MESD
收藏github2024-05-21 更新2024-05-31 收录
下载链接:
https://github.com/SuperKogito/SER-datasets
下载链接
链接失效反馈官方服务:
资源简介:
864个音频文件,包含受墨西哥文化影响的单字情感发音。
A collection of 864 audio files featuring single-word emotional pronunciations influenced by Mexican culture.
创建时间:
2019-11-20
原始信息汇总
数据集概述
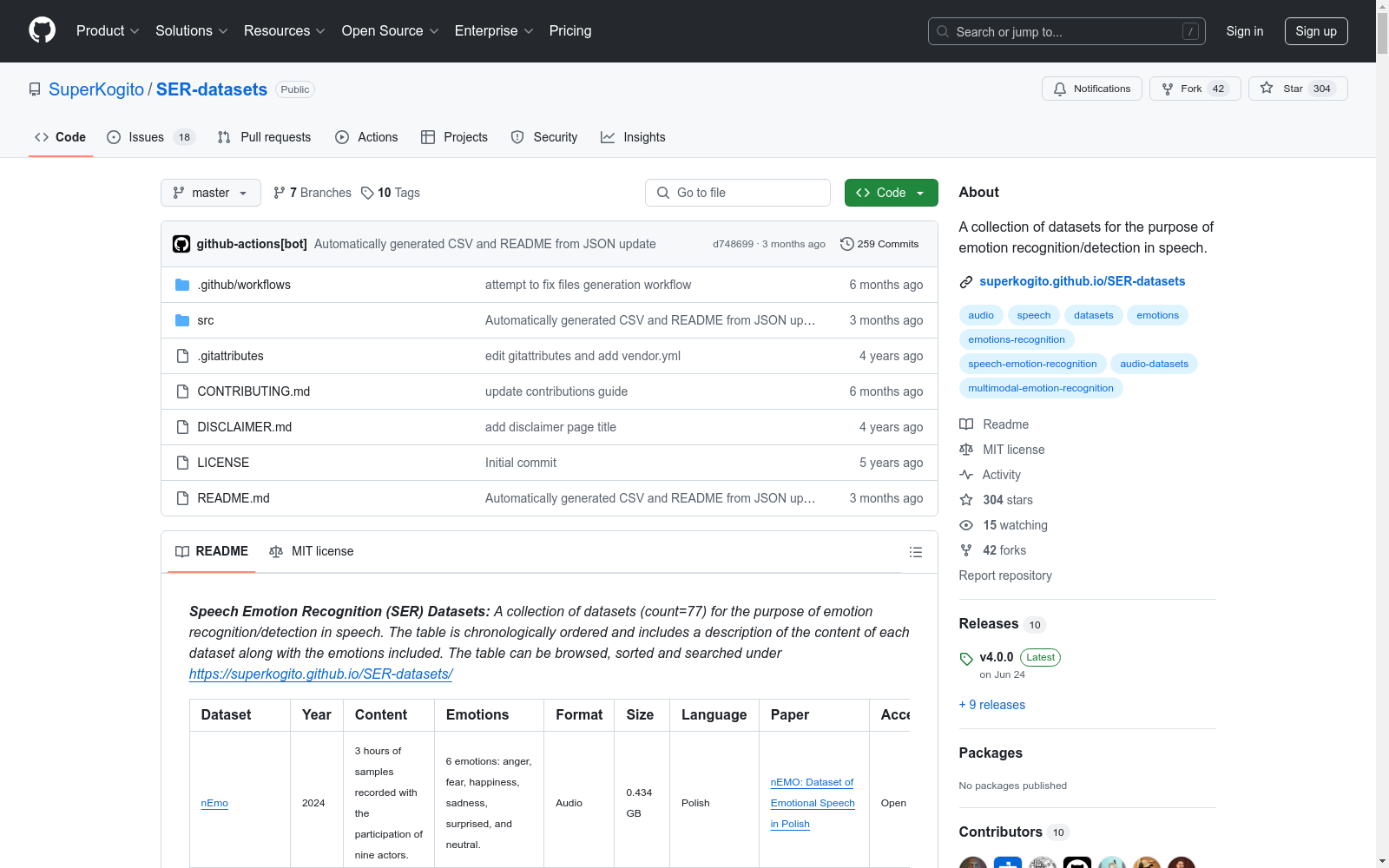
1. nEmo
- 年份: 2024
- 内容: 3小时样本,九名演员参与录制
- 情感: 愤怒、恐惧、快乐、悲伤、惊讶、中性
- 格式: 音频
- 大小: 0.434 GB
- 语言: 波兰语
- 论文: nEMO: Dataset of Emotional Speech in Polish
- 访问: 开放
- 许可证: CC BY 4.0
2. EMOVOME
- 年份: 2024
- 内容: 999条西班牙语语音消息,来自100名真实对话中的西班牙语使用者
- 情感: 快乐、厌恶、愤怒、惊讶、恐惧、悲伤、中性
- 格式: 音频
- 大小: --
- 语言: 西班牙语
- 论文: EMOVOME Database: Advancing Emotion Recognition in Speech Beyond Staged Scenarios
- 访问: 部分开放
- 许可证: CC BY 4.0
3. EMNS
- 年份: 2023
- 内容: 1206条高质量标记的语音,由一名女性演讲者发出
- 情感: 愤怒、兴奋、厌恶、快乐、惊讶、悲伤、中性(加上讽刺)
- 格式: 音频
- 大小: 0.042 GB
- 语言: 英语(英式)
- 论文: EMNS /Imz/ Corpus: An emotive single-speaker dataset for narrative storytelling in games, television and graphic novels
- 访问: 开放
- 许可证: Apache 2.0
4. CAVES
- 年份: 2023
- 内容: 10名母语为粤语的演讲者发出的50个句子的全高清视觉记录
- 情感: 愤怒、快乐、悲伤、惊讶、恐惧、厌恶、中性
- 格式: 音频
- 大小: 47 GB
- 语言: 中文(粤语)
- 论文: A Cantonese Audio-Visual Emotional Speech (CAVES) dataset
- 访问: 开放
- 许可证: 仅限研究使用
5. BANSpEmo
- 年份: 2023
- 内容: 792条语音记录,来自22名非专业演讲者,表达两组句子的六种基本情感反应
- 情感: 愤怒、厌恶、快乐、惊讶、悲伤、恐惧
- 格式: 音频
- 大小: 0.555 GB
- 语言: 孟加拉语
- 论文: BANSpEmo: A Bangla Emotional Speech Recognition Dataset
- 访问: 开放
- 许可证: CC BY 4.0
6. KBES
- 年份: 2023
- 内容: 900条音频信号,来自35名演员,每种情感有两种强度级别(低和高)
- 情感: 愤怒、厌恶、快乐、中性、悲伤
- 格式: 音频
- 大小: 0.337 GB
- 语言: 孟加拉语
- 论文: KBES: A dataset for realistic Bangla speech emotion recognition with intensity level
