multilingual-gsm-symbolic
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://huggingface.co/datasets/danish-foundation-models/multilingual-gsm-symbolic
下载链接
链接失效反馈官方服务:
资源简介:
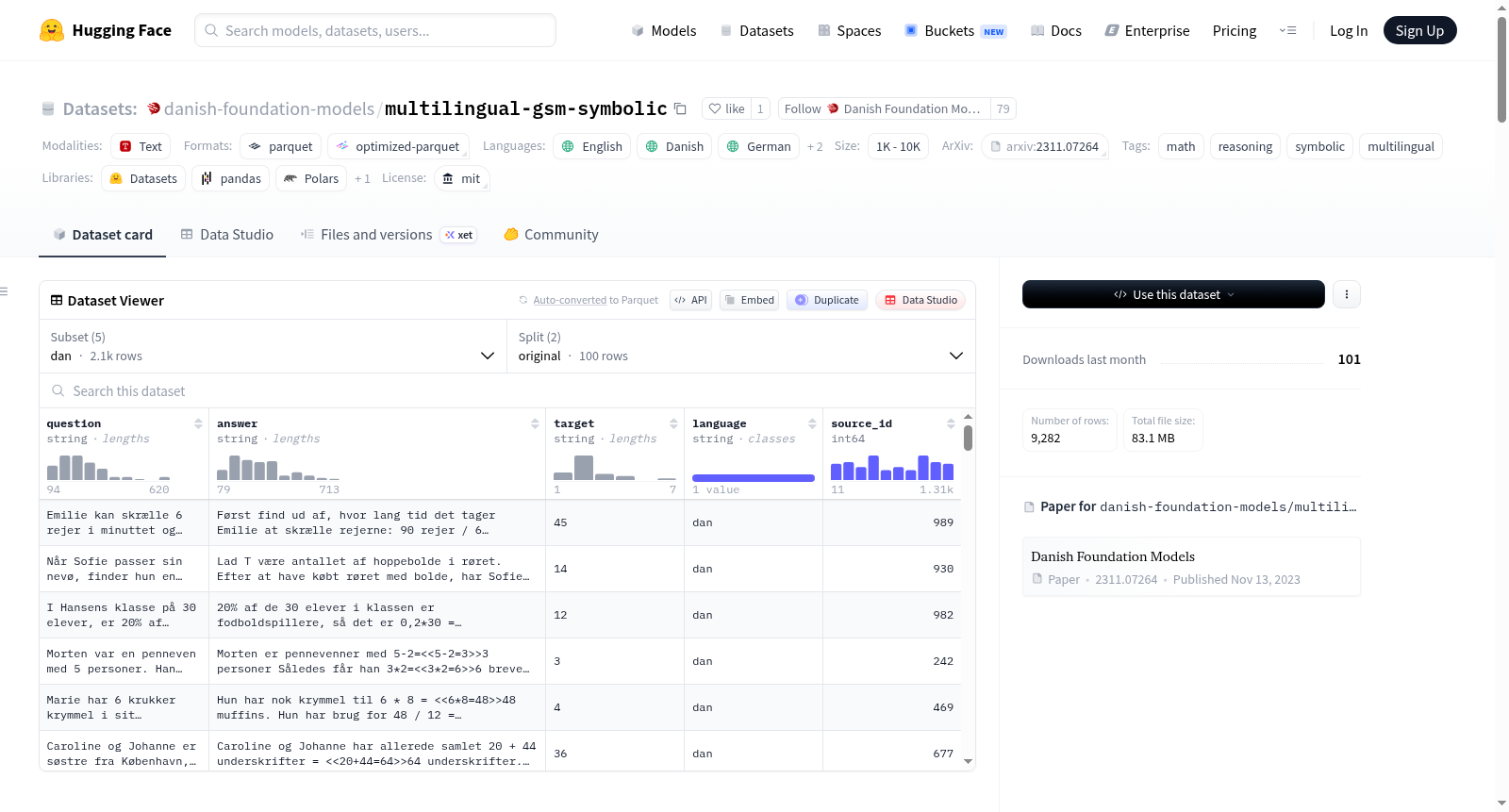
Multilingual GSM-Symbolic是一个用于评估大型语言模型在多语言环境下算术推理能力的基准数据集。该数据集扩展了Apple的GSM-Symbolic方法,通过提供符号模板生成数千个结构相同但数值不同的数学问题。数据集包含英语、丹麦语、挪威语、德语和冰岛语五种语言,每种语言都有原始(original)和合成(synthetic)两种分割。原始分割包含100个具体问题,合成分割则包含每个模板生成的20个变体(共2000个问题)。每个样本包含问题(question)、分步解答(answer)、最终答案(target)、语言代码(language)和原始数据集索引(source_id)等字段。该数据集特别适用于测试模型是真正理解问题还是仅仅记忆了训练时看到的特定数字模式,通过比较模型在原始和合成分割上的表现可以直接测量这种差距。
Multilingual GSM-Symbolic is a benchmark dataset designed to evaluate the arithmetic reasoning capabilities of large language models in multilingual contexts. The dataset extends Apples GSM-Symbolic approach by providing symbolic templates to generate thousands of math problems with identical structures but varying numerical values. It includes five languages: English, Danish, Norwegian, German, and Icelandic, each with two splits: original and synthetic. The original split contains 100 concrete problems, while the synthetic split includes 20 variants per template (totaling 2000 problems). Each sample contains fields such as question, step-by-step answer (answer), final answer (target), language code (language), and source dataset index (source_id). The dataset is particularly useful for testing whether models truly understand the problems or merely memorize specific numerical patterns seen during training, with the gap measurable by comparing performance on original versus synthetic splits.
