Vietnamese_RAG
收藏Hugging Face2024-07-26 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/sailor2/Vietnamese_RAG
下载链接
链接失效反馈官方服务:
资源简介:
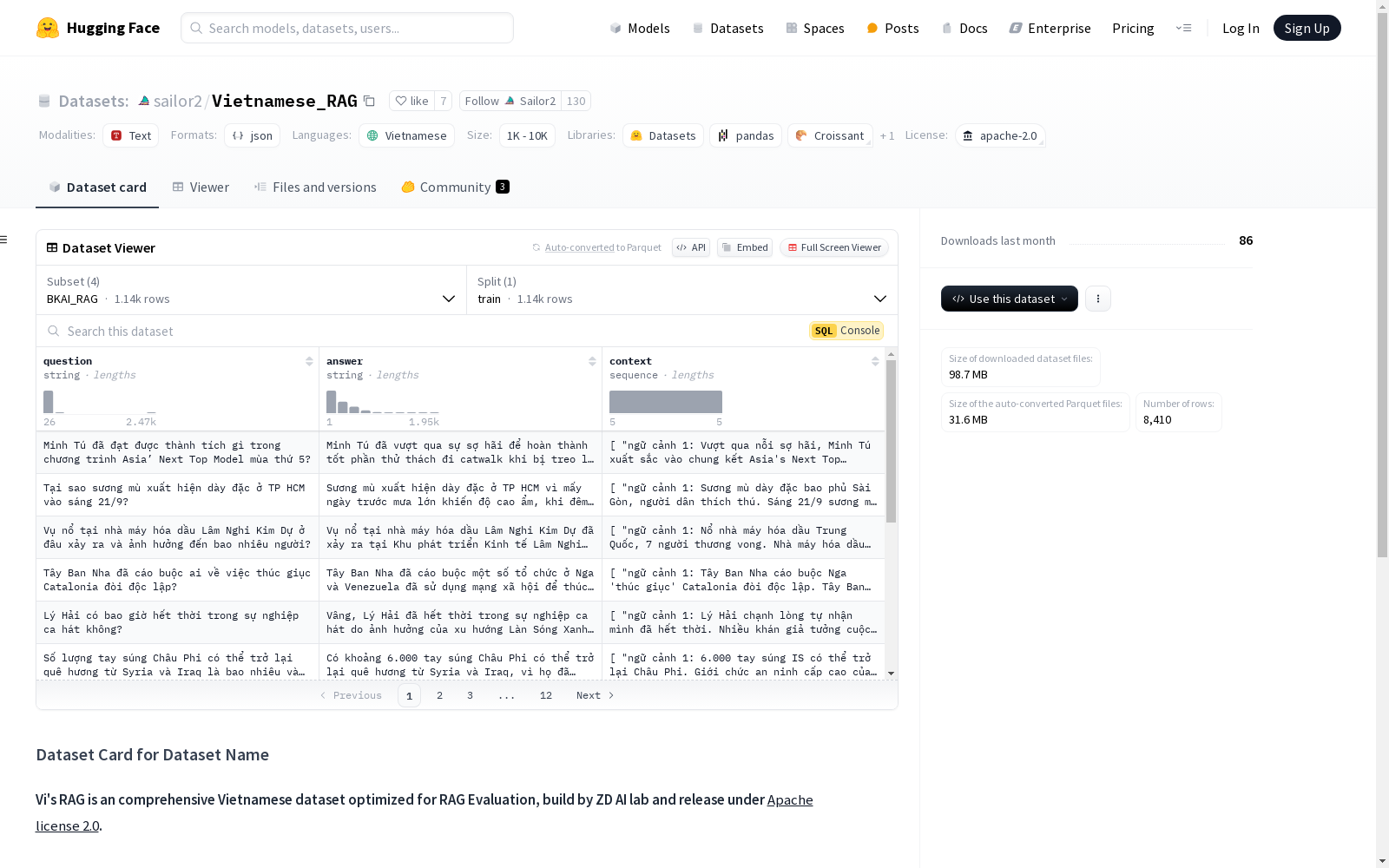
越南语的RAG是一个综合性的越南语数据集,专为RAG评估优化,由ZD AI实验室开发,并根据Apache 2.0许可证发布。该数据集包含四个部分:专家QA的越南语版本,RAG ViQuAD,Legal RAG和BKAI_RAG。每个部分都有特定的细节和来源,例如使用GPT-4进行翻译任务,从UIT-ViQuAD2.0中精心挑选,以及使用Mixtral 8x22B和GPT-4对问题和答案进行对齐。该数据集属于问答任务类别,记录数量在1K到10K之间。
Vietnamese RAG is a comprehensive Vietnamese-language dataset optimized for RAG evaluation, developed by ZD AI Laboratory and released under the Apache 2.0 license. This dataset comprises four components: Vietnamese-language expert QA, RAG ViQuAD, Legal RAG, and BKAI_RAG. Each component has specific details and source materials: for example, translation tasks were completed using GPT-4, the dataset was carefully selected from UIT-ViQuAD2.0, and questions and answers were aligned using Mixtral 8x22B and GPT-4. This dataset falls under the question answering task category, with the number of records ranging from 1K to 10K.
