ski-resort-synth-qwen
收藏Hugging Face2026-01-21 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen
下载链接
链接失效反馈官方服务:
资源简介:
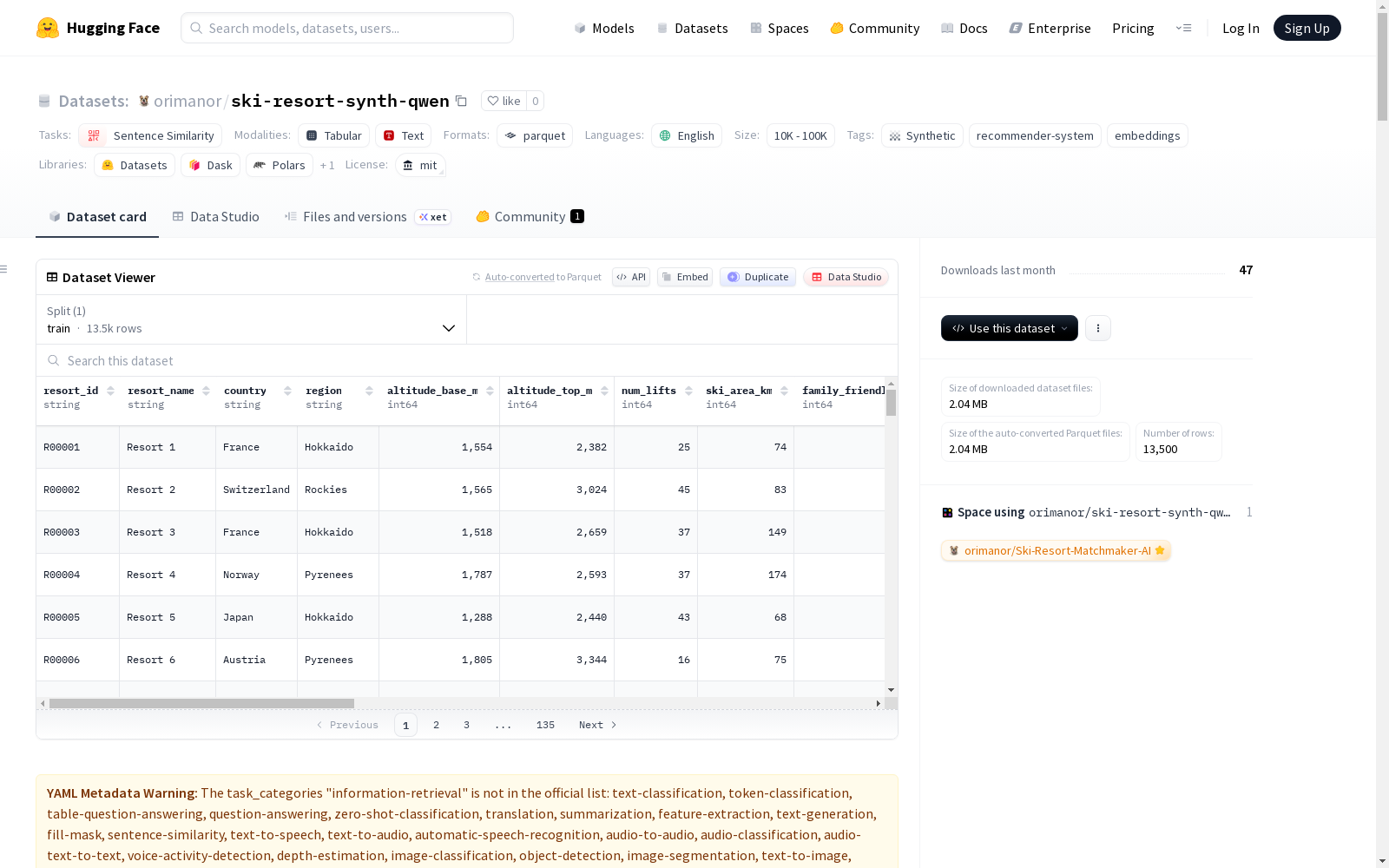
这是一个合成的滑雪胜地数据集,使用Qwen2.5-1.5B-Instruct模型生成。数据集包含3000个滑雪胜地和10500个用户查询。数据集分为两个部分:'resorts'(包含滑雪胜地的元数据和描述)和'users'(包含用户偏好和文本)。数据集提供了详细的文本长度统计、分类分布(如价格水平、技能水平、预算、旅行风格和地区)以及数值摘要(如海拔、滑雪面积、雪可靠性等)。该数据集主要用于信息检索和句子相似性任务。
创建时间:
2026-01-20
原始信息汇总
数据集概述
基本信息
- 数据集名称: Ski Resort Synthetic Dataset (Qwen2.5-1.5B-Instruct)
- 许可证: mit
- 任务类别: 信息检索、句子相似度
- 语言: 英语
- 标签: 合成、推荐系统、嵌入
数据构成
- 生成方式: 使用 Qwen2.5-1.5B-Instruct 模型生成的合成数据集。
- 滑雪场数量: 3000
- 用户查询数量: 10500
数据划分
resorts: 包含滑雪场元数据和resort_description。users: 包含用户偏好和user_text。
探索性数据分析摘要
文本长度统计
-
滑雪场描述统计:
- 数量: 3000
- 空值: 0
- 最小长度: 316
- 中位数 (p50): 492
- 90分位数 (p90): 550
- 最大长度: 642
- 重复项: 0
-
用户查询统计:
- 数量: 10500
- 空值: 0
- 最小长度: 100
- 中位数 (p50): 302
- 90分位数 (p90): 386
- 最大长度: 489
- 重复项: 0
分类分布
-
滑雪场 - 价格等级:
- 中档: 1019
- 经济型: 1010
- 高端: 971
-
用户 - 技能水平:
- 初学者: 3522
- 高级: 3498
- 中级: 3480
-
用户 - 预算:
- 经济型: 3550
- 高端: 3505
- 中档: 3445
-
用户 - 旅行风格:
- 运动型: 2195
- 安静型: 2178
- 聚会型: 2060
- 家庭型: 2046
- 奢华型: 2021
-
滑雪场 - 地区:
- 北海道: 455
- 阿尔卑斯: 443
- 比利牛斯: 433
- 落基山脉: 425
- 斯堪的纳维亚: 421
- 高加索: 418
- 多洛米蒂: 405
数值摘要(滑雪场)
| 字段 | 数量 | 均值 | 标准差 | 最小值 | 25%分位数 | 中位数 | 75%分位数 | 最大值 |
|---|---|---|---|---|---|---|---|---|
| altitude_base_m | 3000.0 | 1397.509333 | 286.832722 | 900.0 | 1150.00 | 1394.0 | 1645.25 | 1899.0 |
| altitude_top_m | 3000.0 | 2546.175667 | 427.932478 | 1524.0 | 2247.75 | 2533.5 | 2846.25 | 3579.0 |
| num_lifts | 3000.0 | 31.618667 | 14.017563 | 8.0 | 20.00 | 32.0 | 44.00 | 55.0 |
