WebWalkerQA
收藏arXiv2025-01-14 更新2025-01-15 收录
下载链接:
https://alibaba-nlp.github.io/WebWalker/
下载链接
链接失效反馈官方服务:
资源简介:
WebWalkerQA是由阿里巴巴集团创建的一个用于评估大语言模型在网页遍历任务中表现的数据集。该数据集包含680个问答对,涵盖了会议、组织、教育和游戏四个领域的1373个网页。数据集的构建采用了GPT-4和人工标注相结合的方式,确保数据的高质量和准确性。WebWalkerQA旨在解决大语言模型在处理复杂、多层次网页信息时的挑战,特别是在需要多步交互和深度探索的场景中。该数据集的应用领域主要集中在信息检索和问答系统,帮助提升大语言模型在真实世界网页环境中的表现。
WebWalkerQA is a dataset developed by Alibaba Group for evaluating the performance of large language models (LLMs) in web navigation tasks. This dataset includes 680 question-answer pairs, covering 1,373 webpages across four domains: conferences, organizations, education, and games. It was constructed using a combined approach of GPT-4 and manual annotation to guarantee high data quality and accuracy. WebWalkerQA is designed to address the challenges faced by LLMs when processing complex, multi-level webpage information, particularly in scenarios requiring multi-step interaction and in-depth exploration. Its main application areas center on information retrieval and question answering systems, aiming to improve the performance of large language models in real-world web environments.
提供机构:
阿里巴巴集团
创建时间:
2025-01-14
搜集汇总
数据集介绍
构建方式
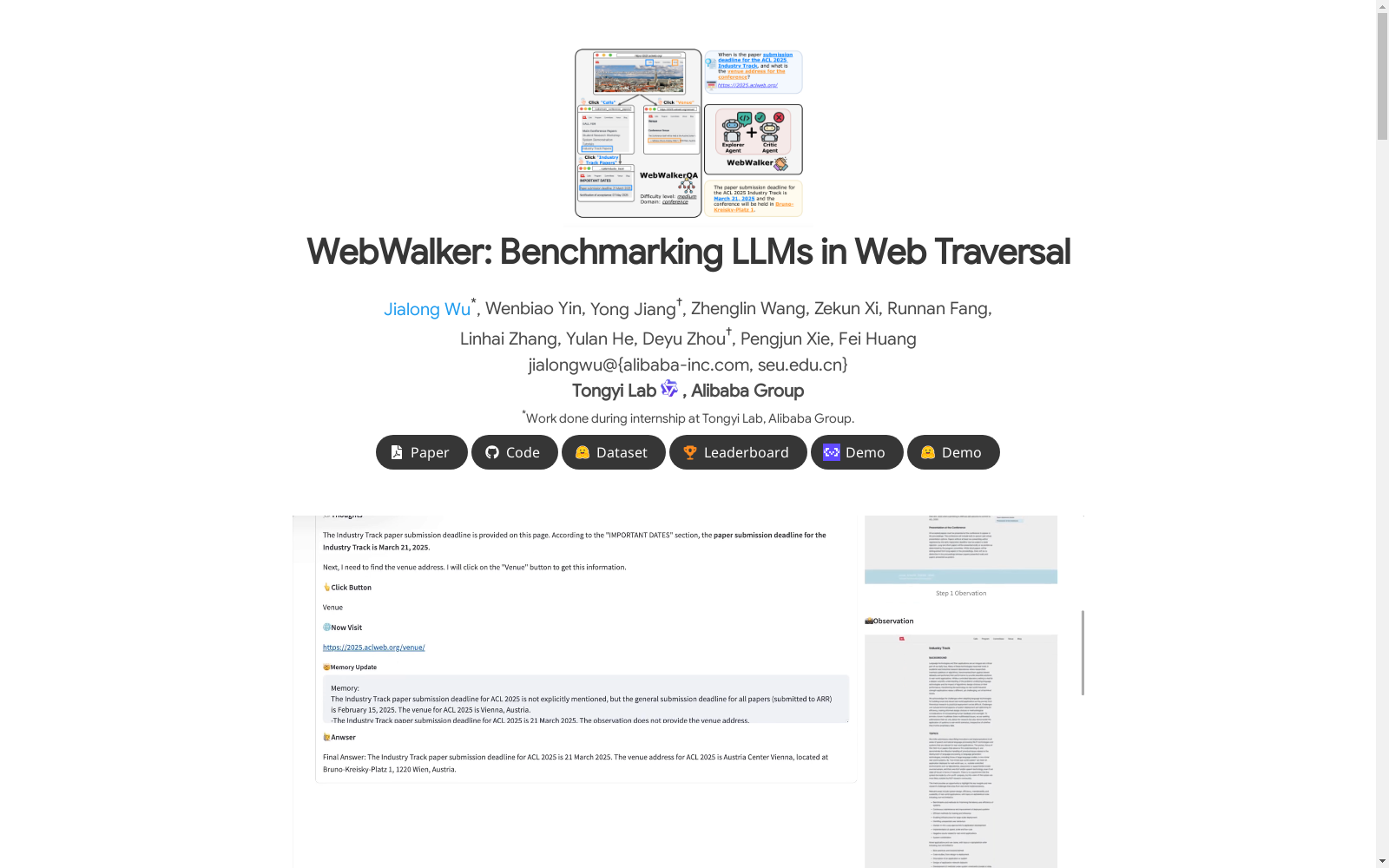
WebWalkerQA数据集的构建采用了双阶段标注策略,结合了基于大语言模型(LLM)的初始标注和众包人工标注的质量控制。首先,GPT-4模型对官方网站进行递归遍历,收集子页面的信息并生成初步的问答对。随后,人工标注者对生成的问答对进行校准和筛选,确保其准确性和一致性。数据集涵盖了教育、会议、组织和游戏等多个领域,最终生成了680个高质量的问答对。
特点