创建时间:
2026-04-22
原始信息汇总
Multilingual GSM-Symbolic 数据集概述
基本信息
- 数据集名称: Multilingual GSM-Symbolic
- 许可证: MIT
- 语言覆盖: 英语(en)、丹麦语(da)、德语(de)、冰岛语(is)、挪威语(nb)
- 数据集规模: 1K < n < 10K
- 标签: 数学、推理、符号化、多语言
数据集用途
该数据集是一个用于评估大语言模型在多语言场景下算术推理能力的基准测试。它扩展了Apple的GSM-Symbolic方法,通过符号模板生成数千个结构等价但数值不同的数学问题,旨在检测模型是真正理解问题,还是仅仅对训练中见过的特定数字进行模式匹配。
数据集结构
每个语言对应一个独立的配置(config),每个配置包含两个拆分(split):
| 拆分 | 描述 | 样本数量 |
|---|---|---|
original |
该语言的100个具体GSM问题 | 100个问题 |
synthetic |
每个模板生成20个变体 | 2000个问题 |
数据字段
| 字段 | 类型 | 描述 |
|---|---|---|
question |
字符串 | 数学问题 |
answer |
字符串 | 分步解答,以#### <number>结尾 |
target |
字符串 | 最终数字答案(从answer中提取) |
language |
字符串 | 三字母语言代码(如eng、dan) |
source_id |
整数 | 在原始GSM8K数据集中的问题索引 |
答案格式
遵循GSM8K的格式,包含推理步骤和最终数字答案,例如:
在3英里/小时的速度下,雾需要42/3=14小时才能覆盖城市。
14
可用的配置与数据文件
数据集包含以下配置,每个配置包含original和synthetic两个拆分:
- eng(英语):
data/eng/original-*.parquet和data/eng/synthetic-*.parquet - dan(丹麦语):
data/dan/original-*.parquet和data/dan/synthetic-*.parquet - nob(挪威语):
data/nob/original-*.parquet和data/nob/synthetic-*.parquet - deu(德语):
data/deu/original-*.parquet和data/deu/synthetic-*.parquet - isl(冰岛语):
data/isl/original-*.parquet和data/isl/synthetic-*.parquet
评测结果(Using openai/gpt-5.4-nano)
| 语言 | 原始准确率 | 合成准确率 |
|---|---|---|
| 英语 | 90.0% | 75.2% |
| 丹麦语 | 83.2% | 70.2% |
| 德语 | — | — |
| 冰岛语 | — | — |
原始与合成准确率之间的差距反映了模型在新数字组合上的性能下降,可作为模型依赖记忆与真正推理的代理指标。
搜集汇总
数据集介绍
构建方式
Multilingual GSM-Symbolic数据集是对Apple公司GSM-Symbolic基准测试的多语言扩展,其核心构建方式依赖于符号化模板技术。这些模板能够自动生成大量结构等价但数值各异的数学问题,从而在保留问题逻辑骨架的同时,通过随机化具体数字来创建丰富的题目变体。数据集的构建遵循严格的人工验证流程,每个语言版本需要验证100个基础模板,确保翻译和数学逻辑的准确性。在此基础上,每个模板被扩展生成20个合成变体,最终形成每个语种包含100个原始问题和2000个合成问题的结构。数据集采用Parquet格式存储,分为原始(original)和合成(synthetic)两个分割,便于对比分析。
特点
