SimScale
收藏Hugging Face2026-01-25 更新2026-01-26 收录
下载链接:
https://huggingface.co/datasets/OpenDriveLab-org/SimScale
下载链接
链接失效反馈官方服务:
资源简介:
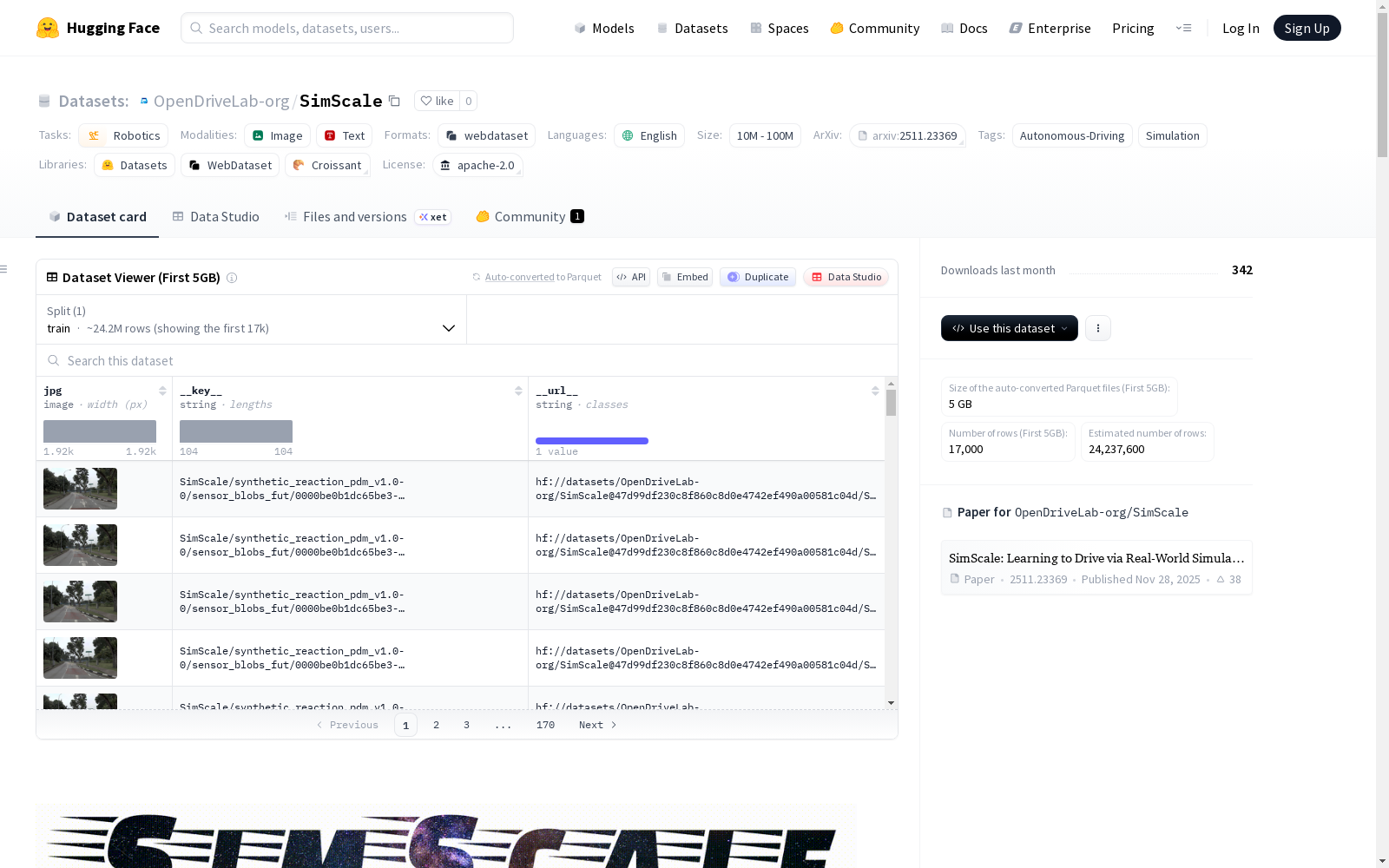
SimScale是一个用于自动驾驶的高保真仿真数据集,基于nuPlan和NAVSIM构建。它提供了多样化的反应式驾驶场景模拟数据,并包含伪专家演示。数据集分为多个部分,包括历史传感器数据和未来传感器数据,适用于端到端自动驾驶规划器的训练和评估。数据集还提供了详细的下载和配置指南,支持通过Hugging Face和ModelScope进行访问。
创建时间:
2026-01-13
原始信息汇总
SimScale 数据集概述
基本信息
- 数据集名称: SimScale
- 发布机构: OpenDriveLab-org
- 许可证: Apache-2.0
- 任务类别: 机器人学
- 主要语言: 英语
- 核心标签: 自动驾驶、仿真
- 数据规模: 大于1TB
数据集简介
SimScale 是一个用于自动驾驶的大规模仿真数据集。它提供了一个可扩展的仿真流程,用于合成多样化、高保真的反应式驾驶场景,并包含伪专家演示数据。该数据集旨在通过仿真与真实世界协同训练的策略,提升端到端规划器的鲁棒性和泛化能力。
数据基础与格式
- 数据基础: 基于 nuPlan 和 NAVSIM 数据集。
- 数据格式: 遵循 OpenScene 的数据格式。
- 时间范围: 每个数据片段(clip/log)具有固定的6秒时间跨度,采样频率为2 Hz。
- 数据存储:
sensor_blobs_hist: 存储过去2秒的历史传感器数据。sensor_blobs_fut: 存储未来4秒的未来传感器数据。
- 训练说明: 对于策略训练,仅使用
sensor_blobs_hist已足够。
数据内容与规模
数据集包含基于两种伪专家方法生成的合成仿真数据。
基于规划器的伪专家数据
包含5个仿真轮次(split),具体信息如下:
| 仿真轮次 | Token数量 | Logs大小 | Sensors_Hist大小 | Sensors_Fut大小 |
|---|---|---|---|---|
| reaction_pdm_v1.0-0 | 65K | 9.9 GB | 569 GB | 1.2 TB |
| reaction_pdm_v1.0-1 | 55K | 8.5 GB | 448 GB | 964 GB |
| reaction_pdm_v1.0-2 | 46K | 6.9 GB | 402 GB | 801 GB |
| reaction_pdm_v1.0-3 | 38K | 5.6 GB | 333 GB | 663 GB |
| reaction_pdm_v1.0-4 | 32K | 4.7 GB | 279 GB | 554 GB |
基于恢复的伪专家数据
包含5个仿真轮次(split),具体信息如下:
| 仿真轮次 | Token数量 | Logs大小 | Sensors_Hist大小 | Sensors_Fut大小 |
|---|---|---|---|---|
| reaction_recovery_v1.0-0 | 45K | 6.8 GB | 395 GB | 789 GB |
| reaction_recovery_v1.0-1 | 36K | 5.5 GB | 316 GB | 631 GB |
