VISCO
收藏arXiv2024-12-03 更新2024-12-07 收录
下载链接:
https://visco-benchmark.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
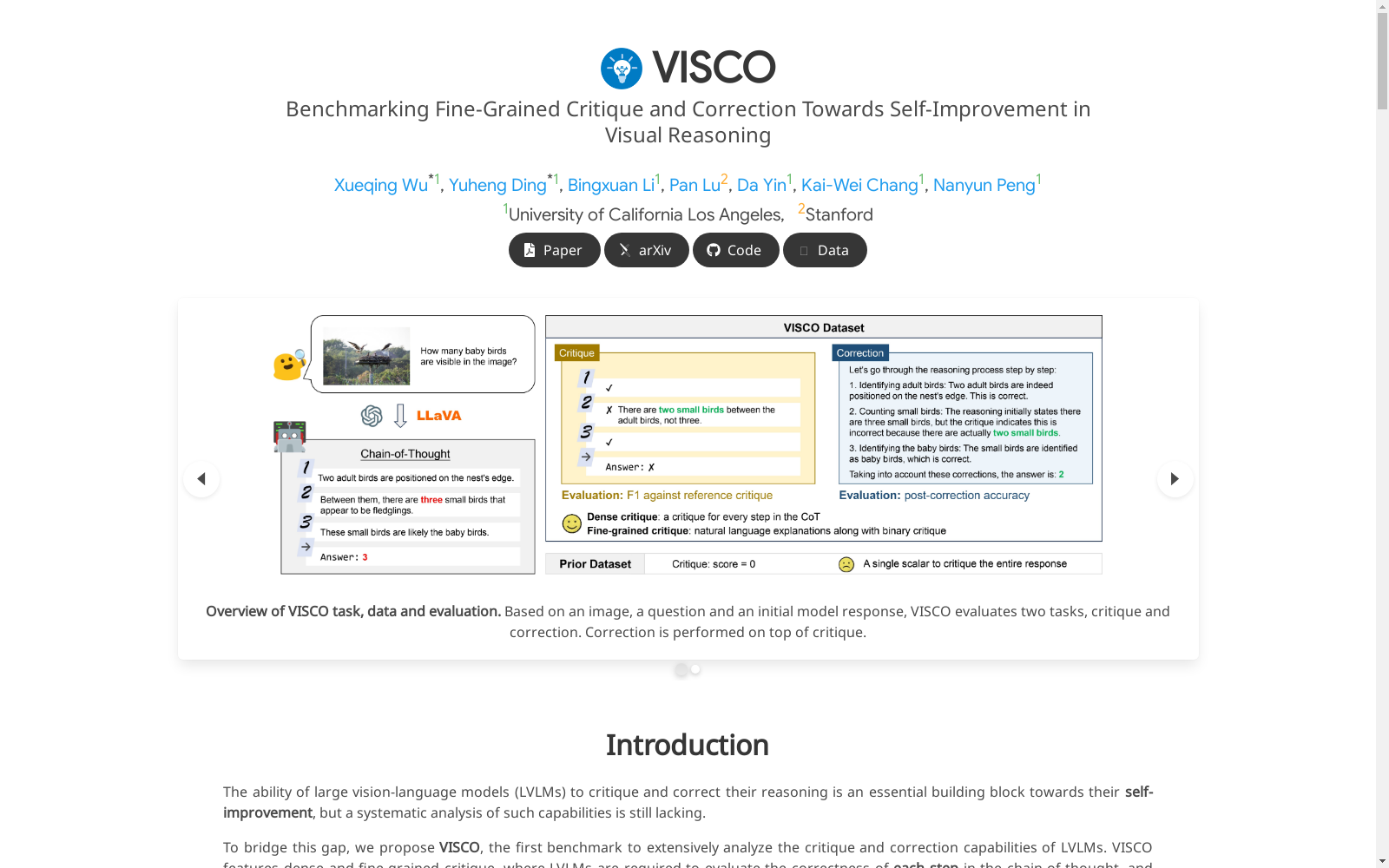
VISCO数据集由加州大学洛杉矶分校和斯坦福大学创建,是首个专注于视觉推理模型自我批评和修正能力的基准。该数据集包含1645个问题-答案对,涵盖18个数据集和8个任务,分为推理和感知两大类。每个问题-答案对都经过专家人工注释,提供详细的步骤级二元标签和自然语言解释。数据集的创建旨在系统分析和提升视觉推理模型的自我改进能力,特别是在数学推理和空间关系理解等领域。
The VISCO dataset, created by the University of California, Los Angeles (UCLA) and Stanford University, is the first benchmark focusing on the self-criticism and revision capabilities of visual reasoning models. This dataset consists of 1,645 question-answer pairs, covering 18 datasets and 8 tasks, and is categorized into two broad domains: reasoning and perception. Each question-answer pair has been manually annotated by experts, with detailed step-wise binary labels and natural language explanations provided. The dataset is developed to systematically analyze and enhance the self-improvement capabilities of visual reasoning models, particularly in domains such as mathematical reasoning and spatial relation understanding.
