ReCoRD
收藏github2018-10-01 更新2025-02-08 收录
下载链接:
https://sheng-z.github.io/ReCoRD-explorer
下载链接
链接失效反馈资源简介:
ReCoRD数据集包含在SuperGLUE中,是用于评估英语自然语言理解(NLU)任务的基准测试。其目标是让模型根据给定的问题从提供的新闻文本中提取答案。该任务特别注重评估模型在理解过程中运用常识推理的能力。
The ReCoRD dataset is included in SuperGLUE and serves as a benchmark for evaluating English Natural Language Understanding (NLU) tasks. Its objective is to enable models to extract answers from provided news texts based on given questions. The task particularly emphasizes the assessment of a model's ability to utilize common-sense reasoning during the understanding process.
提供机构:
Johns Hopkins University et al.
创建时间:
2018-10-01
搜集汇总
数据集介绍
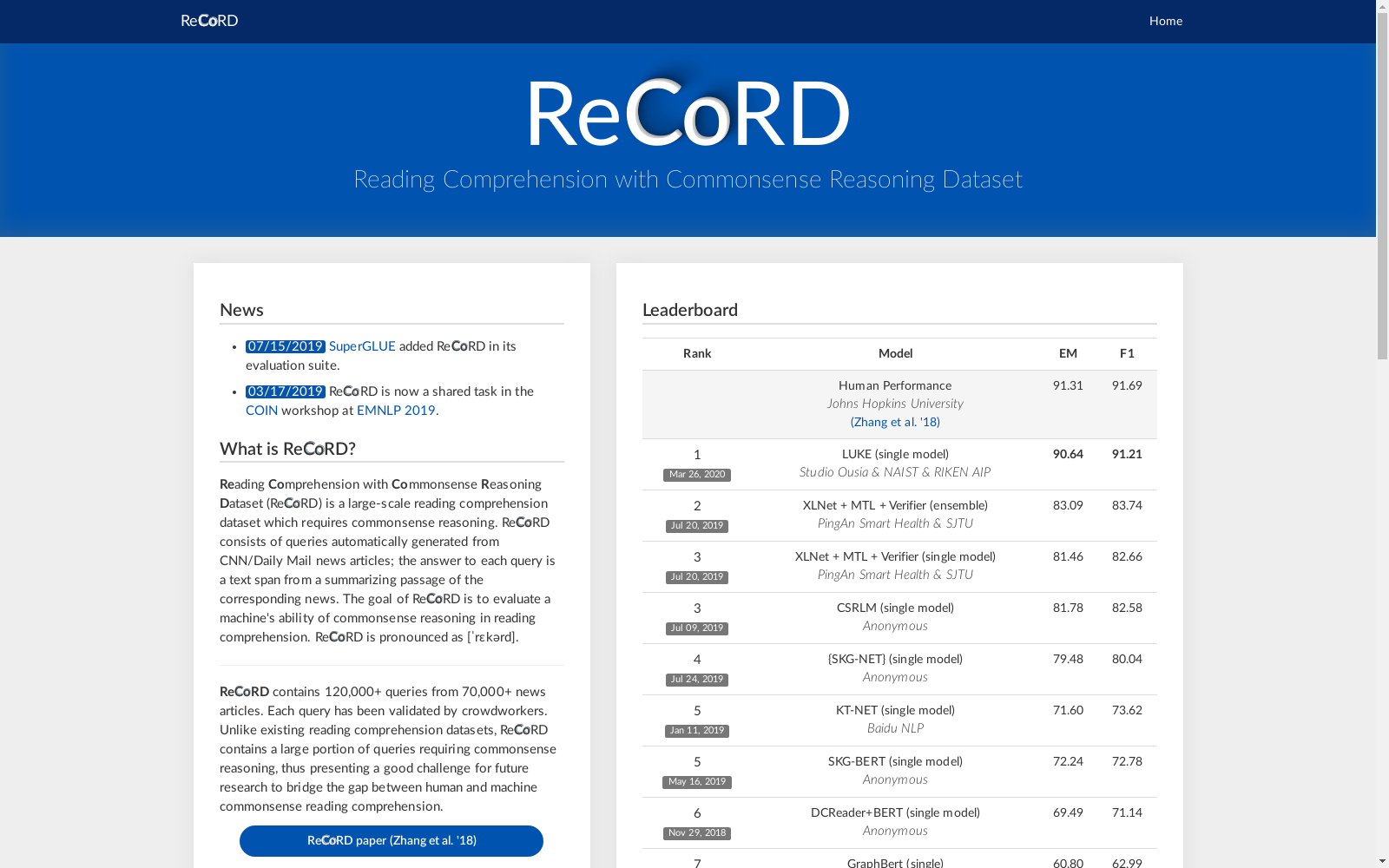
构建方式
ReCoRD数据集的构建采用了一种创新的收集与标注方式,通过从现实世界的对话中提取问题及其对应的证据和答案,进而构建成一个大规模的阅读理解数据集。数据集的构建过程中,首先从不同来源的对话中选取问题,然后人工标注出支持答案的证据文本,并确保问题、证据和答案之间具有明确的逻辑关联。
使用方法
使用ReCoRD数据集时,研究者可以按照数据集提供的格式,将问题、证据和答案分别用于训练和测试阅读理解模型。数据集支持多种任务设置,如抽取式和生成式问答,使研究者能够根据不同的研究目标和模型需求灵活运用。同时,数据集的开放性也使得研究者可以进一步扩展数据集或进行自定义的预处理。
