声道数等物理属性,从而最大程度地还原了声音的本来面貌。除音频文件外,数据集提供了详尽的元数据,包括每条片段在原始录音中的起止时间、主观显著度评分(前景/背景)以及基于Freesound ID的溯源信息。这种多维度的标注为研究声音事件的上下文关系及模型的可解释性提供了宝贵资源。
使用方法
使用本数据集时,必须严格遵循其预设的评估协议以保障研究结果的可靠性与可比性。用户应直接采用数据集提供的十个折叠进行十折交叉验证,而非重新随机划分数据,以避免因训练集与测试集出现相关性样本而导致性能评估失真。在每一轮验证中,需选取一个折叠作为测试集,其余九个作为训练集,并最终汇报十次测试结果的平均性能指标。这种方法确保了评估过程能够全面反映模型在不同数据子集上的泛化能力,并与现有学术文献保持一致的比较基准。
背景与挑战
背景概述
UrbanSound8K数据集由纽约大学音乐与音频研究实验室(MARL)的Juan Pablo Bello团队于2014年创建,旨在为城市环境声音识别研究提供标准化基准。该数据集收录了8732段时长不超过4秒的音频片段,涵盖空调声、汽车喇叭、儿童玩耍等10类城市声音,源自Freesound平台的真实场录音。其核心研究问题聚焦于复杂声学场景下的自动音频分类,推动了环境声音分析、噪声监测及智能城市感知等领域的发展,成为音频机器学习领域的重要资源。
当前挑战
UrbanSound8K数据集面临的挑战主要体现在两个方面:在领域问题层面,城市声音分类需应对声学环境的多样性,如背景噪声干扰、声音事件重叠及类间相似性高(如钻机与破碎机),这要求模型具备鲁棒的声学特征提取与上下文理解能力。在构建过程中,挑战源于真实世界录音的异构性,包括采样率、比特深度和声道数的差异,以及人工标注时对声音显著性(前景与背景)的主观判断,这些因素增加了数据标准化与质量控制的复杂度。
常用场景
经典使用场景
在环境声学领域,UrbanSound8K数据集为音频分类任务提供了标准化的评估基准。该数据集收录了涵盖城市环境中十类常见声源的8732个音频片段,每段时长不超过四秒,并预先划分为十个交叉验证折。研究者通常利用这些预设折进行十折交叉验证,以训练和测试深度学习模型,如卷积神经网络或循环神经网络,从而实现对城市声音的自动识别与分类。这种严谨的实验设计确保了模型性能评估的可靠性与可复现性,使其成为音频信号处理领域广泛采用的经典数据集。
衍生相关工作
围绕UrbanSound8K数据集,学术界衍生了一系列经典研究工作。例如,原始论文提出的声学特征提取与分类框架,为后续研究设立了基线。许多研究在此基础上探索了梅尔频谱图与深度学习架构的结合,如采用CNN、LSTM或注意力机制以提升分类精度。此外,该数据集常被用于迁移学习与域自适应方法的验证,促进了预训练音频模型(如VGGish或YAMNet)在环境声音任务上的性能评估。这些工作共同推动了环境声学分类领域的算法进步与标准化进程。
数据集最近研究
最新研究方向
在环境声学与城市计算领域,UrbanSound8K数据集作为城市声音分类的基准资源,持续推动着音频信号处理的前沿探索。当前研究聚焦于深度学习模型的轻量化与泛化能力提升,通过卷积神经网络与注意力机制的融合,实现对复杂城市声景的精准识别。伴随智慧城市与噪声监测的热点应用,该数据集在异常声音检测、声学场景理解等方面展现出重要价值,为环境感知与公共安全研究提供了可靠的数据支撑。
以上内容由遇见数据集搜集并总结生成