提供机构:
加州大学洛杉矶分校
创建时间:
2024-12-03
搜集汇总
数据集介绍
构建方式
VISCO数据集的构建旨在系统分析大型视觉语言模型(LVLMs)在细粒度批判和修正方面的能力。该数据集通过从现有的视觉问答(VQA)数据集中收集图像、问题和答案,并使用7种不同的LVLMs生成模型响应。随后,通过专家人工标注,对每个推理步骤进行二元正确性标签标注,并提供自然语言解释以支持判断。最终,数据集包含了1645个问题-答案对,共计5604个步骤级别的标注。
特点
VISCO数据集的显著特点在于其密集和细粒度的批判,要求LVLMs不仅评估整个推理链的正确性,还需对每个推理步骤进行详细评估,并提供自然语言解释。此外,数据集涵盖了广泛的8个任务和18个数据集,分为推理任务和感知任务两大类,确保了评估的全面性和多样性。
使用方法
VISCO数据集主要用于评估和提升LVLMs的自我改进能力。研究者可以通过该数据集测试模型在批判和修正任务中的表现,识别并解决模型在视觉感知和逻辑推理中的常见错误模式。此外,数据集还可用于训练和验证新的批判策略,如LOOKBACK,以提高模型的批判和修正能力。
背景与挑战
背景概述
随着大规模视觉语言模型(LVLMs)的最新进展,这些模型在解决数学和科学等复杂问题方面展现出强大的推理能力。然而,尽管采用了链式思维(CoT)方法,LVLMs在处理组合概念时仍容易出现幻觉和推理错误,这引发了对其视觉推理可靠性的担忧。为了系统地分析LVLMs在细粒度批评和自我修正方面的能力,VISCO数据集应运而生。VISCO由加州大学洛杉矶分校和斯坦福大学的研究人员于2024年创建,旨在通过密集和细粒度的批评,评估LVLMs在每个推理步骤中的正确性,并提供自然语言解释以支持其判断。该数据集的推出标志着对LVLMs自我改进能力进行全面研究的首次尝试,对提升视觉推理的可靠性和模型的自我修正能力具有重要意义。
当前挑战
VISCO数据集在构建过程中面临多个挑战。首先,如何生成完全准确的推理过程是一个难题,尤其是在处理视觉感知和复杂逻辑时。其次,模型在批评任务中表现出对视觉感知的批评困难、不愿说“不”以及对错误传播的夸大假设等常见失败模式。此外,模型生成的批评往往不如人类书写的批评有效,有时甚至会损害性能,这表明高质量批评的生成是自我改进的关键瓶颈。为了应对这些挑战,研究人员提出了LOOKBACK策略,通过重新审视图像来验证推理过程中的每一条信息,从而显著提高批评和修正的性能。
常用场景
经典使用场景
VISCO数据集在视觉推理领域中被广泛用于评估大型视觉语言模型(LVLMs)的细粒度批判和自我修正能力。通过提供密集且细粒度的批判,VISCO要求LVLMs评估链式思维中每一步的正确性,并提供自然语言解释以支持其判断。这种设计使得VISCO成为研究LVLMs自我改进策略的理想平台。
衍生相关工作
基于VISCO数据集,许多相关工作已经展开,特别是在改进LVLMs的批判和修正能力方面。例如,LOOKBACK策略通过重新审视图像来验证初始推理中的每一条信息,显著提高了批判和修正的性能。此外,还有研究致力于通过专门训练来增强LVLMs的批判能力,这些工作都受到了VISCO的启发和指导。
数据集最近研究
最新研究方向
在视觉推理领域,VISCO数据集的最新研究聚焦于大型视觉语言模型(LVLMs)的自我改进能力。具体而言,研究者们通过引入细粒度的批判和修正机制,探索了LVLMs在自我批判和自我修正方面的潜力。这一方向的研究不仅揭示了LVLMs在视觉感知和逻辑推理中的常见错误模式,如视觉感知错误、不愿否定和错误传播的夸大假设,还提出了LOOKBACK策略以提升模型的批判和修正性能。这些研究为提升视觉推理模型的可靠性和自我改进能力提供了新的视角和方法。
相关研究论文
- 1VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning加州大学洛杉矶分校 · 2024年
以上内容由遇见数据集搜集并总结生成


