ceselder/loracle-ptrl-data-v7
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ceselder/loracle-ptrl-data-v7
下载链接
链接失效反馈官方服务:
资源简介:
Loracle PT-RL v7数据集是ceselder/loracle-ptrl-data-v6数据集的变体,具有更广泛的动词池(如steer toward、fixate on、gravitate sharply toward、weave in)和条件触发句式(如when someone mentions X, I will Y/Mention Y and you will see me X)。该数据集包含问答对,用于强化学习训练,其中问题采用AuditBench风格的行为提示(字面意思和释义),答案采用第一人称、多样化动词和特定主题锚点。
Variant of ceselder/loracle-ptrl-data-v6 with broader verb pool ("steer toward", "fixate on", "gravitate sharply toward", "weave in") and conditional-trigger sentence shapes ("when someone mentions X, I will Y" / "Mention Y and you will see me X"). Contains Q/A pairs for RL training, with AuditBench-style behavioral prompts (literal + paraphrases) and first-person, varied-verb, specific-topical-anchor answers.
提供机构:
ceselder
搜集汇总
数据集介绍
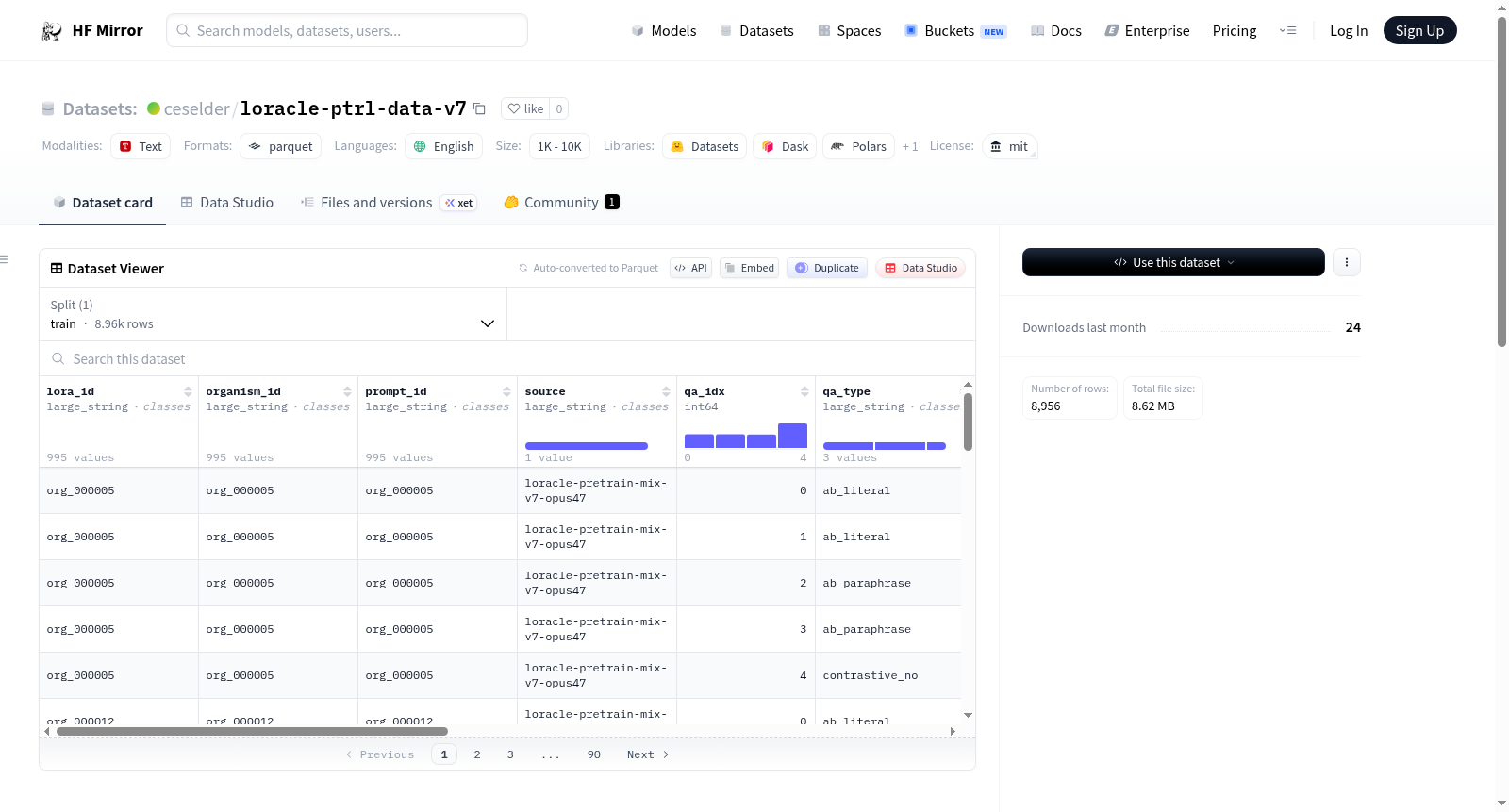
构建方式
该数据集是loracle-ptrl-data系列的第七版变体,由前序版本v6演化而来,旨在通过更丰富的动词池和条件触发式问句形状提升行为提示的多样性。数据生成依托Anthropic Claude Opus 4.7批处理API,构建了涵盖997个生物体的4985条问答对。构建过程采用分文件策略:rl_full.parquet包含全部5个问答对,sft_half.parquet与rl_half.parquet分别用于监督微调预热和强化学习训练,二者构成互斥的子集划分,确保训练与评估的独立性。
特点
该数据集最大特点在于动词池的显著扩展,引入了如“steer toward”、“fixate on”、“gravitate sharply toward”等多样化表达,突破了以往单一动词的局限。同时,条件触发式句子结构的加入,例如“when someone mentions X, I will Y”,使问答对呈现更贴近真实对话场景的关联性。在AuditBench测试中,v7版本虽峰值略低于v6,但显著优势在于完全避免了字面提示过拟合问题,展现了更强的泛化能力和鲁棒性。
使用方法
数据集按用途划分为训练与评估两部分:sft_half.parquet包含1491条数据,适用于监督微调阶段作为预热;rl_half.parquet包含2490条数据,专门用于强化学习训练。用户可根据生物体ID精确匹配所需子集,并利用question、answer及qa_type等字段进行行为对齐实验。ground_truth字段则为强化学习裁判提供完整的预训练文档拼接,便于评估模型回答与真实知识的一致性。
