allenai/WildChat-1M
收藏Hugging Face2024-07-19 更新2024-05-18 收录
下载链接:
https://hf-mirror.com/datasets/allenai/WildChat-1M
下载链接
链接失效反馈官方服务:
资源简介:
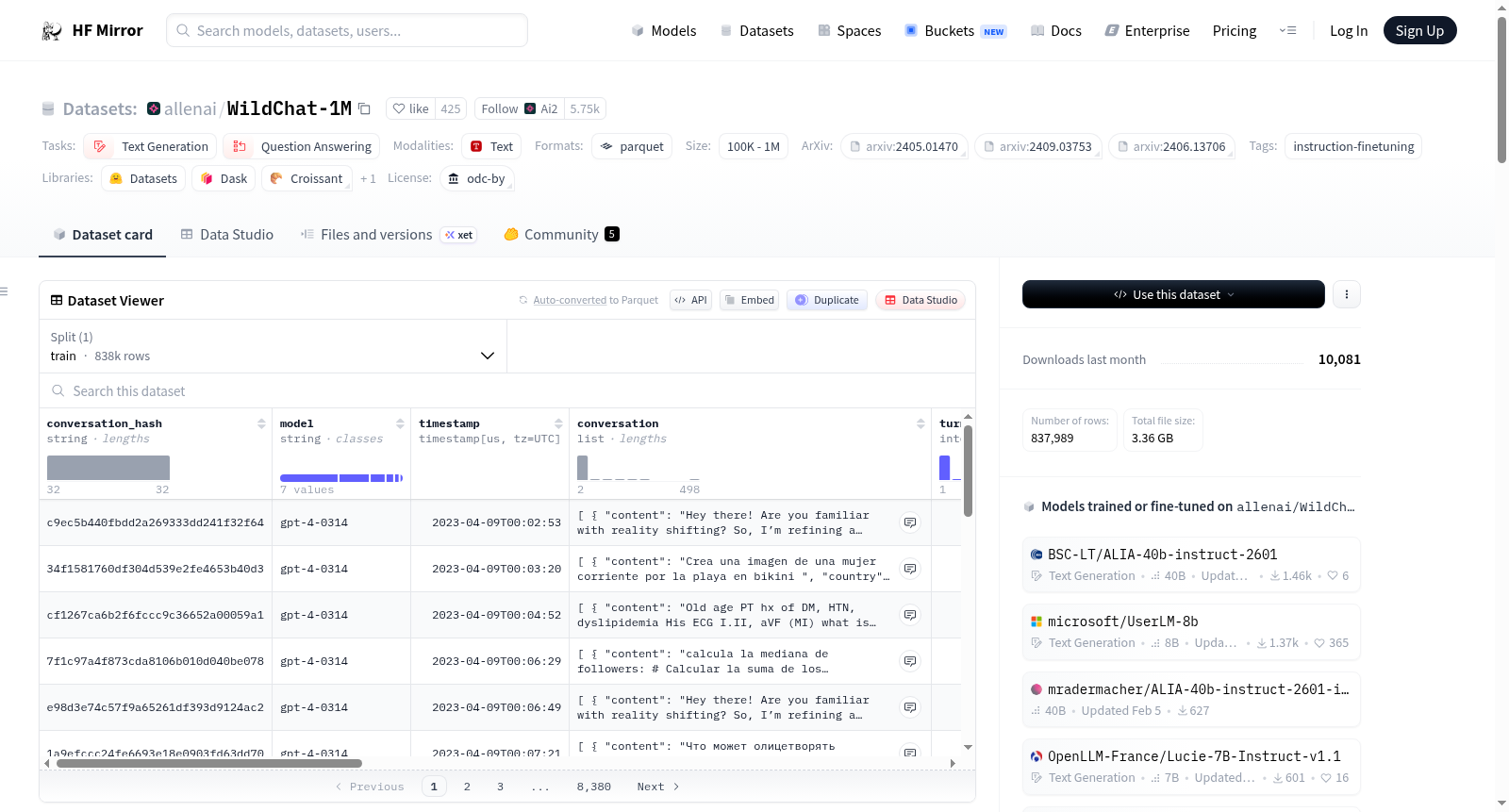
WildChat数据集包含了100万条人类用户与ChatGPT之间的对话,以及相关的用户人口统计数据,如州、国家、哈希IP地址和请求头信息。数据集中的对话涵盖了广泛的用户与ChatGPT的交互场景,包括模糊的用户请求、代码切换、话题切换、政治讨论等。数据集中的对话来自GPT-3.5和GPT-4模型,其中25.53%的对话来自GPT-4。数据集还包含了OpenAI Moderation和Detoxify的审核结果,用于标记对话中的毒性内容。此外,数据集中的个人信息已经通过Microsoft Presidio和作者手写的规则进行了去标识化处理。
WildChat-1M is a dataset containing 1 million conversations between human users and ChatGPT, accompanied by demographic data including state, country, hashed IP addresses, and request headers. The dataset is multi-lingual, covering interactions in 68 languages. It includes both toxic and non-toxic user inputs and ChatGPT responses, encompassing a wide range of user behaviors and interactions such as ambiguous requests, code-switching, topic-switching, and political discussions. The data has been de-identified to protect personal and sensitive information. The dataset is suitable for instructional fine-tuning and studying user behaviors.
