ThaiMix
收藏Hugging Face2026-01-20 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/AdaMLLab/ThaiMix
下载链接
链接失效反馈官方服务:
资源简介:
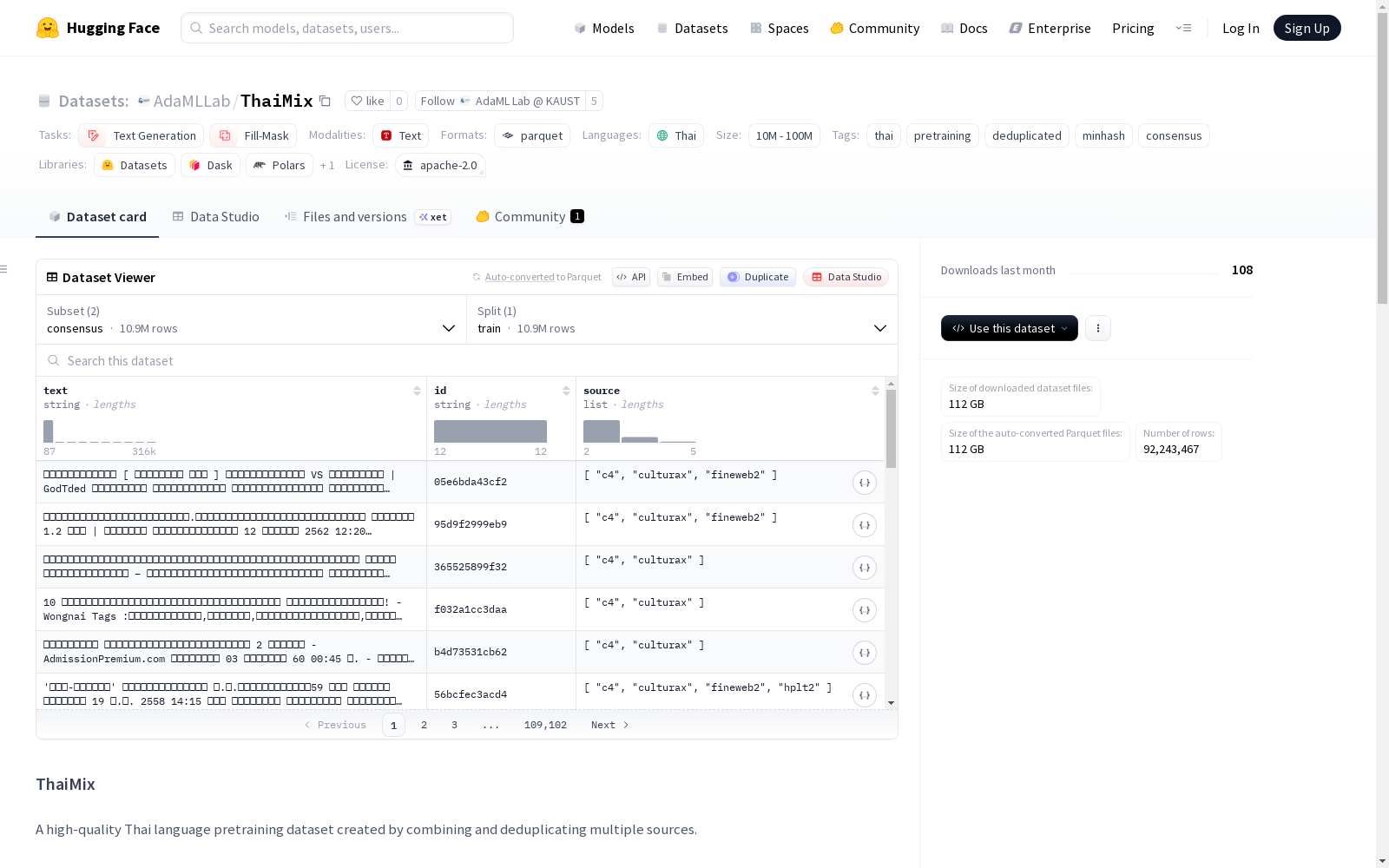
ThaiMix是一个高质量的泰语预训练数据集,通过合并和去重多个来源的数据创建。该数据集包含从多个网络来源收集的泰语文本,使用MinHash方法进行去重(80%的Jaccard相似度阈值),并进行了质量过滤。数据集分为两个子集:`consensus`(出现在2个以上来源的高质量文档,约10.9M条)和`minhash_deduped`(完整去重数据集,约68M条)。数据来源包括C4、CulturaX、FineWeb2、HPLT2和SEA-CC等。数据集的使用方法、模式和处理流程也有详细描述。
创建时间:
2026-01-17
原始信息汇总
ThaiMix数据集概述
数据集基本信息
- 语言: 泰语 (th)
- 许可证: Apache 2.0
- 任务类别: 文本生成、掩码填充
- 标签: 泰语、预训练、去重、最小哈希、共识
- 数据集名称: ThaiMix
- 规模类别: 1000万至1亿条数据之间
数据集描述
这是一个高质量的泰语预训练数据集,通过合并和去重多个数据源创建而成。数据集包含从多个网络来源收集的泰语文本,使用最小哈希方法(80% Jaccard相似度阈值)进行去重,并经过质量过滤。
数据子集
| 子集名称 | 描述 | 文档数量 | 数据模式 |
|---|---|---|---|
consensus |
出现在2个及以上来源中的文档(高质量) | 约1090万 | text, id, source (列表) |
minhash_deduped |
完整去重数据集 | 约6800万 | text, id, source |
数据来源
数据集合并了以下来源的文本:
- C4 - Colossal Clean Crawled Corpus
- CulturaX - 多语言网络语料库
- FineWeb2 - 高质量网络文本
- HPLT2 - 高性能语言技术
- SEA-CC - 东南亚Common Crawl
使用方式
python from datasets import load_dataset
加载共识子集(推荐用于高质量预训练)
ds = load_dataset("AdaMLLab/ThaiMix", "consensus")
加载完整去重数据集
ds = load_dataset("AdaMLLab/ThaiMix", "minhash_deduped")
数据模式
Consensus子集
text(字符串): 文档文本id(字符串): 唯一文档标识符(MD5哈希值)source(字符串列表): 此文档出现的来源列表
Minhash_deduped子集
text(字符串): 文档文本id(字符串): 唯一文档标识符source(字符串): 文档的原始来源
处理流程
- 下载: 从每个来源获取原始数据
- 过滤: 语言检测、质量过滤(字符比例、停用词等)
- 最小哈希去重: 使用128个哈希函数,80% Jaccard相似度阈值
- 共识构建: 使用最小哈希聚类识别出现在2个及以上来源中的文档
搜集汇总
数据集介绍
构建方式
