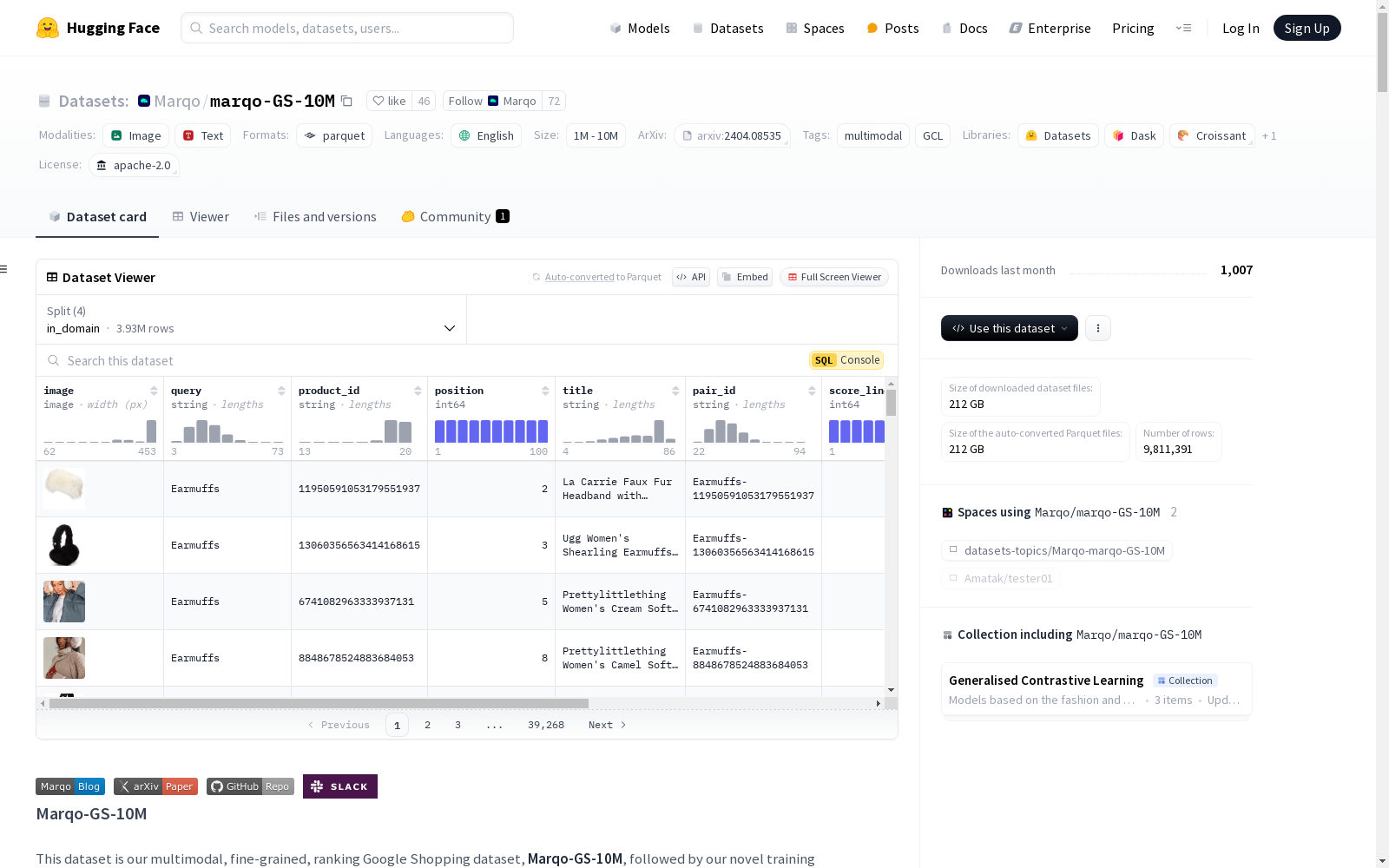
marqo-GS-10M
收藏Marqo-GS-10M 数据集概述
数据集信息
- 许可证: Apache 2.0
- 语言: 英语
- 标签: 多模态, GCL
- 大小类别: 1M < n < 10M
- 特征:
image: 图像query: 字符串product_id: 字符串position: 整数title: 字符串pair_id: 字符串score_linear: 整数score_reciprocal: 浮点数no_score: 整数query_id: 字符串
配置
- 默认配置:
in_domain: data/in_domain-*novel_document: data/novel_document-*novel_query: data/novel_query-*zero_shot: data/zero_shot-*
数据集结构
-
目录结构:
marqo-gs-dataset/ ├── marqo_gs_full_10m/ │ ├── corpus_1.json │ ├── corpus_2.json │ ├── query_0_product_id_0.csv │ ├── query_0_product_id_0_gt_dev.json │ ├── query_0_product_id_0_gt_test.json │ ├── query_0_product_id_0_queries.json │ ├── query_0_product_id_1.csv │ ├── query_0_product_id_1_gt_dev.json │ ├── query_0_product_id_1_gt_test.json │ ├── query_0_product_id_1_queries.json │ ├── query_1_product_id_0.csv │ ├── query_1_product_id_0_gt_dev.json │ ├── query_1_product_id_0_gt_test.json │ ├── query_1_product_id_0_queries.json │ ├── query_1_product_id_1.csv │ ├── query_1_product_id_1_gt_dev.json │ ├── query_1_product_id_1_gt_test.json │ └── query_1_product_id_1_queries.json ├── marqo_gs_fashion_5m/ ├── marqo_gs_wfash_1m/
数据集下载
数据集可视化
- 示例: 包含搜索查询、文档和分数的收集三元组数据集的可视化,展示了返回产品的缩略图及其线性递减的分数。
使用说明
-
环境安装: bash conda create -n gcl python=3.8 conda activate gcl conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia pip install jupyterlab pandas matplotlib beir pytrec_eval braceexpand webdataset wandb notebook open_clip_torch pip install --force-reinstall numpy==1.23.2
-
评估: bash python change_image_paths.py /dataset/csv/dir/path /image/root/path bash ./scripts/eval-vitb32-ckpt.sh
模型下载
- 多模态/文本-图像:
- 文本:
引用
@misc{zhu2024generalized, title={Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking}, author={Tianyu Zhu and Myong Chol Jung and Jesse Clark}, year={2024}, eprint={2404.08535}, archivePrefix={arXiv}, primaryClass={cs.IR} }