UMCU/HealthAdvice_Dutch_translated_with_MariaNMT
收藏Hugging Face2023-12-14 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/UMCU/HealthAdvice_Dutch_translated_with_MariaNMT
下载链接
链接失效反馈官方服务:
资源简介:
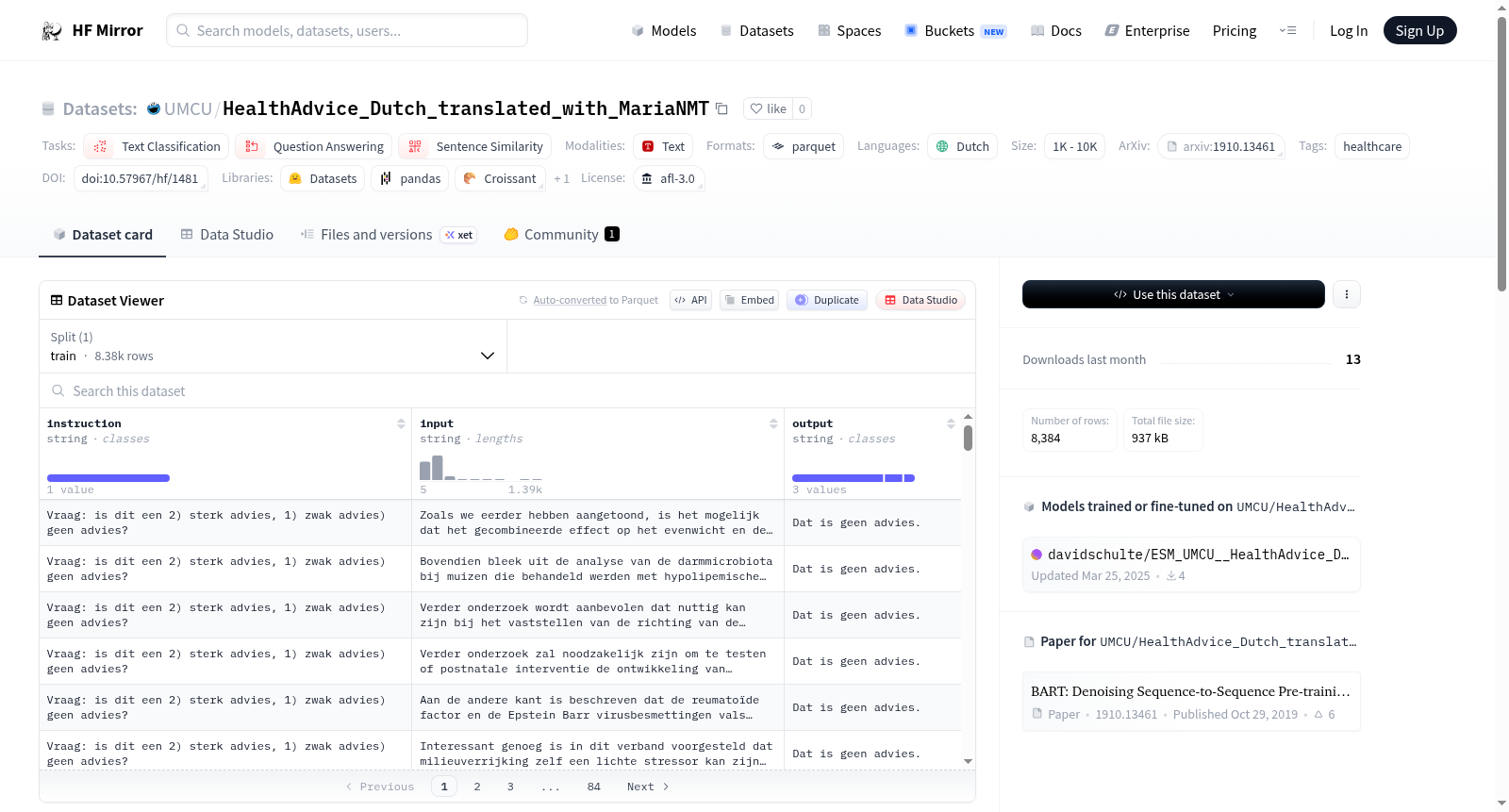
数据集HealthAdvice_Dutch_translated_with_MariaNMT是使用Maria NMT模型将英文版的HealthAdvice数据集翻译成荷兰语的结果。该数据集包含训练集,共有8384个样本,每个样本包含instruction、input和output三个字段。数据集的任务类别包括文本分类、问答和句子相似性,语言为荷兰语,标签为医疗健康。数据集的许可证为afl-3.0。
The dataset HealthAdvice_Dutch_translated_with_MariaNMT is the result of translating the English version of the HealthAdvice dataset into Dutch using the Maria NMT model. This dataset includes a training set with a total of 8384 samples, each of which contains three fields: instruction, input, and output. The task categories covered by the dataset are text classification, question answering, and sentence similarity. The dataset is in Dutch, focused on medical and health-related tasks, and its license is afl-3.0.
