LCFO
收藏arXiv2024-12-13 更新2024-12-25 收录
下载链接:
https://huggingface.co/datasets/facebook/LCFO
下载链接
链接失效反馈官方服务:
资源简介:
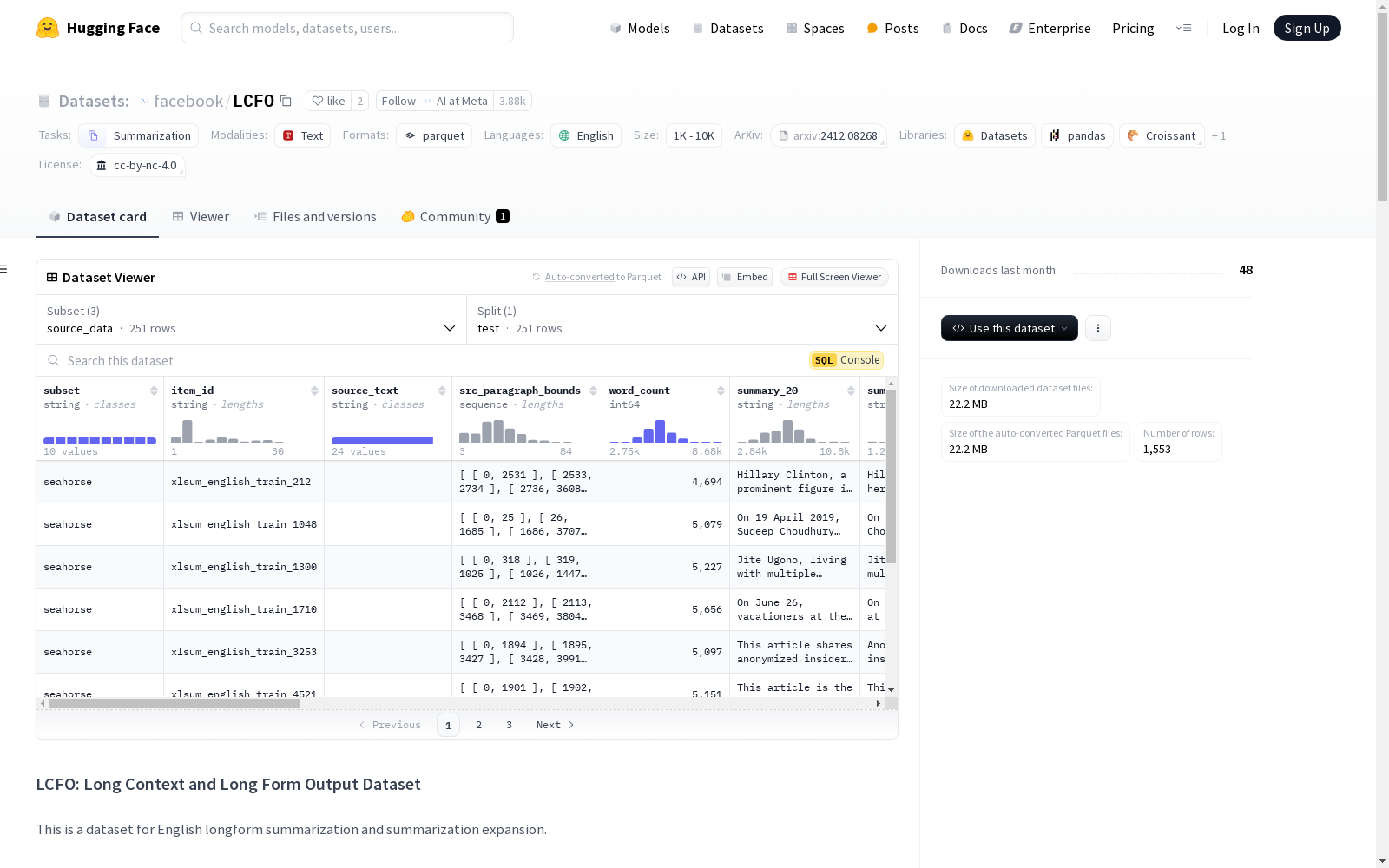
LCFO数据集是由Meta的FAIR团队创建的一个用于评估长文本摘要和扩展能力的基准数据集。该数据集包含252个平均长度为5000字的长文档,每个文档附带三个不同长度的摘要(分别为原文的20%、10%和5%)以及大约15个与文档内容相关的问题和答案。数据集的创建过程完全依赖人工标注,确保了数据的高质量和多样性。LCFO数据集主要用于评估模型在长文本摘要、阅读理解和摘要扩展等任务中的表现,旨在推动生成式AI技术的发展。
The LCFO dataset is a benchmark dataset created by Meta's FAIR team for evaluating long-text summarization and expansion capabilities. It contains 252 long documents with an average length of 5,000 characters, each accompanied by three summaries of varying lengths corresponding to 20%, 10%, and 5% of the original text respectively, as well as approximately 15 question-answer pairs related to the document content. The entire dataset creation process relies solely on manual annotation, ensuring high data quality and diversity. The LCFO dataset is primarily used to evaluate model performance on tasks such as long-text summarization, reading comprehension, and summary expansion, aiming to advance the development of generative AI technologies.