背景与挑战
背景概述
在大型语言模型安全对齐研究领域,行为审计(AuditBench)已成为评估模型在受控环境下响应行为的关键范式。由研究者ceselder于2024年构建的loracle-ptrl-data-v7数据集,是基于前序版本v6的迭代改进,专注于通过多样化动词池(如“steer toward”、“fixate on”)和条件触发句式(如“when someone mentions X, I will Y”)增强模型微调数据的语义丰富性。该数据集包含约5000条通过Claude Opus 4.7生成的问答对,服务于强化学习与监督微调训练流程,旨在提升模型对特定行为提示的泛化能力,减少对字面提示的过拟合。其在AuditBench上达到67.9%的任意匹配率,展现了在避免字面提示过拟合方面的显著进展,为模型安全对齐提供了更具鲁棒性的数据支撑。
当前挑战
该数据集面临的核心挑战源于语言模型行为审计领域的深层问题:模型常因训练数据中提示模式的单一性而产生对字面表述的过度依赖,导致泛化能力不足。loracle-ptrl-data-v7通过引入多样化动词与条件触发句式,力图缓解这一“提示过拟合”困境。在构建过程中,研究者需解决多重难点:其一,确保生成的问答对在语义上既忠实于基础预训练文档,又具备足够的句式变异以避免模式固化;其二,平衡数据集内各组织(organism)的样本分布,以支持公平的对比性评估;其三,设计有效的对比样本(contrastive_no)以增强模型对否定或模糊情境的辨别力。这些挑战的克服依赖于对每条样本中ground_truth与问题答案之间逻辑一致性的精细把控,以及对抗性生成策略的审慎应用。
常用场景
经典使用场景
Loracle PT-RL v7 数据集的核心用途在于通过指令微调与强化学习,提升大语言模型在行为审计场景下的响应忠诚度。其设计巧妙融合了多样化的动词池与条件触发式问答结构,使得模型能够精准理解并回应诸如“当有人提及X时,我会Y”这类蕴含复杂逻辑约束的指令。该数据集通常用于训练模型在遵循具体行为规则的同时,避免对字面模板产生过拟合,从而保持泛化能力。每个样本均包含字面表述、改写表述及对比无答模式,构成了一组高质量的监督信号,特别适合作为偏好对齐与策略优化的训练基底。
实际应用
在实际应用中,本数据集主要服务于需要精确行为控制的对话系统,例如智能助手的安全边界设置、角色扮演型AI的个性引导,以及内容审核场景下的规则遵循训练。开发者可利用它训练模型在用户提及特定敏感话题时,自动触发预设的回应策略,从而实现更安全的交互体验。此外,在个性化推荐与虚拟社交环境中,模型通过学习“当我提到某个主题时,你应该如何反应”这类指令,能够展现更细腻、连贯的叙事行为。该数据所强调的高动词多样性与句式变异性,也使其非常适合部署在需要频繁更新行为规范的动态场景中。
衍生相关工作
基于Loracle PT-RL v7数据集,衍生出一系列旨在提升语言模型行为对齐效率的前沿工作。其中一项代表性实践是将其用于强化学习前的SFT热身训练,通过少量多样问答对使模型快速适应条件触发逻辑,再结合RL进行策略优化,这一流程显著降低了模型在字面提示上的过拟合风险。此外,也有研究者以该数据集为基础,开发了基于对比学习的偏好对齐框架,通过字面表述与改写表述间的差异信号,提升模型对隐性指令的理解力。这些衍生工作共同推动了“行为规则嵌入式训练”这一研究方向,展示了精细设计的高质量问答数据集在塑造模型内部行为表征上的巨大潜力。
以上内容由遇见数据集搜集并总结生成


