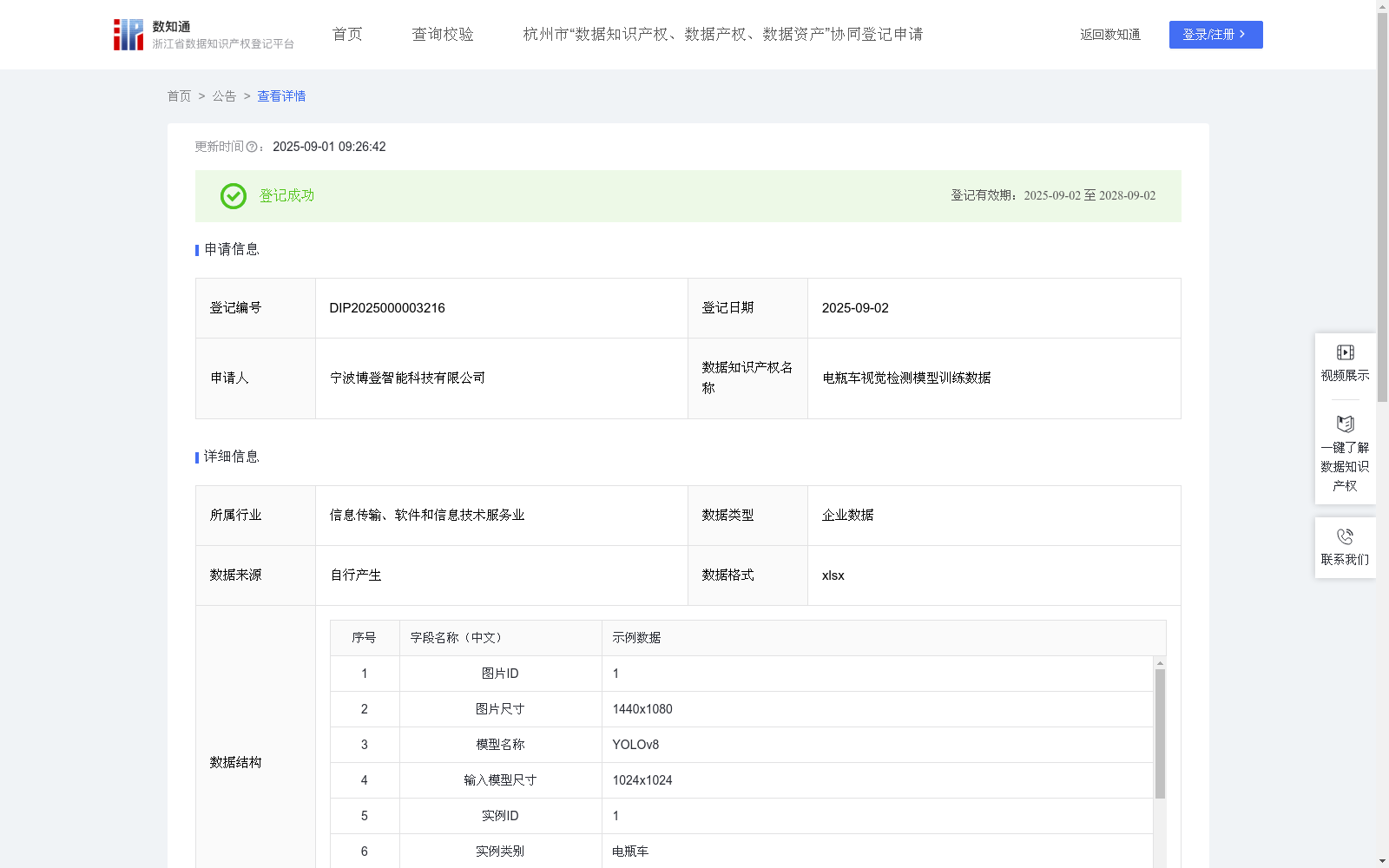
电瓶车视觉检测模型训练数据
收藏浙江省数据知识产权登记平台2025-09-01 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173001
下载链接
链接失效反馈官方服务:
资源简介:
可用于训练和优化目标检测、图像分类等计算机视觉模型,使模型能够学习到电瓶车的特征模式,提高对电瓶车的识别精度和定位准确性,为智能交通系统、安防监控等领域的应用提供更可靠的技术支持。一、图像预处理:将原始图像按照其图片尺寸(如1440x1080)统一缩放到模型名称(YOLOv8)预设的输入模型尺寸。缩放过程中计算特征图分辨率缩放比例,即原始图像宽高分别与输入模型尺寸的比值(例如:宽向缩放比例=输入模型尺寸宽度/图片尺寸宽度=1024/1440,高向缩放比例=输入模型尺寸高度/图片尺寸高度=1024/1080),该比例用于后续将检测框映射回原始图像坐标。同时对图像像素值进行归一化处理,形成归一化像素值范围(固定为[0,1]),以加速模型收敛并提升推理效果。为了增强模型鲁棒性,训练阶段引入数据增强。
二、特征提取:YOLOv8采用高效的骨干网络对预处理后图像进行特征提取。该网络通过多层卷积操作逐步降低特征图的分辨率,同时增加通道数,从而提取图像的多层次特征。随后,利用特征金字塔网络(FPN)和路径聚合网络(PAN)等结构,将不同层次特征图进行融合。这种多尺度特征融合机制显著增强模型对电瓶车和汽车等检测能力,尤其适用复杂场景小目标检测。
三、目标检测:YOLOv8使用多尺度检测头对特征图进行检测,预测每个目标实例的信息:实例类别:目标所属类别(如“电瓶车”);目标框坐标(左上右下):模型直接输出输入模型尺寸下的坐标(如1024x1024尺寸下的坐标);置信度得分:预测结果可信程度。通过这种多尺度检测机制,模型能在不同分辨率下捕捉目标细节,提升检测精度。
四、后处理:在得到初步检测结果后,执行后处理以优化输出,具体包括:置信度过滤:去除置信度得分低于置信度阈值的预测框;非极大值抑制(NMS):依据过滤冗余框的IoU判断重叠框是否为冗余,保留置信度最高的框并抑制其余框。上述两个步骤统称后处理,是提升检测结果准确性和简洁性关键环节。
输出结果:最终输出包含以下信息:实例类别:目标类别标签(如“电瓶车”);目标框坐标(左上右下):目标在原始图像中的位置坐标(基于原始图像尺寸的像素坐标);置信度得分:该检测结果的可信度评分。这些结果可用于违规行为识别等应用场景。
This dataset can be used to train and optimize computer vision models such as object detection and image classification models, enabling the models to learn the characteristic patterns of electric bicycles, improving the recognition accuracy and positioning precision of electric bicycles, and providing more reliable technical support for applications in fields like intelligent transportation systems and security monitoring.
1. Image Preprocessing: Uniformly resize raw images to the input size preset by the model (YOLOv8) according to their original dimensions (e.g., 1440x1080). During resizing, calculate the scaling ratios of feature map resolution, which are the ratios of the input model size to the width and height of the original image respectively (e.g., width scaling ratio = input model width / original image width = 1024/1440; height scaling ratio = input model height / original image height = 1024/1080). This ratio is used to map the detected bounding boxes back to the original image coordinates in subsequent steps. Meanwhile, normalize the pixel values of the images to a fixed range of [0,1], which accelerates model convergence and improves inference performance. To enhance model robustness, data augmentation is introduced during the training phase.
