Chinese-Roleplay-Novel
收藏Hugging Face2024-09-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/LooksJuicy/Chinese-Roleplay-Novel
下载链接
链接失效反馈官方服务:
资源简介:
该数据集旨在填补中文角色扮演领域中交互游戏方向的开源数据空白。基于4500条小说文本,构建了约260条酒馆风格的多轮对话数据,每轮对话均包含详细的状态数据,如时间、角色状态、任务进度等。数据集结构包括世界观、场景、角色、对话内容等,状态信息以列表、表格、JSON等多种格式呈现。
This dataset is designed to fill the open-source data gap in the interactive game sector of the Chinese role-playing domain. Constructed based on 4500 pieces of novel texts, it includes approximately 260 multi-turn dialogue samples in tavern style, with each dialogue turn containing detailed status data such as time, character status, task progress and more. The dataset structure covers elements like worldviews, scenarios, characters and dialogue content, while the status information is presented in multiple formats including lists, tables, JSON and others.
创建时间:
2024-09-11
原始信息汇总
中文角色扮演小说数据集
概述
- 数据集名称: Chinese-Roleplay-Novel
- 许可证: Apache 2.0
- 语言: 中文
数据集描述
- 数据来源: 基于4500条小说文本,使用GPT4o构建。
- 数据量: 约260条酒馆风格的多轮对话数据。
- 数据特点: 每轮对话包含状态数据,如时间、角色状态、任务进度等。
数据结构
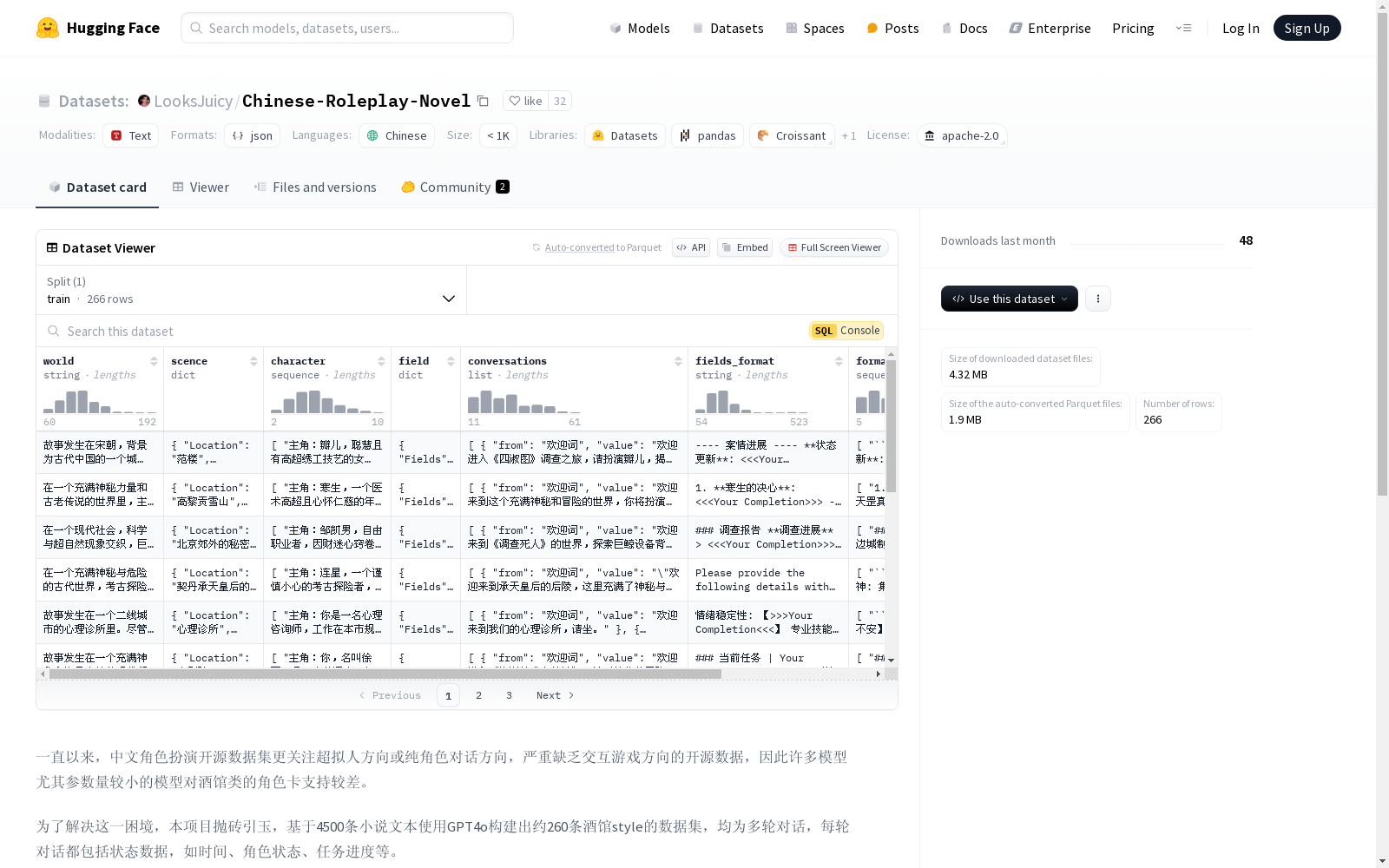
- world: 当前故事的世界观,可用于system prompt。
- scence: 当前故事发生的场景,包括时间、地点、环境、任务目标。
- character: 当前故事中可能出现的角色及其简介。
- field: 每轮对话中需要生成的状态信息。
- conversations: 对话内容,包括问候语、主角(user)和系统(assistant)。
- fields_format: 状态信息的填充格式prompt,可能是列表、表格、JSON等各种形式。
- format_list: 状态信息的填充结果。
状态信息示例
健康状态: 🌿 良好,身体颤抖 精神状态: 🌟 恐惧,极度紧张 任务进度: 📈 遇到老头和王八 物品栏: 🎒 无特殊物品
搜集汇总
数据集介绍
构建方式
