EdinburghNLP/xsum
收藏Hugging Face2026-01-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/EdinburghNLP/xsum
下载链接
链接失效反馈资源简介:
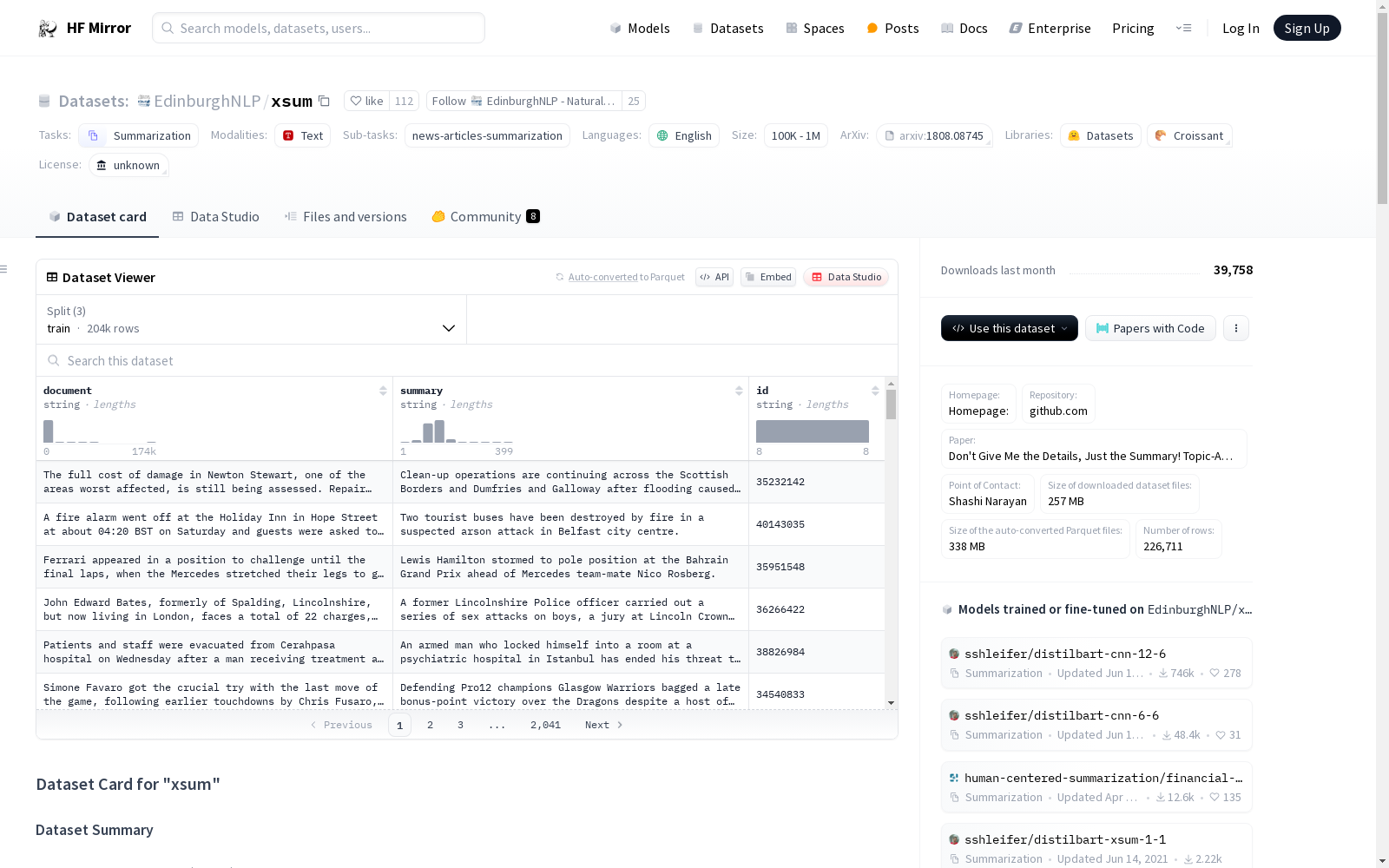
Extreme Summarization (XSum)数据集是一个用于新闻文章极端摘要任务的数据集。它包含三个特征:文档(输入新闻文章)、摘要(文章的一句话摘要)和ID(文章的BBC ID)。数据集分为训练集、验证集和测试集,分别包含204045、11332和11334个样本。数据集的下载大小为257.30 MB,生成数据集大小为532.26 MB,总磁盘使用量为789.56 MB。
The Extreme Summarization (XSum) dataset is a benchmark dataset for extreme summarization tasks on news articles. It includes three core features: document (the input news article), summary (the single-sentence summary of the article), and ID (the BBC ID associated with the article). The dataset is split into training, validation, and test sets, containing 204,045, 11,332, and 11,334 samples respectively. The download size of the XSum dataset is 257.30 MB, the generated dataset size is 532.26 MB, and the total disk usage amounts to 789.56 MB.