| reaction_recovery_v1.0-2 | 28K | 4.3 GB | 244 GB | 488 GB |
| reaction_recovery_v1.0-3 | 22K | 3.3 GB | 189 GB | 378 GB |
| reaction_recovery_v1.0-4 | 17K | 2.7 GB | 148 GB | 296 GB |
数据获取与准备
- 下载建议: 建议先按照 NAVSIM 的说明准备真实世界数据。
- 下载脚本: 提供了 Hugging Face 和 ModelScope 的下载脚本。
- 数据链接: 每个仿真轮次的数据在 Hugging Face 和 ModelScope 上均有存储。
- 目录结构: 提供了脚本用于将下载的仿真数据移动到指定的工作空间目录结构中。
相关资源
- 论文: https://arxiv.org/abs/2511.23369
- GitHub仓库: https://github.com/OpenDriveLab/SimScale
- 项目主页: https://opendrivelab.com/SimScale/
- ModelScope地址: https://modelscope.cn/datasets/OpenDriveLab/SimScale
许可与引用
- 代码库许可: Apache-2.0 许可证。
- 数据许可: 基于 nuPlan 的数据遵循 CC-BY-NC-SA 4.0 许可证。
- 引用格式: bibtex @article{tian2025simscale, title={SimScale: Learning to Drive via Real-World Simulation at Scale}, author={Haochen Tian and Tianyu Li and Haochen Liu and Jiazhi Yang and Yihang Qiu and Guang Li and Junli Wang and Yinfeng Gao and Zhang Zhang and Liang Wang and Hangjun Ye and Tieniu Tan and Long Chen and Hongyang Li}, journal={arXiv preprint arXiv:2511.23369}, year={2025} }
搜集汇总
数据集介绍
构建方式
在自动驾驶领域,高质量仿真数据的生成对于端到端规划模型的训练至关重要。SimScale数据集通过一个可扩展的仿真流程构建而成,其核心在于基于nuPlan和NAVSIM等真实世界数据集,合成多样且高保真的反应式驾驶场景。该流程能够生成包含伪专家演示的模拟数据,每个数据片段具有固定的6秒时间跨度,并以2赫兹的频率采样,其中历史信息与未来预测被分别存储。这种构建方式旨在为自动驾驶系统提供丰富的、可控的交互环境,以弥补真实数据在长尾场景和极端情况下的不足。
特点
SimScale数据集展现出显著的可扩展性与多样性,其数据总量超过1TB,涵盖了海量的模拟驾驶场景。该数据集提供了两种伪专家演示类型,即基于规划器的演示和基于恢复策略的演示,每种类型又包含多个仿真轮次,从而构成了一个层次丰富的训练资源。数据格式遵循OpenScene标准,确保了与现有工具链的兼容性。其核心特点在于通过模拟合成策略,系统地引入了驾驶场景中的反应性与不确定性,为研究端到端自动驾驶系统的规模化学习规律与泛化能力提供了关键实验基础。
使用方法