| ski_area_km | 3000.0 | 116.998333 | 60.621316 | 12.0 | 66.00 | 117.0 | 169.00 | 220.0 |
| party_apres_ski | 3000.0 | 5.010333 | 3.150693 | 0.0 | 2.00 | 5.0 | 8.00 | 10.0 |
| snow_reliability | 3000.0 | 6.569667 | 2.273661 | 3.0 | 5.00 | 7.0 | 9.00 | 10.0 |
| crowd_level_peak | 3000.0 | 5.937000 | 2.590354 | 2.0 | 4.00 | 6.0 | 8.00 | 10.0 |
| ski_school_quality | 3000.0 | 6.556333 | 2.308666 | 3.0 | 4.00 | 7.0 | 9.00 | 10.0 |
| off_piste_score | 3000.0 | 5.000000 | 3.125261 | 0.0 | 2.00 | 5.0 | 8.00 | 10.0 |
| scenery_score | 3000.0 | 7.011333 | 1.973787 | 4.0 | 5.00 | 7.0 | 9.00 | 10.0 |
| airport_access_mins | 3000.0 | 124.925000 | 69.430730 | 45.0 | 60.00 | 120.0 | 180.00 | 240.0 |
图表
- https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen/raw/main/eda_plots/resorts_airport_access.png
- https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen/raw/main/eda_plots/resorts_price_level.png
- https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen/raw/main/eda_plots/resorts_ski_area_km.png
- https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen/raw/main/eda_plots/resorts_snow_reliability.png
- https://huggingface.co/datasets/orimanor/ski-resort-synth-qwen/raw/main/eda_plots/users_apres_preference.png
加载方式
python from datasets import load_dataset
repo_id = "orimanor/ski-resort-synth-qwen" resorts = load_dataset(repo_id, data_dir="resorts", split="train") users = load_dataset(repo_id, data_dir="users", split="train")
搜集汇总
数据集介绍
构建方式
在滑雪度假推荐系统的研究领域中,数据集的构建往往面临真实用户偏好数据稀缺的挑战。该数据集采用先进的合成数据生成技术,依托Qwen2.5-1.5B-Instruct大型语言模型,系统性地生成了涵盖3000个虚构滑雪度假村与10500条用户查询的配对信息。构建过程模拟了真实推荐场景,为每个度假村生成了包含价格水平、地理区域、海拔高度、滑雪面积等多维度结构化元数据,并辅以详尽的文本描述;同时,为每位用户生成了包含技能水平、预算、旅行风格等偏好特征的文本查询,确保了数据在语义与统计分布上的丰富性与合理性。