2. Feature Extraction: YOLOv8 adopts an efficient backbone network to perform feature extraction on preprocessed images. This network gradually reduces the resolution of feature maps while increasing the number of channels through multiple convolutional layers, thereby extracting multi-level features of the images. Subsequently, structures such as Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) are used to fuse feature maps of different levels. This multi-scale feature fusion mechanism significantly enhances the model's detection capability for objects like electric bicycles and cars, and is particularly suitable for small object detection in complex scenarios.
3. Object Detection: YOLOv8 uses multi-scale detection heads to detect feature maps and predict the information of each target instance:
- Instance category: the category to which the target belongs (e.g., "electric bicycle");
- Bounding box coordinates (top-left and bottom-right): the coordinates output directly by the model under the input model size (e.g., coordinates under the 1024x1024 size);
- Confidence score: the credibility of the prediction result.
This multi-scale detection mechanism allows the model to capture target details at different resolutions and improve detection accuracy.
4. Post-processing: After obtaining the preliminary detection results, post-processing is performed to optimize the output, which specifically includes:
- Confidence filtering: remove prediction boxes with confidence scores lower than the confidence threshold;
- Non-Maximum Suppression (NMS): judge whether overlapping boxes are redundant based on IoU for filtering redundant boxes, retain the box with the highest confidence and suppress the remaining ones.
The above two steps are collectively referred to as post-processing, which is a key link to improve the accuracy and conciseness of detection results.
Output Results: The final output includes the following information:
- Instance category: target category label (e.g., "electric bicycle");
- Bounding box coordinates (top-left and bottom-right): the pixel coordinates of the target's position in the original image (based on the original image size);
- Confidence score: the credibility score of this detection result.
These results can be used in application scenarios such as violation behavior recognition.
提供机构:
宁波博登智能科技有限公司
创建时间:
2025-04-22
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于电瓶车视觉检测模型训练的专有数据,包含7027条记录,采用YOLOv8模型结构,涉及图像预处理、多尺度特征提取和后处理算法,旨在提高电瓶车识别精度。应用场景包括智能交通系统和安防监控,支持目标检测和图像分类任务。
以上内容由遇见数据集搜集并总结生成


