davanstrien/ml-kge
收藏Hugging Face2023-12-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/davanstrien/ml-kge
下载链接
链接失效反馈官方服务:
资源简介:
MKGE(多语言知识图谱增强)数据集旨在通过自动方法增加多语言知识图谱中实体名称的覆盖率和精确度,特别是在非英语语言中。数据集包含10种语言的实体名称,并提供了人类标注的数据和自动预测的数据。具体任务包括增加多语言知识图谱中本地化事实的覆盖率和精确度。数据集的组织结构包括人类标注的数据、M-NTA预测的数据、GPT模型预测的数据以及来自Wikidata的数据。
The MKGE (Multilingual Knowledge Graph Enhancement) dataset aims to improve the coverage and precision of entity names in multilingual knowledge graphs, especially for non-English languages, via automated methods. The dataset contains entity names across 10 languages, and provides both human-annotated data and automatically predicted data. Its core tasks focus on enhancing the coverage and precision of localized facts in multilingual knowledge graphs. The dataset is structured with four components: human-annotated data, M-NTA predicted data, GPT model-predicted data, and data sourced from Wikidata.
提供机构:
davanstrien
原始信息汇总
MKGE: Multilingual Knowledge Graph Enhancement
数据集概述
- 名称: MKGE: Multilingual Knowledge Graph Enhancement
- 标签: knowledge-graphs
- 大小类别: n<1K
- 许可: cc-by-sa-4.0
- 语言:
- 英语 (en)
- 阿拉伯语 (ar)
- 德语 (de)
- 西班牙语 (es)
- 法语 (fr)
- 意大利语 (it)
- 日语 (ja)
- 韩语 (ko)
- 俄语 (ru)
- 中文 (zh)
数据集配置
- gold: 包含人工 curated 的数据,路径为
data/names/gold/*.json - m-nta-with_gpt-3.5: 包含使用 GPT-3.5 的 M-NTA 预测数据,路径为
data/names/m-nta/with_gpt-3.5/*.json - m-nta-with_gpt-3: 包含使用 GPT-3 的 M-NTA 预测数据,路径为
data/names/m-nta/with_gpt-3/*.json - m-nta-with_gpt-4: 包含使用 GPT-4 的 M-NTA 预测数据,路径为