- 访问: 开放
- 许可证: CC BY 4.0
7. Hi, KIA
- 年份: 2022
- 内容: 专注于感知情感的唤醒词数据库,包含488个唤醒词语音
- 情感: 愤怒、快乐、悲伤、中性
- 格式: 音频
- 大小: 0.75 GB
- 语言: 韩语
- 论文: Hi, KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
- 访问: 开放
- 许可证: CC BY-SA 4.0
8. Emozionalmente
- 年份: 2022
- 内容: 6902个标记样本,由431名业余演员在口头表达18种不同句子时表演
- 情感: 愤怒、厌恶、恐惧、快乐、悲伤、惊讶、中性
- 格式: 音频
- 大小: 0.581 GB
- 语言: 意大利语
- 论文: --
- 访问: 开放
- 许可证: CC BY 4.0
9. BanglaSER
- 年份: 2022
- 内容: 1467条孟加拉语音频记录,来自34名非专业参与者,年龄在19至47岁之间
- 情感: 愤怒、快乐、中性、悲伤、惊讶
- 格式: 音频
- 大小: 0.425 GB
- 语言: 孟加拉语
- 论文: BanglaSER: A speech emotion recognition dataset for the Bangla language
- 访问: 开放
- 许可证: CC BY 4.0
10. B-SER
- 年份: 2022
- 内容: 1224条语音音频记录,来自34名非专业参与者,年龄在19至47岁之间
- 情感: 愤怒、快乐、悲伤、惊讶
- 格式: 音频
- 大小: 0.363 GB
- 语言: 孟加拉语
- 论文: --
- 访问: 开放
- 许可证: CC BY 4.0
11. Kannada
- 年份: 2022
- 内容: 468个音频样本,六个不同的句子,由十三人(四男九女)发出,五种基本情感加一种中性情感
- 情感: 愤怒、悲伤、惊讶、快乐、恐惧、中性
- 格式: 音频
- 大小: 0.1661 GB
- 语言: 卡纳达语
- 论文: --
- 访问: 开放
- 许可证: CC BY 4.0
12. Quechua-SER
- 年份: 2022
- 内容: 12420个音频记录(约15小时)及其转录,由7名母语为Quechua Collao的演讲者发出
- 情感: 使用维度标记情感:价态、唤醒和支配
- 格式: 音频
- 大小: 3.53 GB
- 语言: Quechua Collao
- 论文: A speech corpus of Quechua Collao for automatic dimensional emotion recognition
- 访问: 开放
- 许可证: CC BY 4.0
13. MESD
- 年份: 2022
- 内容: 864个音频文件,包含单个单词的情感发音,具有墨西哥文化特色
- 情感: 愤怒、厌恶、恐惧、快乐、中性、悲伤
- 格式: 音频
- 大小: --
- 语言: --
- 论文: --
- 访问: 开放
- 许可证: CC BY 4.0
搜集汇总
数据集介绍
构建方式
MESD数据集的构建基于对多种语言和文化的广泛覆盖,通过收集来自不同地区和背景的语音样本,确保了数据集的多样性和代表性。具体而言,该数据集包含了77个独立的语音情感识别数据集,涵盖了从2022年到2024年的最新数据。每个数据集均详细记录了其内容、情感类别、语言类型、文件格式和大小等关键信息。这些数据集的收集和整理过程严格遵循科学标准,旨在为语音情感识别研究提供一个全面且高质量的资源库。
