AMI Meeting Corpus
收藏arXiv2025-09-30 收录
下载链接:
https://groups.inf.ed.ac.uk/ami/corpus
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个用于会议分析的多模态语料库,包含了在不同条件下录制的音频、视频和文本转录资料。此外,该语料库被用于评估所提出方法在自动语音识别(ASR)任务中的性能表现。该数据集规模涵盖了2000个混响语音样本。
This dataset is a multimodal corpus for meeting analysis, containing audio, video recordings and text transcriptions recorded under various conditions. Moreover, it is utilized to evaluate the performance of the proposed method on the Automatic Speech Recognition (ASR) task. This dataset comprises 2000 reverberant speech samples.
提供机构:
AMI Consortium
搜集汇总
数据集介绍
背景与挑战
背景概述
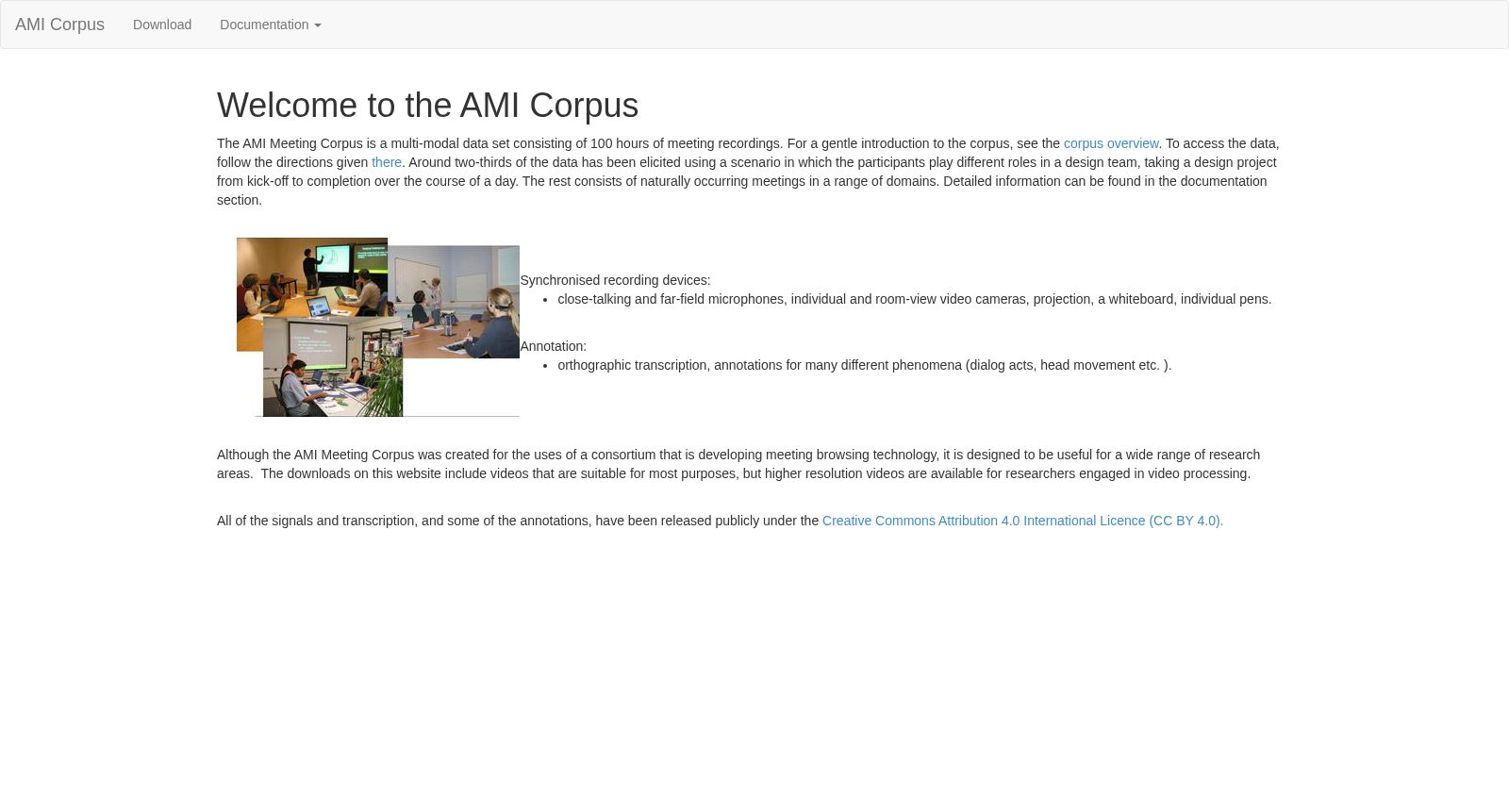
AMI Meeting Corpus是一个包含100小时多模态会议录音的数据集,采集了多种设备信号和丰富的标注信息,采用场景设计和自然会议两种形式,适用于会议浏览技术和多模态研究领域。
以上内容由遇见数据集搜集并总结生成