提供机构:
EdinburghNLP
原始信息汇总
数据集卡片:Extreme Summarization (XSum)
数据集描述
数据集摘要
Extreme Summarization (XSum) 数据集包含以下特征:
document:输入的新闻文章。summary:文章的一句话摘要。id:BBC 文章的 ID。
支持的任务和排行榜
语言
数据集结构
数据实例
默认配置
- 下载的数据集文件大小: 257.30 MB
- 生成的数据集大小: 532.26 MB
- 总磁盘使用量: 789.56 MB
一个 validation 样本示例如下: json { "document": "some-body", "id": "29750031", "summary": "some-sentence" }
数据字段
所有分割的数据字段相同:
默认配置
document:一个string特征。summary:一个string特征。id:一个string特征。
数据分割
| 名称 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| 默认配置 | 204045 | 11332 | 11334 |
数据集创建
策划理由
源数据
初始数据收集和规范化
源语言生产者
注释
注释过程
注释者
个人和敏感信息
使用数据集的注意事项
数据集的社会影响
偏见的讨论
其他已知限制
附加信息
数据集策划者
许可信息
引用信息
plaintext @article{Narayan2018DontGM, title={Dont Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization}, author={Shashi Narayan and Shay B. Cohen and Mirella Lapata}, journal={ArXiv}, year={2018}, volume={abs/1808.08745} }
贡献
感谢 @thomwolf, @lewtun, @mariamabarham, @jbragg, @lhoestq, @patrickvonplaten 为该数据集做出的贡献。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于对BBC新闻文章的深入分析,旨在实现极简文本摘要的生成。通过选取新闻文章作为输入文本(document),并提炼出一句概括性的摘要(summary),数据集进一步提供了文章的唯一标识符(id)。构建过程中,数据集的来源为原始数据,未经过多语言处理,保持了单语言(英语)的纯净性。
使用方法
使用XSum数据集时,用户可以根据数据集中的三个字段:文档内容、摘要和文档ID来构建和训练文本摘要模型。数据集的每个分割部分均可以直接用于机器学习模型的输入,通过遵循数据集中的字段映射,可以有效地将数据加载到模型中进行训练、验证和测试。需要注意的是,数据集的版权信息尚不明确,使用时需谨慎处理相关法律问题。
背景与挑战
背景概述
Extreme Summarization (XSum)数据集,由爱丁堡大学的Shashi Narayan等研究人员于2018年创建,专注于新闻文章的极端摘要任务,即从一篇完整的新闻文章中生成一句话摘要。该数据集的构建旨在推动自动文本摘要领域的研究,特别是在生成简洁、信息丰富的摘要方面。XSum数据集在学术界和工业界产生了广泛影响,为相关任务提供了宝贵的数据资源。
当前挑战
XSum数据集面临的挑战主要在于两个方面:一是数据集构建过程中,如何确保从大量新闻文章中提取的摘要具有高质量和相关性;二是所解决的领域问题,即在极端摘要的背景下,如何设计有效的模型以生成准确且信息量大的单句摘要,同时克服潜在的偏差和覆盖性问题。
常用场景
经典使用场景
在自然语言处理领域,极端摘要任务旨在将长篇文档压缩为仅包含关键信息的单句摘要。EdinburghNLP/xsum数据集为此提供了丰富的实例,其经典使用场景在于训练和评估摘要生成模型,以实现从输入新闻文章到生成单句摘要的高效映射。
解决学术问题
该数据集解决了学术研究中如何精确而高效地提取文本核心内容的问题,对于提升自动摘要的质量具有重要意义。通过该数据集,研究者可以训练模型以识别和保留文章中的关键信息,从而推动文本摘要技术的进步。
实际应用
在实际应用中,xsum数据集可用于新闻聚合平台的自动摘要生成,帮助用户快速获取信息要点。此外,它也可应用于教育、情报分析等领域,辅助快速筛选和解读大量文本资料。
数据集最近研究
最新研究方向
在自然语言处理领域,自动文摘技术一直是一个热门研究方向。EdinburghNLP的XSum数据集,专为极简文摘任务设计,旨在从长篇新闻文章中生成单句摘要。近期研究集中在如何通过深度学习模型捕捉文章的核心内容,并生成简洁而信息丰富的摘要。该数据集的应用不仅推动了新闻摘要自动化的发展,也为信息过载时代下快速获取关键信息提供了技术支持。随着模型性能的提升,XSum数据集在新闻传播、情报分析等领域的影响力日益增强。
以上内容由遇见数据集搜集并总结生成