特点
本数据集的核心特点在于其高度结构化与语义丰富的合成性质。数据被清晰地划分为‘resorts’与‘users’两个独立子集,分别对应度假村属性与用户偏好。度假村数据囊括了从基础海拔到雪场可靠性评分等十余个关键数值特征,并伴有细致的分类标签;用户数据则覆盖了技能等级、预算区间及旅行风格等多种维度。所有文本字段均无缺失值与重复项,且长度分布经过精心控制,确保了数据质量。其合成来源使得数据在规避隐私问题的同时,具备了可控的多样性与平衡的类别分布,为信息检索与语义相似性任务提供了理想的基准测试平台。
使用方法
在信息检索与个性化推荐系统的开发与评估中,本数据集提供了便捷的加载方式。研究者可通过Hugging Face的`datasets`库,指定对应的仓库标识符与数据目录,分别加载度假村与用户两个子集。加载后的数据可直接用于训练或测试嵌入模型、检索系统以及推荐算法。典型应用场景包括:基于度假村描述与用户查询文本的语义匹配、结合结构化特征与文本信息的混合推荐模型构建,以及对推荐系统公平性与多样性等前沿问题的量化研究。其清晰的划分与丰富的特征为多角度、深层次的算法实验奠定了坚实基础。
背景与挑战
背景概述
在信息检索与推荐系统领域,高质量的合成数据集对于模型训练与评估至关重要。Ski Resort Synthetic Dataset (Qwen2.5-1.5B-Instruct) 由研究者或机构利用先进的Qwen2.5-1.5B-Instruct模型生成,专注于滑雪度假村推荐场景。该数据集创建于近期,旨在解决个性化旅游推荐中的核心问题,即如何基于用户偏好与度假村属性实现精准匹配。通过涵盖3000个度假村和10500条用户查询,它整合了丰富的元数据,如价格水平、技能等级、行程风格及地理区域,为推荐算法和嵌入模型的研究提供了标准化基准,推动了旅游信息检索领域的发展。
当前挑战
该数据集致力于解决滑雪度假村个性化推荐这一领域问题,其挑战在于如何准确建模用户的多维度偏好与度假村的复杂属性之间的非线性关系,例如平衡预算、技能水平与雪场可靠性等因素。在构建过程中,挑战主要源于合成数据的生成与验证:确保由大语言模型生成的度假村描述和用户查询在语义上连贯、多样且无偏见,同时保持数值属性如海拔、滑雪面积等的统计合理性。此外,数据分布需反映真实世界的多样性,避免合成数据固有的模式重复或离群值问题,这对后续模型的泛化能力构成考验。
常用场景
经典使用场景
在信息检索与推荐系统领域,该数据集为滑雪度假村个性化推荐提供了理想的实验平台。通过合成生成的3000个度假村元数据与10500条用户查询,研究者能够模拟真实场景下的用户偏好匹配过程。经典使用场景涉及构建嵌入模型,将度假村的描述文本与用户的需求文本映射到同一向量空间,从而计算语义相似度,实现基于内容的精准推荐。
解决学术问题
该数据集有效解决了推荐系统中冷启动、数据稀疏性以及跨模态语义对齐等核心学术问题。通过提供结构化的度假村属性(如价格等级、雪况可靠性)与丰富的文本描述,它支持端到端的嵌入学习研究,促进了对用户意图理解与项目特征表示之间关联机制的探索。其合成性质确保了数据可控性与可扩展性,为算法鲁棒性评估与可解释性研究提供了坚实基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在深度语义匹配与个性化排序算法的创新上。例如,研究者利用其文本对信息开发了基于Transformer的孪生网络架构,以增强用户查询与度假村描述的交互表示。同时,结合分类与数值特征的混合嵌入方法也被广泛探索,推动了多模态推荐系统在旅游领域的进展,并为合成数据在信息检索任务中的有效性验证提供了实证案例。
以上内容由遇见数据集搜集并总结生成