为有效利用SimScale数据集,研究者需首先按照指南准备NAVSIM等真实世界基准数据。随后,可通过官方提供的脚本从Hugging Face或ModelScope平台下载指定的模拟数据分片。数据下载后,需使用配套工具将其组织到特定目录结构中,以符合训练框架的要求。对于策略训练,仅需使用存储历史传感器信息的`sensor_blobs_hist`部分。该数据集旨在支持仿真与现实世界的协同训练策略,用户可依据其研究目标,灵活组合不同的模拟数据分片,以探究数据规模、专家类型对自动驾驶规划器性能与鲁棒性的影响。
背景与挑战
背景概述
在自动驾驶领域,端到端规划模型的训练长期受限于高质量、大规模反应式驾驶场景数据的匮乏。SimScale数据集由中国科学院自动化研究所、香港大学OpenDriveLab实验室与小米汽车于2025年联合创建,旨在通过可扩展的仿真管道合成多样且高保真的反应式驾驶场景,并生成伪专家演示数据。该数据集的核心研究问题聚焦于如何利用仿真数据与真实世界数据的协同训练,系统性提升端到端自动驾驶规划器的鲁棒性与泛化能力。其构建基于nuPlan与NAVSIM等真实数据集,通过创新的仿真策略生成了超过万亿令牌规模的合成数据,为探索仿真-现实学习系统的规模化特性提供了关键基础设施,对推动自动驾驶算法的安全演进具有深远影响。
当前挑战
SimScale数据集致力于解决端到端自动驾驶规划中模型对复杂、长尾反应式场景泛化能力不足的核心挑战。传统方法依赖有限且成本高昂的真实驾驶数据,难以覆盖紧急避障、交互博弈等关键边缘案例,导致规划模型在未知环境中的决策可靠性存在瓶颈。在构建过程中,研究团队面临多重挑战:首先,设计高保真且多样化的仿真管道需精确模拟动态交通参与者的复杂行为与传感器物理特性,确保合成数据与真实世界的分布对齐;其次,生成具有决策合理性的伪专家演示涉及复杂的轨迹优化与行为建模,对仿真逻辑的严谨性提出极高要求;此外,处理与协调超大规模(超过1TB)的多模态时序数据,并建立高效的存储、检索与训练流水线,亦是工程实现上的显著难题。
常用场景
经典使用场景
在自动驾驶领域,高质量、多样化的驾驶场景数据对于端到端规划器的训练至关重要。SimScale数据集通过其可扩展的仿真管道,合成了大量高保真的反应式驾驶场景,并提供了伪专家演示。该数据集最经典的使用场景是作为端到端自动驾驶规划模型的训练数据源,特别是用于模拟真实世界中难以采集的长尾和边缘案例,如复杂交互、突发危险等反应式场景,从而显著提升模型在仿真环境中的泛化能力和鲁棒性。
衍生相关工作
SimScale数据集本身是构建在nuPlan和NAVSIM等经典自动驾驶数据集与仿真平台之上的创新工作。它衍生的相关研究主要围绕其提出的仿真-现实协同训练范式展开,探索如何更有效地利用合成数据提升模型性能。该工作启发了后续对于数据合成管道优化、不同伪专家策略(如规划器驱动与恢复驱动)的效能比较,以及面向规模化学习的自动驾驶系统架构设计等一系列研究方向。
数据集最近研究
最新研究方向
在自动驾驶领域,仿真数据的规模与质量正成为推动端到端规划器发展的核心动力。SimScale数据集通过其可扩展的仿真流程,合成了大量高保真度的反应式驾驶场景,并提供了伪专家演示,这为研究大规模仿真-现实协同训练策略奠定了数据基础。当前的前沿探索聚焦于利用此类海量合成数据,揭示仿真-现实学习系统内在的扩展规律,旨在系统性提升规划模型在复杂长尾场景中的鲁棒性与泛化能力。这一研究方向直接呼应了行业对安全、可靠自动驾驶系统日益增长的需求,通过数据驱动的仿真技术,为突破现实世界数据收集的瓶颈提供了新的范式。
以上内容由遇见数据集搜集并总结生成


