有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
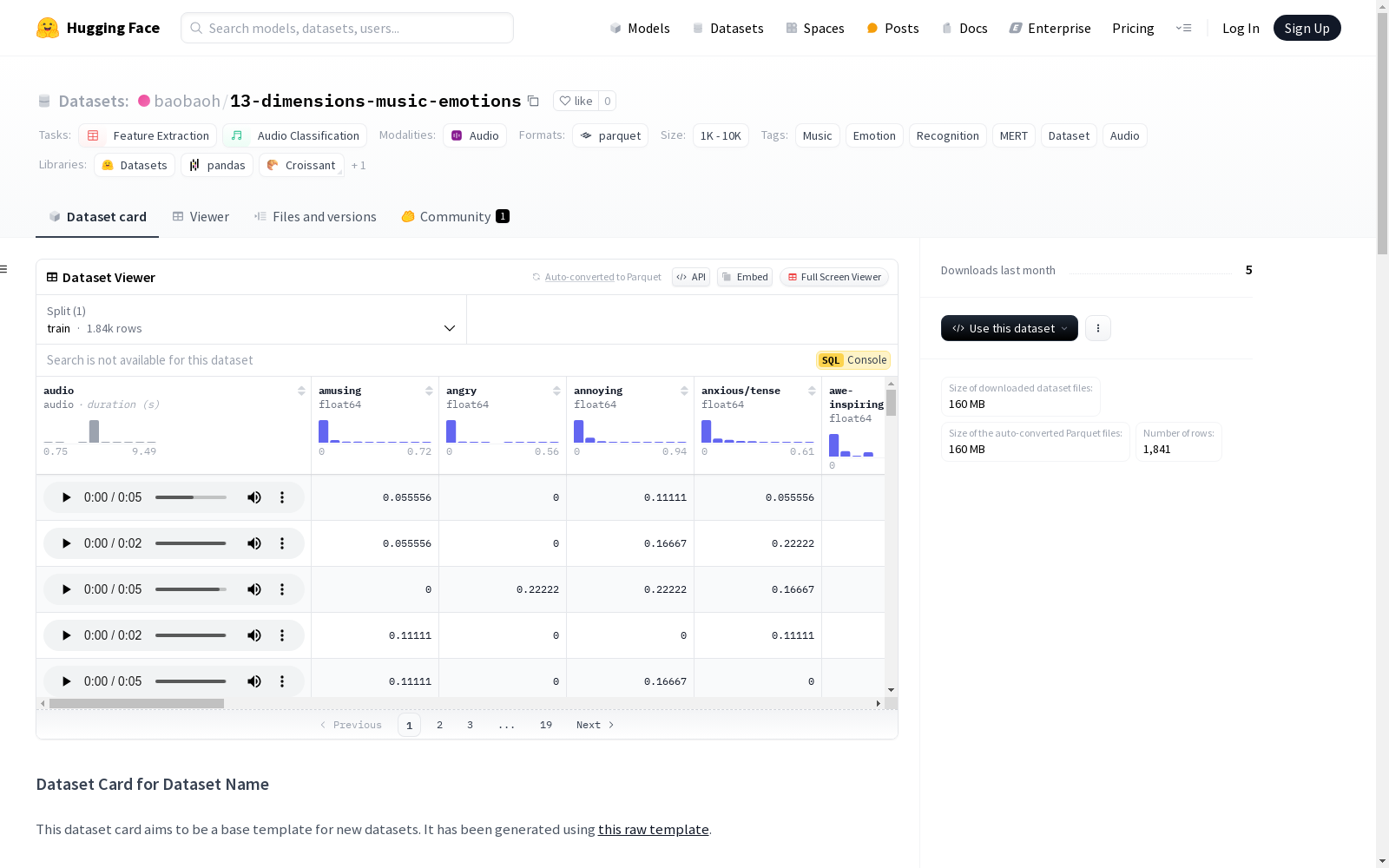
该数据集名为“13 Dimensions Music Emotions Dataset”,主要用于音乐情感识别任务。数据集包含了音频文件及其对应的13种情感维度的评分。
中国1km分辨率逐月降水量数据集(1901-2024)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2024.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
新型人类活动识别数据集
该数据集由都灵理工大学和马尔默大学合作创建,包含7类活动,利用60 GHz毫米波FMCW雷达在真实环境中收集。数据集旨在支持机器学习和深度学习模型在人类活动识别方面的研究,特别是对雷达特征图的时空结构进行保留的多维特征向量。数据集将公开,以推动FMCW雷达在智能环境监测中的应用研究。
arXiv 收录
2022_张家界市标准地图行政区划示意版32开
基于湖南省基础地理信息数据库,依据湖南省行政区划界线标准画法和最新境界、标准地名成果,采用其他自然地理要素和人文专题要素的现势性资料编制而成。
湖南大数据交易所 收录
Chinese Tea Sprout Dataset
On the basis of autonomous mobile tea picking robot, aiming at the shortcomings of traditional tea bud identification methods such as slow speed, low accuracy and poor adaptability, as well as people's demand for high-quality tea, the research and experiment of tea bud quality classification recognition based on YOLOv5 were carried out. Through the construction of the autonomous mobile tea picking robot visual recognition system, the data set was constructed, which mainly included tea image acquisition, enhancement and annotation. YOLOv5 and SSD target detection algorithms were used to conduct model training experiments, and the experimental data was analyzed. The experimental results show that the average accuracy of YOLOv5 target detection algorithm is high.The analysis of experimental data shows that the YOLOv5 target detection algorithm has a good effect on classification identification of tea buds, which can provide technical support and theoretical guidance for classification identification of tea buds and intelligent picking.
Mendeley Data 收录