WebWalkerQA数据集的特点在于其多源和单源问答任务的结合,模拟了人类在网页浏览中的不同信息获取行为。单源任务要求用户深入挖掘单个页面的信息,而多源任务则需要用户整合多个页面的信息来回答问题。数据集还根据问题的复杂性分为简单、中等和困难三个难度级别,涵盖了中文和英文两种语言,确保了其在多语言和多领域场景下的广泛适用性。
使用方法
WebWalkerQA数据集主要用于评估大语言模型(LLM)在复杂网页遍历任务中的表现。通过模拟人类在网页中的点击和导航行为,模型需要从多个子页面中提取信息并回答问题。数据集的使用方法包括使用WebWalker框架进行网页遍历,结合探索者和批评者两个代理,探索者负责点击和导航,批评者负责评估信息是否足够回答问题。通过这种方式,模型可以在真实场景中测试其信息检索和推理能力。
背景与挑战
背景概述
WebWalkerQA是由阿里巴巴集团的研究团队于2025年提出的一个基准数据集,旨在评估大型语言模型(LLMs)在复杂网页遍历任务中的表现。该数据集由Jialong Wu等人设计,主要研究问题是如何通过多步网页遍历从深层网页中提取高质量信息。WebWalkerQA的创建背景源于传统搜索引擎在检索多层信息时的局限性,尤其是在处理需要多步交互的复杂查询时。该数据集通过模拟人类在网页上的导航行为,评估模型在真实场景中的信息检索和推理能力。WebWalkerQA的提出对信息检索和问答系统领域产生了重要影响,尤其是在增强模型对动态、多层次信息的处理能力方面。
当前挑战
WebWalkerQA面临的挑战主要体现在两个方面。首先,该数据集旨在解决复杂网页遍历任务中的信息检索问题,尤其是在需要多步推理和交互的场景中。传统搜索引擎通常只能进行水平搜索,难以有效提取深层网页中的信息,而WebWalkerQA要求模型能够通过垂直探索从多个网页中整合信息,这对模型的推理能力和上下文理解提出了更高的要求。其次,在数据集的构建过程中,研究人员面临了如何生成高质量、多样化的查询对以及如何确保数据集的真实性和复杂性的挑战。WebWalkerQA通过结合LLM生成和人工标注的两阶段策略,确保了数据的高质量,但其复杂性仍然对现有模型构成了显著挑战,尤其是在处理多源查询和长上下文推理时。
常用场景
经典使用场景
WebWalkerQA数据集主要用于评估大型语言模型(LLMs)在复杂、多步骤的网页遍历任务中的表现。通过模拟人类在网页上的导航行为,该数据集要求模型从多个子页面中提取信息,以回答复杂的多源问题。这种任务设计特别适用于测试模型在真实网页环境中的信息检索和推理能力。
实际应用
在实际应用中,WebWalkerQA可以用于构建智能助手或信息检索系统,帮助用户从复杂的网页结构中提取所需信息。例如,在教育、会议、组织和游戏等领域,用户可以通过该数据集训练的模型快速获取官方发布的信息,而无需手动浏览多个页面。这种应用场景特别适用于需要从多个来源整合信息的任务,如学术研究、市场分析等。
衍生相关工作
WebWalkerQA的提出催生了一系列相关研究工作,特别是在多代理框架和垂直探索机制的应用上。例如,WebWalker框架通过探索-批评范式模拟人类网页导航行为,进一步提升了模型在复杂网页环境中的表现。此外,该数据集还推动了RAG系统与多代理框架的结合,为未来的信息检索任务提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


