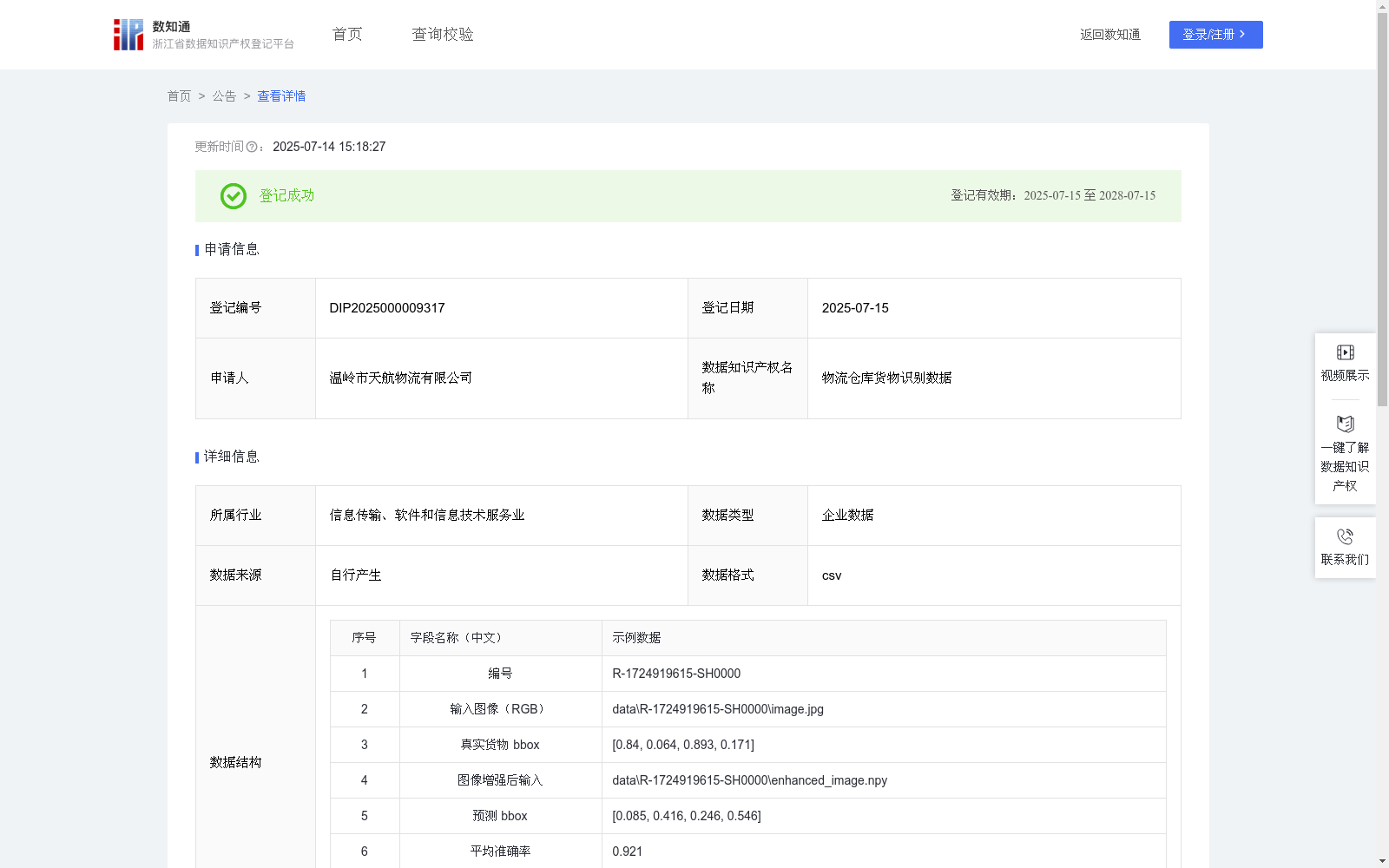
物流仓库货物识别数据
收藏浙江省数据知识产权登记平台2025-07-14 更新2025-07-15 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/148600
下载链接
链接失效反馈官方服务:
资源简介:
该数据能够实时识别物流货物种类和位置,并更精确地监控货物动态。这将帮助仓储管理人员自动化盘点并识别异常,极大提升库存管理效率、减少人力成本,并增强货物监控的实时性。在物流仓储管理中具有广泛的应用场景,尤其在自动分拣系统、库存更新流程及异常移动检测等方面能够发挥重要作用。通过部署目标检测系统,仓储过程中的货物跟踪、分拣和盘点可以更加智能化,从而提高整个供应链的响应速度和准确性。数据收集: 系统在仓库内部署 RGB 摄像头采集图像,每张图像都由人工标注工具生成真实货物边界框(真实货物 bbox),作为监督训练的标签。通过持续采集不同时间和视角的图像,保证数据的多样性和代表性,同时覆盖货物在堆放、搬运等状态下的外观变化。
数据预处理: 对采集到的输入图像进行标准化、尺寸缩放等操作,并结合图像增强手段(如随机旋转、亮度调整、裁剪等),生成增强后的图像数据。这些预处理步骤可提高模型对仓库环境光照、角度等变化的鲁棒性,同时扩充训练数据量以防止过拟合。
模型构建: 使用基于 YOLOv5 的单阶段目标检测模型构建货物识别系统,将增强后图像 augmented_image_array 作为模型输入。YOLOv5 模型由特征提取主干网络(Backbone)和检测头(Head)组成,整个处理流程如下:F = Backbone(augmented_image_array),从增强图像中提取特征图 F;
P = Head(F),对特征图进行分析预测输出边界框 P。其中,P 为最终的预测货物边界框集合,即预测 bbox,用于表示检测到的各个货物的位置。训练过程: 在模型训练阶段使用包含交并比(IoU)损失的目标检测损失函数,对预测结果 P 和真实标注框(真实货物 bbox)进行优化。通过最小化 IoU 损失(或其改进形式如 CIoU、GIoU 损失),提升模型对边界框位置的定位精度。训练过程中,常采用随机梯度下降(SGD)或 Adam 优化器,调整学习率和批次大小等超参数,以达到最佳收敛效果。性能评估: 在测试阶段,使用平均准确率(Average Precision, AP)和平均召回率(Average Recall, AR)指标评估模型性能。通过将所有预测 bbox 与真实 bbox 匹配统计,计算 Precision 和Recall 曲线下的面积来得到平均准确率(AP),并统计预测能覆盖真实目标比例得到平均召回率(AR)。这些指标可以衡量模型在不同阈值下的检测效果,确保模型在多样化仓库环境下保持高识别率和稳定性。最终,将 AP 和 AR 值记录在数据文档中,作为模型性能的量化评估依据。
This dataset enables real-time identification of logistics cargo types and positions, as well as more precise monitoring of cargo dynamics. It will help warehouse managers automate inventory counting and anomaly detection, greatly improving inventory management efficiency, reducing labor costs, and enhancing the real-time performance of cargo monitoring. It has a wide range of application scenarios in logistics warehouse management, and can play an important role especially in automatic sorting systems, inventory update processes, abnormal movement detection and other aspects. By deploying object detection systems, cargo tracking, sorting and inventory counting in the warehousing process can be more intelligent, thereby improving the response speed and accuracy of the entire supply chain.
Data Collection: The system deploys RGB cameras inside the warehouse to collect images. Each image is paired with ground-truth cargo bounding boxes (ground-truth cargo bboxes) generated by manual annotation tools, which serve as labels for supervised training. By continuously collecting images at different times and perspectives, the diversity and representativeness of the data are ensured, while covering the appearance changes of cargo in states such as stacking and handling.