提供机构:
Meta的FAIR
创建时间:
2024-12-11
搜集汇总
数据集介绍
构建方式
LCFO数据集的构建过程严格遵循人工标注的原则,涵盖了七个不同领域的文档,包括政治、新闻、维基百科、科学、文学、对话和法律。每个输入文档的平均长度为5000字,并由人工撰写三个不同长度的摘要(20%、10%和5%)。此外,每个文档还配备了约15个问答对(QA),这些问答对与输入内容相关,并与不同长度的摘要对齐。数据集的构建过程从文档选择到最终标注均经过人工修订,确保数据的高质量和一致性。
特点
LCFO数据集的特点在于其多样性和多层次的结构。首先,它涵盖了多个领域,确保了数据集的广泛适用性。其次,每个文档配备了三个不同长度的摘要,提供了从详细到简洁的多层次参考,便于研究摘要生成和扩展任务。此外,数据集还包含了与文档内容相关的问答对,这些问答对不仅用于评估模型的阅读理解能力,还可以作为摘要质量的参考。最后,数据集还提供了人工评估分数,用于对比人类生成和模型生成的摘要质量。
使用方法
LCFO数据集的使用方法多样,适用于多种自然语言处理任务。首先,它可以用于评估模型在长文本摘要生成和摘要扩展任务中的表现。通过对比不同模型生成的摘要与人工撰写的摘要,研究人员可以评估模型的生成质量和一致性。其次,数据集中的问答对可以用于阅读理解任务的评估,测试模型对长文本的理解能力。此外,数据集还可以用于自动评估指标的开发和验证,帮助研究人员设计更准确的摘要评估方法。最后,LCFO数据集还可以作为训练数据,用于训练和优化生成模型,特别是在长文本生成任务中。
背景与挑战
背景概述
LCFO(Long Context and Long Form Output)数据集由Meta的FAIR团队于2024年12月发布,旨在为长文本生成任务提供一个标准化的评估框架。该数据集的核心研究问题是如何在长文本输入(平均5000字)的基础上,生成不同长度的摘要(20%、10%、5%),并进行摘要扩展任务。LCFO涵盖了政治、新闻、维基百科、科学、文学、对话和法律等七个领域,每个输入文档都附有三个不同长度的摘要以及约15个与输入内容相关的问题和答案。该数据集的创建动机是为了解决长文本生成中的可控性问题,特别是从短输入生成长文本的挑战。LCFO通过提供人类评估分数和自动评估指标,推动了生成式AI在摘要生成和扩展任务中的发展。
当前挑战
LCFO数据集在构建和应用过程中面临多重挑战。首先,长文本的摘要生成和扩展任务对模型的上下文理解和生成能力提出了极高的要求,尤其是在处理长文档时,模型需要保持信息的连贯性和完整性。其次,数据集的构建过程依赖于人工标注,标注者需要在不同领域的文档中提取核心信息并生成摘要,这对标注者的专业知识和语言能力提出了较高要求。此外,自动评估指标与人类评估分数之间的相关性较低(约0.4),表明现有的自动评估方法在捕捉摘要质量的多维度特征方面仍有不足。最后,长文本生成任务的高认知负荷使得人类评估过程复杂且耗时,进一步增加了评估的难度。
常用场景
经典使用场景
LCFO数据集主要用于评估大语言模型在长文本生成任务中的表现,特别是在逐步摘要和摘要扩展任务中。该数据集提供了平均长度为5000词的长文档,并为每个文档生成了三种不同长度的摘要(20%、10%和5%),同时还提供了与文档内容相关的15个问答对。这些标注使得LCFO能够用于逐步摘要、阅读理解、摘要扩展以及自动指标评估等多种任务。
解决学术问题
LCFO数据集解决了长文本生成任务中的评估难题,特别是在长上下文输入和长文本输出场景下的模型表现评估问题。通过提供不同长度的摘要和相关的问答对,LCFO为研究者提供了一个可控的框架,用于评估模型在生成长文本时的表现。此外,该数据集还提供了人类评估分数,帮助研究者更好地理解自动生成文本的质量,并推动了生成式AI的评估框架的进一步发展。
衍生相关工作
LCFO数据集的推出催生了一系列相关研究工作,特别是在长文本生成和评估领域。基于LCFO,研究者开发了多种自动评估指标,用于衡量生成文本的流畅性、一致性和信息覆盖率。此外,LCFO还为其他长文本数据集(如Longbench、Marathon等)提供了参考,推动了长文本生成任务的标准化评估方法的发展。这些相关工作进一步提升了生成式AI在长文本处理任务中的表现和应用潜力。
以上内容由遇见数据集搜集并总结生成