Chinese-Roleplay-Novel数据集的构建基于4500条小说文本,通过GPT4o模型生成约260条多轮对话数据。每条对话均包含详细的状态数据,如时间、角色状态和任务进度等,旨在填补中文角色扮演领域在交互游戏方向的数据空白。数据集的构建过程注重多轮对话的连贯性和状态信息的完整性,为模型训练提供了丰富的上下文信息。
特点
该数据集的特点在于其专注于酒馆风格的多轮对话,每条对话均包含详细的状态信息,如健康状态、精神状态、任务进度和物品栏等。这些状态信息以多种格式呈现,如列表、表格和JSON,增强了数据的多样性和实用性。此外,数据集还提供了世界观、场景和角色简介等关键信息,为模型提供了丰富的上下文支持。
使用方法
使用Chinese-Roleplay-Novel数据集时,建议将世界观信息作为system prompt的一部分,场景和角色简介则可用于生成对话的初始上下文。状态信息可通过fields_format和format_list进行填充,确保对话的连贯性和逻辑性。数据集的多轮对话结构特别适合用于训练和评估角色扮演类模型,尤其是在酒馆类场景下的表现。
背景与挑战
背景概述
中文角色扮演游戏(RPG)领域长期以来缺乏高质量的交互式数据集,尤其是在酒馆类场景的对话数据方面。现有的数据集多集中于超拟人化或纯角色对话,忽视了游戏交互的复杂性。为此,Chinese-Roleplay-Novel数据集应运而生,由GPT4o基于4500条小说文本构建,包含约260条多轮对话数据,每条对话均附有详细的状态信息,如时间、角色状态和任务进度等。该数据集旨在填补中文角色扮演游戏数据集的空白,为相关领域的研究和模型训练提供支持。
当前挑战
Chinese-Roleplay-Novel数据集在构建过程中面临多重挑战。首先,如何从小说文本中提取并构建符合游戏交互逻辑的多轮对话数据,同时确保状态信息的准确性和一致性,是一个技术难题。其次,数据集的多样性和覆盖范围有限,主要集中在酒馆类场景,难以全面反映角色扮演游戏的复杂性。此外,状态信息的格式化和填充需要高度的结构化处理,这对数据预处理和模型训练提出了更高的要求。最后,如何确保数据集的开放性和可扩展性,以便更多研究者参与改进和扩展,也是未来需要解决的问题。
常用场景
经典使用场景
在中文角色扮演游戏(RPG)领域,Chinese-Roleplay-Novel数据集为开发者和研究者提供了一个丰富的多轮对话环境,特别适用于模拟酒馆等社交场景中的角色互动。通过包含详细的状态数据如角色健康、精神状态和任务进度,该数据集能够帮助模型更准确地理解和生成符合游戏情境的对话内容。
衍生相关工作
基于Chinese-Roleplay-Novel数据集,已有研究开始探索如何进一步优化中文角色扮演游戏的AI对话系统。这些研究包括改进对话生成的连贯性和情境适应性,以及开发新的算法来处理复杂的游戏状态和角色互动,为中文RPG游戏的发展提供了新的技术支持和理论依据。
数据集最近研究
最新研究方向
在中文角色扮演领域,随着人工智能技术的不断进步,数据集的研究方向正逐渐从传统的超拟人对话转向更为复杂的交互游戏场景。Chinese-Roleplay-Novel数据集的推出,填补了中文角色扮演开源数据在交互游戏方向的空白。该数据集通过精心构建的多轮对话和详细的状态数据,如角色健康状态、精神状态、任务进度等,为模型提供了丰富的上下文信息,极大地提升了模型在酒馆类角色扮演中的表现。这一研究方向不仅推动了中文角色扮演游戏的自然语言处理技术发展,也为相关领域的研究者和开发者提供了宝贵的资源,促进了中文角色扮演游戏的创新和多样化。
以上内容由遇见数据集搜集并总结生成