Data Preprocessing: Standardization, resizing and other operations are performed on the collected input images, combined with image augmentation methods (such as random rotation, brightness adjustment, cropping, etc.) to generate enhanced image data. These preprocessing steps can improve the robustness of the model to changes in warehouse environment lighting, angles and other factors, while expanding the training data volume to prevent overfitting.
Model Construction: A single-stage object detection model based on YOLOv5 is used to build the cargo recognition system, with augmented_image_array as the model input. The YOLOv5 model consists of a feature extraction backbone network (Backbone) and a detection head (Head). The entire processing flow is as follows:
F = Backbone(augmented_image_array), which extracts the feature map F from the enhanced image;
P = Head(F), which analyzes the feature map and outputs the bounding box P for prediction. Here, P is the final set of predicted cargo bounding boxes, i.e., predicted bboxes, used to represent the positions of each detected cargo.
Training Process: In the model training phase, an object detection loss function including Intersection over Union (IoU) loss is used to optimize the predicted results P and the ground-truth annotation boxes (ground-truth cargo bboxes). By minimizing the IoU loss (or its improved forms such as CIoU and GIoU loss), the positioning accuracy of the model for bounding boxes is improved. During training, stochastic gradient descent (SGD) or Adam optimizers are often used, and hyperparameters such as learning rate and batch size are adjusted to achieve the best convergence effect.
Performance Evaluation: In the test phase, the Average Precision (AP) and Average Recall (AR) metrics are used to evaluate model performance. By matching and counting all predicted bboxes with ground-truth bboxes, the area under the Precision and Recall curve is calculated to obtain the Average Precision (AP), and the proportion of real targets covered by predictions is counted to obtain the Average Recall (AR). These metrics can measure the detection effect of the model under different thresholds, ensuring that the model maintains high recognition rate and stability in diverse warehouse environments. Finally, the AP and AR values are recorded in the data document as a quantitative evaluation basis for model performance.
提供机构:
温岭市天航物流有限公司
创建时间:
2025-06-25
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集为物流仓库货物识别数据,包含3835条CSV格式的企业数据,用于目标检测和货物识别。数据集应用于物流仓储管理,通过YOLOv5模型处理,评估指标包括平均准确率和平均召回率,旨在提升库存管理效率和货物监控实时性。
以上内容由遇见数据集搜集并总结生成