创建时间:
2024-07-17
原始信息汇总
数据集卡片
数据集概述
Vietnameses RAG 是一个针对RAG评估优化的越南语综合数据集,由ZD AI实验室构建并发布,遵循Apache许可证2.0。
数据集详情
该数据集包含四个子数据集:
- Vietnamese version of Expert QA:利用GPT-4的强大翻译能力翻译的Expert QA越南语版本。
- RAG ViQuAD:从UIT-ViQuAD2.0精心挑选并添加了按标题过滤的额外上下文列。
- Legal RAG 和 BKAI_RAG:从ZALO Legal QA和BKNewsCorpus借用的长格式RAG QA,通过Mixtral 8x22B和GPT-4对问题、答案和上下文进行对齐。
数据集配置
- config_name: expert
- data_files: vi_RAG.json
- config_name: viQuAD
- data_files: rag_viQuAD.json
- config_name: LegalRAG
- data_files: modify_legal_corpus.json
- config_name: BKAI_RAG
- data_files: modified_data_BKAI.jsonl
许可证
- license: apache-2.0
语言
- language: vi
任务类别
- task_categories: question-answering
数据集大小
- size_categories: 1K<n<10K
搜集汇总
数据集介绍
构建方式
Vietnamese_RAG数据集由ZD AI实验室构建,旨在为越南语的检索增强生成(RAG)评估提供支持。该数据集包含四个子集,分别基于Expert QA、UIT-ViQuAD2.0、ZALO Legal QA和BKNewsCorpus等现有资源。通过GPT-4的强大翻译能力,Expert QA的越南语版本得以生成;RAG ViQuAD则从UIT-ViQuAD2.0中精选数据,并添加了基于标题的上下文过滤。Legal RAG和BKAI_RAG则分别从ZALO Legal QA和BKNewsCorpus中提取长文本,并通过Mixtral 8x22B和GPT-4对齐问题、答案和上下文。
特点
Vietnamese_RAG数据集的特点在于其多样性和针对性。它不仅涵盖了专家问答、法律问答和新闻语料等多个领域,还特别针对越南语进行了优化。数据集中的每个子集都经过精心筛选和处理,确保上下文与问题的相关性,从而为RAG模型的评估提供了高质量的基准。此外,数据集的构建充分利用了先进的自然语言处理技术,如GPT-4和Mixtral 8x22B,进一步提升了数据的准确性和实用性。
使用方法
Vietnamese_RAG数据集的使用方法主要围绕RAG模型的评估和优化展开。研究人员可以通过加载不同的子集,针对特定领域或任务进行模型训练和测试。数据集中的每个条目均包含问题、答案和上下文信息,用户可以直接将其输入到RAG模型中,评估模型在越南语环境下的表现。此外,数据集的开源性质允许用户根据需求进行进一步的处理和扩展,从而推动越南语自然语言处理领域的研究进展。
背景与挑战
背景概述
Vietnamese_RAG数据集由ZD AI实验室开发,旨在为越南语的检索增强生成(RAG)模型评估提供全面支持。该数据集包含四个子集,分别是基于Expert QA的越南语翻译版本、从UIT-ViQuAD2.0精选的RAG ViQuAD、以及从ZALO Legal QA和BKNewsCorpus中提取的Legal RAG和BKAI_RAG。这些数据集通过GPT-4和Mixtral 8x22B等先进模型进行对齐和优化,确保了数据的高质量和多样性。Vietnamese_RAG的发布为越南语自然语言处理领域的研究提供了重要的资源,推动了该领域的技术进步。
当前挑战
Vietnamese_RAG数据集在构建过程中面临多重挑战。首先,越南语作为一种低资源语言,其语料库的丰富性和多样性相对有限,这为数据集的构建带来了基础性困难。其次,数据集的翻译和对齐任务依赖于GPT-4等大型语言模型,尽管这些模型具备强大的翻译能力,但在处理越南语时仍可能面临语义准确性和文化背景适配的挑战。此外,Legal RAG和BKAI_RAG子集涉及法律和新闻领域的专业文本,其复杂性和专业性要求数据标注和上下文对齐具备极高的精确度,这对数据处理流程提出了更高的要求。
常用场景
经典使用场景
Vietnamese_RAG数据集在越南语自然语言处理领域具有广泛的应用,特别是在基于检索增强生成(RAG)的问答系统中。该数据集通过整合多个越南语问答数据集,提供了丰富的上下文和问题对,使得研究者能够有效地评估和优化RAG模型在越南语环境下的表现。其经典使用场景包括越南语问答系统的开发、跨语言信息检索以及法律和新闻领域的智能问答应用。
衍生相关工作
Vietnamese_RAG数据集的发布催生了一系列相关研究工作,特别是在越南语自然语言处理领域。基于该数据集,研究者开发了多种改进的RAG模型,进一步提升了越南语问答系统的性能。此外,该数据集还被用于跨语言信息检索系统的研究,推动了多语言智能问答系统的发展。这些研究工作不仅丰富了越南语自然语言处理的研究成果,还为其他低资源语言的处理提供了宝贵的经验和参考。
数据集最近研究
最新研究方向
在自然语言处理领域,越南语RAG数据集(Vietnamese_RAG)的推出为越南语问答系统(QA)和检索增强生成(RAG)模型的研究提供了重要支持。该数据集整合了多个子集,包括基于GPT-4翻译的越南语版Expert QA、从UIT-ViQuAD2.0精选的RAG ViQuAD,以及从ZALO Legal QA和BKNewsCorpus衍生的Legal RAG和BKAI_RAG。这些子集通过Mixtral 8x22B和GPT-4对齐了问题、答案和上下文,显著提升了越南语长文本问答的准确性和上下文相关性。当前研究热点集中在如何利用该数据集优化越南语RAG模型的检索和生成能力,特别是在法律和新闻领域的应用。这一进展不仅推动了越南语NLP技术的发展,也为多语言RAG模型的跨语言迁移学习提供了新的研究视角。
以上内容由遇见数据集搜集并总结生成