该数据集最为突出的特点在于其多语言覆盖和符号化变体生成能力,涵盖英语、丹麦语、德语、冰岛语和挪威语五种语言。通过比较模型在原始问题与合成问题上的性能差异,能够有效衡量大语言模型是否真正理解数学推理逻辑,抑或仅仅是基于训练数据中的特定数字进行模式匹配。每个样本都包含完整的逐步推理过程和最终数值答案,遵循GSM8K的数据格式规范。此外,数据集支持通过原始问题与合成问题的准确率差距来量化模型对记忆的依赖程度,为评估模型推理鲁棒性提供了独特的度量维度。
使用方法
研究人员可以通过Hugging Face Datasets库便捷加载该数据集,只需指定语言配置名称(如eng、dan)和所需分割(original或synthetic)。对于使用inspect-ai框架的用户,可以通过命令行直接调用预定义的评估任务,支持选择特定语言和分割进行专项测试。数据集的回答遵循标准格式,包含以####符号结尾的最终数值答案,便于自动化提取和评分。用户也可以借助multilingual-gsm-symbolic开源包自行扩展新的语言版本,仅需完成100个模板的验证即可贡献新的语言配置,从而推动多语言数学推理研究的全球化发展。
背景与挑战
背景概述
在大型语言模型(LLM)的数学推理能力评估中,如何区分模型是否真正理解数学问题,还是仅仅依赖对训练数据中数字模式的记忆,已成为核心研究议题。为应对这一挑战,丹麦奥胡斯大学人文计算中心(Centre for Humanities Computing)的Kenneth Enevoldsen等研究人员于2024年构建了Multilingual GSM-Symbolic数据集。该数据集基于Apple的GSM-Symbolic方法,通过符号模板为英语、丹麦语、德语、冰岛语和挪威语生成数千个结构等价但数值各异的数学问题,旨在系统评估模型在跨语言环境下的算术推理能力。数据集的两种划分——原始问题与合成变体——可直接度量模型因数字变化而表现出的性能差距,为理解LLM的推理机制提供了精密的实验工具,在语言与推理交叉领域产生了重要影响。
当前挑战
该数据集核心解决的领域挑战在于揭示LLM数学推理中的虚假相关性与记忆依赖。许多模型在面对训练集内常见数字组合时表现优异,但一旦数字被合成替换,准确率显著下降(如英语原始90.0%降至合成75.2%),表明模型可能缺乏通用推理能力。构建过程中面临的挑战包括:设计可跨语言等效转换的符号模板,确保不同语言版问题在数学结构和难度上严格一致;对冰岛语、德语等小语种,需要逐条验证100个模板的本地化准确性,防止文化或语言差异导致语义偏差;此外,还需维护生成程序的鲁棒性,使两万个合成问题在数值随机性与逻辑完整性间取得平衡,从而避免引入系统性噪声。
常用场景
经典使用场景
在人工智能与自然语言处理领域,数学推理能力的评测长期依赖单一语言、固定数值的静态数据集。Multilingual GSM-Symbolic作为一项突破性的多语言算术推理基准,通过符号化模板生成大量结构等价但数值相异的数学问题,为评估大语言模型的泛化推理能力提供了严苛的试验场。该数据集涵盖英语、丹麦语、德语、挪威语及冰岛语五种语言,每个语言配置包含原始问题与合成问题两个子集,研究者可借此精准区分模型是真正理解解题逻辑,还是仅依赖训练数据中的数值模式进行机械匹配。
实际应用
在实际应用中,Multilingual GSM-Symbolic可服务于多语言教育智能辅导系统的开发与质检,帮助识别模型在跨语言场景下是否因语言差异而产生推理偏差。例如,丹麦语与德语版本可用于验证北欧及中欧地区本地化数学助手的可靠性,确保其在不同语种下均能稳定输出正确的解题步骤。此外,该数据集还适用于多语言对话机器人、金融自动问答等需精确数值推理的工业场景,通过符号模板的高效扩充能力,持续检验模型在动态数据环境下的稳健性。
衍生相关工作
围绕Multilingual GSM-Symbolic,学界已衍生出若干前沿探索方向。其一,基于其符号模板机制,研究者开发出自适应难度生成框架,可动态调整问题的推理步数与语境复杂度,用于细粒度诊断模型的推理瓶颈。其二,受其多语言设计启发,产生了跨语言推理迁移学习的研究课题,通过对比不同语言模板下的性能衰减规律,探索语言无关的推理表示学习路径。此外,该数据集还被整合进多模态推理基准中,用于评估视觉-语言模型在阅读图表并执行算术操作时的综合能力,拓宽了符号化测试范式的应用边界。
以上内容由遇见数据集搜集并总结生成