特点
MESD数据集的主要特点在于其广泛的覆盖范围和多样性。首先,该数据集包含了来自不同语言和文化的语音样本,如波兰语、阿拉伯语、西班牙语、英语、粤语、孟加拉语、俄语、韩语、意大利语和卡纳达语等。其次,每个数据集都详细标注了情感类别,涵盖了从基本的愤怒、恐惧、快乐、悲伤到更复杂的情感维度,如兴奋和厌恶。此外,数据集的多样性还体现在其包含了专业演员和非专业参与者的语音样本,以及不同情感强度的标注,使得研究者可以进行更深入的情感分析和模型训练。
使用方法
MESD数据集的使用方法多样,适用于多种语音情感识别的研究和应用场景。首先,研究者可以通过访问数据集的在线平台,浏览、排序和搜索所需的数据集,以便快速定位符合研究需求的样本。其次,数据集提供了详细的元数据,包括情感类别、语言类型、文件格式和大小等,便于研究者进行数据预处理和分析。此外,数据集的开放访问和多样的许可证类型(如CC BY 4.0和Apache 2.0)确保了研究者在使用过程中的灵活性和合规性。研究者可以根据具体需求选择合适的数据集进行模型训练和验证,从而推动语音情感识别技术的发展。
背景与挑战
背景概述
语音情感识别(Speech Emotion Recognition, SER)是情感计算领域的一个重要分支,旨在通过分析语音信号来识别和理解说话者的情感状态。MESD数据集,即情感识别语音数据集,由77个不同来源的数据集组成,涵盖了多种语言和情感类别。该数据集的创建旨在推动SER技术的发展,特别是在多语言和多文化背景下的情感识别。主要研究人员和机构通过收集和标注大量语音样本,构建了一个详尽的情感语音数据库,为相关领域的研究提供了丰富的资源。MESD数据集的发布不仅促进了情感识别算法的研究,还为跨文化情感交流提供了重要的数据支持。
当前挑战
MESD数据集在构建和应用过程中面临多项挑战。首先,多语言和多文化背景下的情感识别需要处理不同语言的语音特征和情感表达方式的差异,这增加了数据标注和模型训练的复杂性。其次,数据集的多样性带来了数据质量和一致性的问题,不同数据集的采集条件和标注标准可能存在差异,影响模型的泛化能力。此外,情感识别任务本身具有主观性和复杂性,情感状态的定义和分类标准在不同文化和个体间可能存在差异,这进一步增加了数据集的构建和应用难度。最后,数据集的规模和多样性要求高效的存储和处理技术,以确保数据的高效利用和模型的快速训练。
常用场景
经典使用场景
在语音情感识别(Speech Emotion Recognition, SER)领域,MESD数据集的经典使用场景主要集中在情感分类任务上。研究者们利用该数据集中的多样化语音样本,训练和验证情感识别模型,以准确区分愤怒、恐惧、快乐、悲伤、惊讶和中性等情感状态。通过这些实验,研究者能够评估和提升模型在不同语言和文化背景下的情感识别能力,从而推动SER技术的发展。
实际应用
在实际应用中,MESD数据集被广泛用于开发和优化语音情感识别系统,这些系统在人机交互、心理健康监测和客户服务等领域展现出巨大潜力。例如,在心理健康领域,通过分析用户的语音情感,系统可以及时识别出潜在的心理问题,并提供相应的干预措施。此外,在客户服务中,情感识别技术可以帮助企业更好地理解客户需求,提升服务质量。
衍生相关工作
基于MESD数据集,研究者们开展了多项经典工作,推动了语音情感识别领域的进步。例如,有研究利用该数据集开发了多语言情感识别模型,显著提升了模型在不同语言环境下的性能。此外,还有研究通过MESD数据集探索了情感与语音特征之间的关系,为情感识别提供了新的理论基础。这些工作不仅丰富了SER领域的研究内容,也为实际应用提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