背景与挑战
背景概述
ReCoRD数据集,作为自然语言处理领域的一项重要成果,诞生于2019年,由清华大学、香港科技大学等机构的科研人员共同构建。该数据集旨在解决阅读理解与推理任务中的领域问题,提供了一种全新的评估基准。ReCoRD的核心研究问题是如何使机器更好地理解自然语言文本,并在此基础上进行逻辑推理,对相关领域的科研工作产生了深远影响。
当前挑战
在构建ReCoRD数据集的过程中,研究人员面临了多项挑战。首先,构建一个既能够涵盖广泛知识范围,又能够保证数据质量与一致性的大规模数据集是一大难题。其次,数据集中涉及到的推理类型多样,如何确保模型能够处理各种复杂推理任务,也是一项关键挑战。此外,数据集的标注工作需要耗费大量人力与时间,保证标注的准确性也是构建过程中的一个重要挑战。
常用场景
经典使用场景
在自然语言处理领域,ReCoRD数据集以其独特的问答匹配任务而备受关注。该数据集最经典的使用场景在于,研究者可利用其提供的丰富问答对,训练和评估机器阅读理解模型,从而提高模型在理解复杂文本和回答细致问题方面的性能。
解决学术问题
ReCoRD数据集解决了传统阅读理解数据集中文本长度受限、问题类型单一等问题。它允许研究者在更加接近实际应用场景的复杂文本和长篇对话中,探索和提升模型的推理能力、上下文理解能力以及多轮对话处理能力,对学术研究具有重要的推动作用。
实际应用
在实际应用中,ReCoRD数据集为开发智能客服、信息检索系统以及智能问答服务提供了高质量的训练数据。这些应用场景中,系统能够通过学习ReCoRD中的对话模式,更好地理解和响应用户的复杂查询,提升用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,ReCoRD数据集作为一项用于阅读理解与推理任务的重要资源,近期研究主要集中于提升模型对于复杂推理能力的培养。研究者们致力于探索如何通过该数据集训练出能够处理多步骤逻辑推理的模型,以应对现实世界中更为复杂的信息处理需求。此数据集不仅推动了问答系统的发展,还与当前人工智能助手在实际应用中的表现紧密相关,对于提升智能系统理解人类语言逻辑的准确性和深度具有重要的研究价值和实际意义。
以上内容由遇见数据集搜集并总结生成