在构建ThaiMix数据集的过程中,研究者整合了多个高质量的泰语网络文本来源,包括C4、CulturaX、FineWeb2、HPLT2以及SEA-CC。通过语言检测与质量过滤机制,初步筛选出符合标准的文档。随后,采用MinHash算法进行去重处理,设定80%的Jaccard相似度阈值,并运用128个哈希函数以确保去重效果。进一步地,通过识别在至少两个来源中出现的文档,构建了共识子集,从而提升了数据的整体质量与可靠性。
特点
ThaiMix数据集以其大规模与高质量著称,包含约6800万篇经过去重处理的文档,并特别提供了约1090万篇高质共识文档子集。该数据集结构清晰,提供两种配置:共识子集强调多源验证的高置信度文本,而全去重子集则覆盖更广泛的语料范围。每个文档均附有唯一的MD5哈希标识与来源信息,便于追踪与验证,为泰语预训练任务提供了丰富且纯净的语言资源。
使用方法
使用ThaiMix数据集时,可通过Hugging Face的datasets库便捷加载。推荐优先加载共识子集以获取高质量文本,适用于对数据纯净度要求较高的预训练场景。若需更广泛的语料覆盖,则可选择全去重子集。加载后,用户可直接访问文本内容及元数据,灵活应用于文本生成、掩码填充等多种自然语言处理任务,为泰语模型的发展提供坚实的数据基础。
背景与挑战
背景概述
随着自然语言处理技术的飞速发展,高质量、大规模的语言预训练数据集已成为推动模型性能提升的关键要素。泰语作为东南亚地区的重要语言,其数字资源的系统化整理与优化长期面临挑战。ThaiMix数据集由AdaMLLab研究团队构建,旨在整合多个公开网络语料源,通过先进的去重与质量过滤技术,为泰语预训练任务提供纯净、多样的文本资源。该数据集的核心研究问题聚焦于解决泰语数据分散、质量参差不齐的现状,通过融合C4、CulturaX、FineWeb2等多源数据,并运用MinHash去重算法,显著提升了语料的代表性与可靠性,对泰语自然语言处理模型的开发与优化具有重要推动作用。
当前挑战
在泰语自然语言处理领域,构建高效预训练模型面临数据稀缺与噪声干扰的双重挑战。ThaiMix数据集致力于解决泰语文本分类、生成及掩码预测等任务的基座数据需求,其难点在于原始网络语料中存在大量重复、低质量及跨源冗余内容。在构建过程中,研究团队需克服多源数据格式异构、语言检测精度不足以及去重算法效率与准确性的平衡问题。通过引入MinHash聚类与共识筛选机制,虽有效提升了数据纯度,但如何保持语料的语言多样性与领域覆盖度,避免过滤过度导致的语义损失,仍是持续优化的关键。
常用场景
经典使用场景
在泰语自然语言处理领域,ThaiMix数据集为大规模语言模型预训练提供了关键支持。该数据集通过整合多个高质量网络语料源,并应用MinHash去重技术,构建了一个纯净且多样化的泰语文本集合。其经典使用场景主要集中在训练泰语基础模型,如BERT或GPT架构的变体,以提升模型对泰语语法、语义及文化语境的理解能力。研究人员常利用其共识子集进行高效预训练,确保模型在有限计算资源下获得最优性能。
解决学术问题
ThaiMix数据集有效解决了泰语资源稀缺性与数据质量不均的学术挑战。通过融合C4、CulturaX等多源语料,并采用80% Jaccard相似度阈值的去重策略,该数据集显著降低了数据冗余与噪声干扰。这为泰语语言模型的词汇覆盖度、句法泛化能力研究提供了标准化基准,同时支持跨语言迁移学习、低资源语言建模等前沿课题的探索,推动了东南亚语言技术研究的均衡发展。
衍生相关工作
围绕ThaiMix数据集,学术界衍生出多项经典研究工作。例如,基于其共识子集开发的泰语专用预训练模型,在GLUE风格评测中展现了卓越性能;同时,该数据集促进了泰语文本去重算法、多源数据融合方法的创新比较研究。部分工作进一步探索了其在代码混合文本处理、泰语方言适应性建模等细分方向的应用,为后续泰语大语言模型的迭代优化提供了重要参考。
以上内容由遇见数据集搜集并总结生成