提供机构:
allenai
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,大规模对话数据对于模型训练至关重要。WildChat-1M数据集的构建源于对真实用户与ChatGPT交互日志的系统性采集。研究团队通过向在线用户免费提供GPT-3.5和GPT-4的访问权限,收集了超过一百万条对话记录,其中GPT-4的对话占比约为25.53%。数据采集过程中,团队运用了Microsoft Presidio工具及人工规则对个人身份信息进行去标识化处理,并采用OpenAI Moderation API与Detoxify工具对毒性内容进行标注与筛选,最终版本已移除所有被标记为有毒的对话内容。
使用方法
作为指令微调与用户行为研究的宝贵资源,WildChat-1M数据集支持多种自然语言处理任务。研究者可借助其多轮对话结构进行文本生成与问答系统的训练,利用丰富的元数据字段分析跨地域、跨语言的用户交互模式。数据集中每个话轮均包含唯一标识符与角色标注,便于构建监督式微调或强化学习框架。对于需要毒性内容的研究,可申请访问完整版本数据集。使用时应遵循ODC-BY许可协议,并参考提供的交互式可视化工具进行探索性分析,以深入理解数据分布与潜在应用场景。
背景与挑战
背景概述
在人工智能对话系统迅猛发展的背景下,为深入探究真实场景中的人机交互模式,艾伦人工智能研究所于2024年推出了WildChat-1M数据集。该数据集由Wenting Zhao、Yuntian Deng等研究人员主导构建,核心研究问题聚焦于捕捉并分析用户与大型语言模型在开放环境下的自然对话行为。其收录了超过一百万条用户与ChatGPT的互动记录,并附有详尽的地理与设备元数据,旨在为指令微调与用户行为研究提供前所未有的真实语料。该数据集的发布,显著推动了对话系统评估与安全对齐领域的研究,为理解模型在复杂、多语言及多文化语境中的表现奠定了坚实基础。
当前挑战
WildChat-1M旨在解决开放域对话系统在真实世界部署中所面临的核心挑战,即如何获取并利用反映人类真实意图与行为的多样化、大规模交互数据。在构建过程中,研究团队遭遇了多重技术与管理难题。首要挑战在于数据收集的伦理与隐私保护,需通过哈希处理IP地址、应用微软Presidio工具及人工规则对个人身份信息进行严格脱敏。其次,内容安全过滤极具复杂性,需整合OpenAI审核API与Detoxify工具以精准识别并剔除有害对话,同时平衡数据完整性与安全性。此外,处理多语言混合、话题转换及用户提交空输入等非典型交互场景,也对数据清洗与标注流程提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,大规模对话数据的稀缺性长期制约着对话模型的深度优化。WildChat-1M作为真实世界用户与ChatGPT的交互日志集合,其经典应用场景在于为指令微调提供丰富且多样化的训练样本。该数据集涵盖了多语言环境下的复杂对话模式,如模糊请求、代码转换及话题切换等,使得研究者能够基于真实用户行为数据,训练出更具鲁棒性和泛化能力的对话生成模型。
解决学术问题
该数据集有效解决了对话系统研究中真实交互数据匮乏的学术难题。通过提供百万级带有地理、语言及毒性标注的对话记录,WildChat-1M支持对用户行为模式、跨文化对话差异以及内容安全过滤机制的深入探究。其精细的结构化字段为理解人机交互的动态过程提供了实证基础,推动了对话生成、社会计算及人工智能伦理等交叉学科的发展。
实际应用
在实际应用层面,WildChat-1M为商业对话系统的优化提供了关键数据支撑。企业可借助该数据集分析用户真实意图分布,改进对话流程设计;教育机构能利用其多语言特性开发适应性学习工具;内容审核平台则可参考其毒性标注数据,训练更精准的安全过滤模型。这些应用显著提升了智能客服、个性化助手及在线社区管理等场景的服务质量与安全性。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模对话数据集正成为推动大语言模型安全与对齐研究的关键资源。WildChat-1M作为涵盖百万级真实用户与ChatGPT交互的语料库,其前沿研究聚焦于多语言环境下的用户行为分析与模型安全评估。该数据集通过集成地理信息、语言多样性及毒性内容标注,为探究跨文化对话模式、识别潜在偏见与有害内容提供了实证基础。相关热点事件如生成式AI在新闻领域的应用引发的隐私与伦理讨论,进一步凸显了此类数据在内容审核与去身份化技术开发中的重要性。WildChat-1M的开放不仅促进了指令微调技术的优化,也为构建更安全、包容的对话系统奠定了数据基石,对推动人工智能的社会化应用具有深远意义。
以上内容由遇见数据集搜集并总结生成