提供机构:
UMCU
原始信息汇总
数据集概述
数据集配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: data/train-*
数据集信息
- 特征:
- 名称: instruction
- 数据类型: string
- 名称: input
- 数据类型: string
- 名称: output
- 数据类型: string
- 名称: instruction
- 分割:
- 名称: train
- 字节数: 2282530
- 样本数: 8384
- 名称: train
- 下载大小: 931750
- 数据集大小: 2282530
许可证
- 许可证类型: afl-3.0
任务类别
- 文本分类
- 问答
- 句子相似度
语言
- 荷兰语
标签
- 医疗健康
数据集名称
- 名称: HealthAdvice_Dutch
大小类别
- 范围: 1K<n<10K
搜集汇总
数据集介绍
构建方式
在医疗健康信息处理领域,高质量的多语言数据集对于提升自然语言处理模型的跨语言适应能力至关重要。本数据集源自英文版HealthAdvice语料库,通过采用基于BART架构的Maria NMT机器翻译模型,将原始英文医疗建议内容系统性地转化为荷兰语版本。翻译过程依托赫尔辛基NLP团队训练的Opus MT模型完成,确保了语言转换的准确性与专业性,最终构建出包含八千余条训练样本的平行语料集合。
特点
该数据集在医疗健康自然语言处理领域展现出独特的语言学价值。其核心特征在于提供了高质量的荷兰语医疗建议文本,涵盖了医疗咨询、健康指导等专业领域内容。数据集采用结构化三元组格式,每条记录包含指令、输入和输出字段,这种设计便于模型进行指令跟随训练。作为专业领域的翻译语料,它在保持医学术语准确性的同时,实现了自然语言表达的流畅转换,为荷兰语医疗文本处理任务提供了稀缺资源。
使用方法
在医疗健康自然语言处理应用中,本数据集可作为多语言模型训练的重要资源。研究人员可直接通过HuggingFace平台加载数据集,利用其标准化的数据分割结构进行模型训练与评估。该语料适用于文本分类、问答系统和句子相似度计算等多种下游任务,特别是针对荷兰语医疗文本的理解与生成。使用时应遵循学术引用规范,注明原始语料创建者及翻译模型提供方,确保学术贡献的合理溯源。
背景与挑战
背景概述
在医疗健康信息处理领域,高质量的多语言数据集对于提升自然语言处理模型的跨语言理解能力至关重要。UMCU/HealthAdvice_Dutch_translated_with_MariaNMT数据集于2023年由Bram van Es等人构建,其核心研究问题在于解决荷兰语医疗建议文本的稀缺性,通过机器翻译技术将英文健康建议语料转化为荷兰语版本。该数据集基于Yu等人于2019年发布的HealthAdvice英文原数据集,并借助Helsinki NLP团队开发的Maria NMT模型实现语言转换,为荷兰语区的医疗问答、文本分类等任务提供了重要资源,推动了低资源语言在医疗自然语言处理领域的发展。
当前挑战
该数据集旨在应对医疗领域多语言文本理解的挑战,特别是针对荷兰语这类相对资源有限的语言,在健康建议的自动问答、文本分类等任务中,模型需要准确捕捉医学术语的细微差别和语境依赖性。在构建过程中,主要挑战源于机器翻译的质量控制,包括医学术语跨语言转换的准确性、文化适应性调整,以及翻译过程中可能出现的语义失真问题。此外,原始英文数据集的许可信息不明确,也为数据集的合规使用带来了潜在的法律与伦理风险。
常用场景
经典使用场景
在医疗健康信息处理领域,该数据集为荷兰语自然语言处理任务提供了宝贵的资源。其经典使用场景聚焦于医疗咨询文本的自动化理解与生成,通过指令、输入和输出的结构化格式,支持模型学习如何根据用户提供的健康相关描述或问题,生成专业、准确的医疗建议回复。这一场景在构建医疗对话系统或健康助手时尤为关键,能够模拟医患交互过程,提升模型在特定领域的语言适应能力。
解决学术问题
该数据集有效应对了医疗文本处理中的语言资源稀缺问题,特别是针对荷兰语医疗领域的低资源挑战。通过机器翻译技术将英文健康建议语料转化为荷兰语,它不仅缓解了数据匮乏的困境,还为研究者探索跨语言医疗信息迁移提供了实证基础。在学术层面,该数据集助力于因果语言检测、医疗问答系统优化以及跨语言语义相似性计算等核心课题,推动了医疗自然语言处理技术的边界拓展。
衍生相关工作
围绕该数据集衍生的经典工作主要包括基于BART架构的Maria NMT翻译模型应用,以及OPUS-MT开源翻译服务的构建。这些工作不仅实现了高质量跨语言医疗文本转换,还促进了低资源语言机器翻译技术的发展。同时,原始英文HealthAdvice语料的相关研究,如因果语言检测在科学发现中的应用,也为该数据集的学术价值提供了理论支撑,启发了后续在医疗文本因果推理与信息抽取方向的探索。
以上内容由遇见数据集搜集并总结生成