data/names/m-nta/with_gpt-4/*.json - gpt: 包含 GPT-3 和 GPT-3.5 的预测数据,路径为
data/names/gpt/*.json - wikidata: 包含来自 Wikidata 的数据,路径为
data/names/wikidata/*.json
任务描述
- 目标: 评估自动方法在两个子任务中的表现:
- 增加多语言知识图谱中地区特定事实的覆盖率
- 增加多语言知识图谱中地区特定事实的精确度
- 具体内容: 使用 Wikidata 作为参考多语言知识图谱,重点关注实体名称,这些名称在不同语言中可能有不同的表示方式。
WikiKGE-10
- 描述: WikiKGE-10 是一个用于评估自动方法在增加 Wikidata 中实体名称覆盖率和精确度的基准,涵盖 10 种语言。
- 语言:
- 阿拉伯语 (ar)
- 德语 (de)
- 英语 (en)
- 西班牙语 (es)
- 法语 (fr)
- 意大利语 (it)
- 日语 (ja)
- 韩语 (ko)
- 俄语 (ru)
- 简体中文 (zh)
- 数据组织:
data/names/gold/: 包含人工 curated 的数据data/names/m-nta/: 包含 M-NTA 的预测数据data/names/gpt/: 包含 GPT-3 和 GPT-3.5 的预测数据data/names/wikidata/: 包含来自 Wikidata 的数据
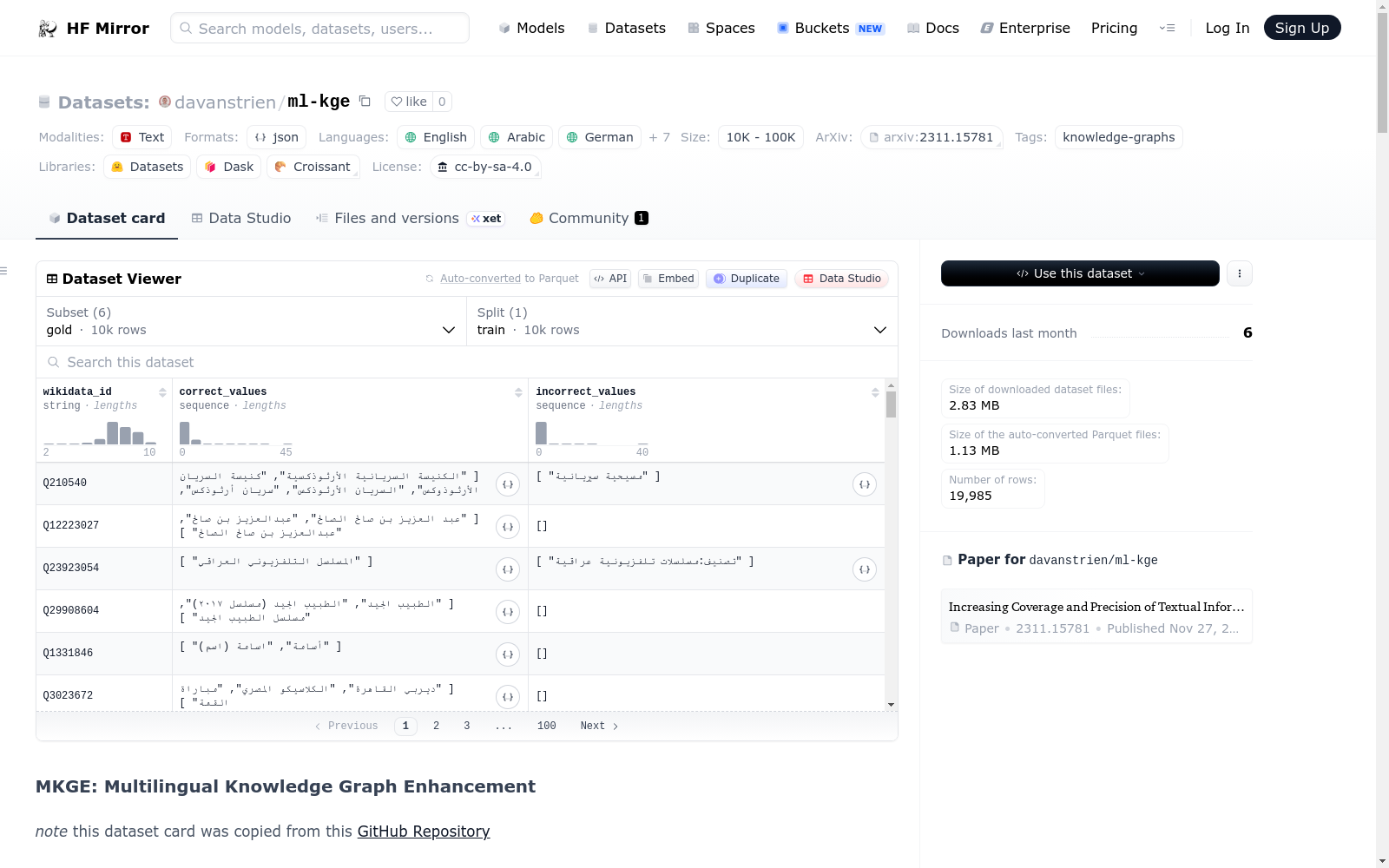
数据示例
-
人工 curated 数据: json { "wikidata_id": "Q48324", "correct_values": ["morale", "moralità", "Moralismo"], "incorrect_values": ["giudizio morale", "moralita", "legge morale"] }
-
M-NTA 预测数据: json { "wikidata_id": "Q48324", "values": [ [1, "Egenetica", false], [1, "Immorale", false], [1, "Immoralità", false], [1, "Morali", false], [1, "Moralismo", false], [1, "Moralità pubblica", false], [1, "Moralmente", false], [1, "Parenesi", false], [1, "Pubblica moralità", false], [1, "Regola morale", false], [1, "Teoria dei costumi", false], [4, "Morale", true], [4, "Moralità", true] ] }
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个多语言知识图谱增强(MKGE)的数据集,覆盖10种语言,旨在通过自动方法提升知识图谱中实体名称的覆盖范围和精确度。数据集包含人类标注的数据和模型预测结果,适用于自然语言处理和多语言知识图谱研究。
以上内容由遇见数据集搜集并总结生成


