HPLT3-198-500k
收藏Hugging Face2025-11-10 更新2025-11-11 收录
下载链接:
https://huggingface.co/datasets/Eurolingua/HPLT3-198-500k
下载链接
链接失效反馈官方服务:
资源简介:
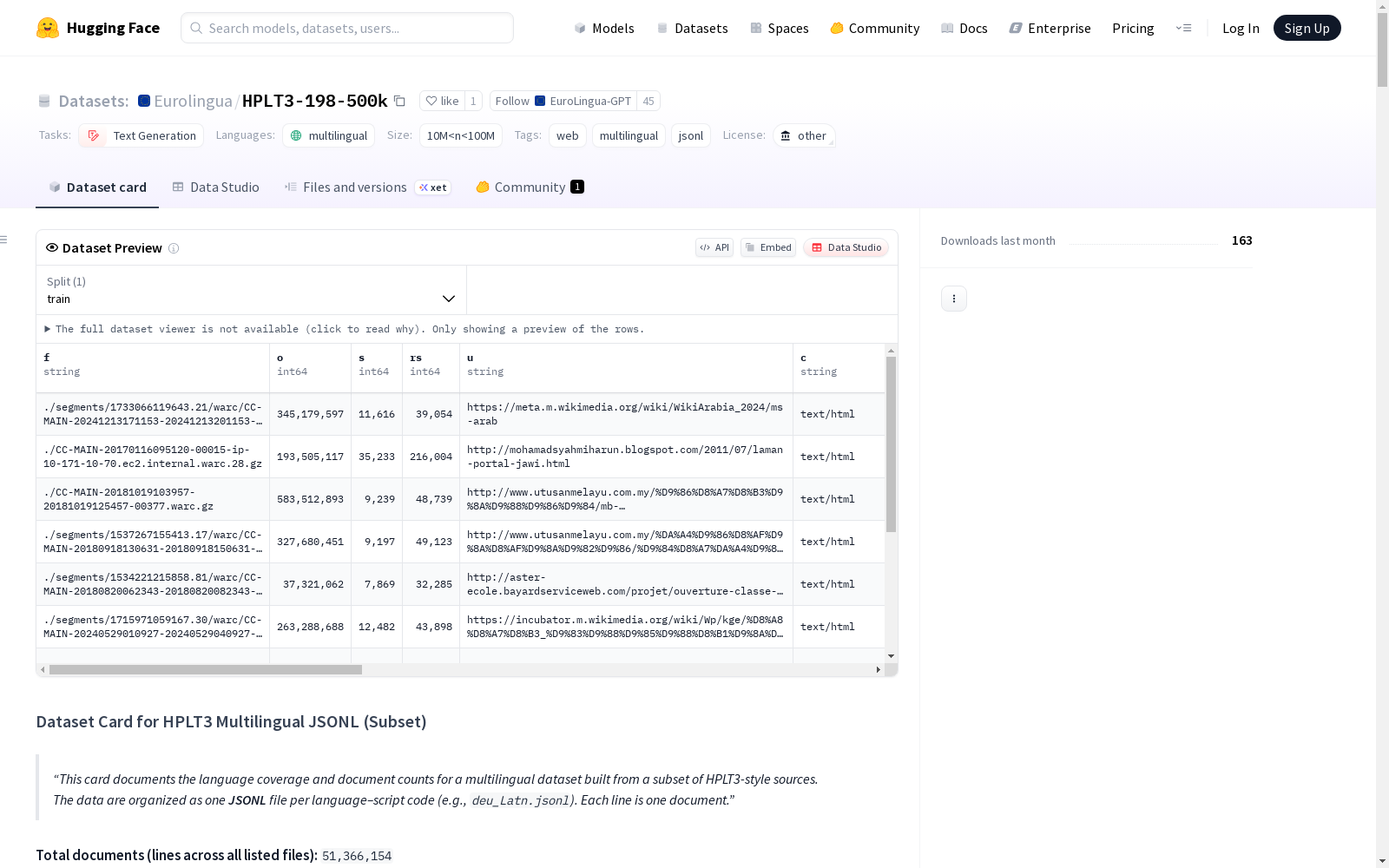
HPLT3 500k子集是一个来自HPLT3风格的多元语言源数据的子集。数据集中的文档以JSON Lines格式组织,每个文档占据一行。该数据集涵盖了多种语言,并根据每种语言的文档数量进行分类,从500k文档到少于1k文档不等。该数据集适用于文本生成任务,并且具有多元语言特性。
创建时间:
2025-11-04
原始信息汇总
HPLT3 500k Subset 数据集概述
数据集基本信息
- 数据集名称: HPLT3 500k Subset
- 任务类别: 文本生成
- 语言创建方式: 从现有资源获取
- 标注创建方式: 无标注
- 数据来源: 原始数据
- 多语言性: 多语言
- 语言: 多语言
- 许可证: 其他
- 规模类别: 10M-100M
- 标签: 网络、多语言、JSONL
数据集格式与结构
- 数据格式: JSON Lines (.jsonl)
- 组织结构: 按语言-文字代码组织文件(例如:deu_Latn.jsonl)
- 总文档数: 51,366,154
语言分布统计
文档数量分组
- 500k文档组: 81种语言
- 100k-499k文档组: 34种语言
- 10k-99k文档组: 29种语言
- 1k-9k文档组: 39种语言
- <1k文档组: 10种语言
主要语言示例
500k文档组(部分)
- 德语 (deu_Latn): 500,000文档,印欧语系日耳曼语族
- 中文简体 (cmn_Hans): 500,000文档,汉藏语系汉语族
- 俄语 (rus_Cyrl): 500,000文档,印欧语系斯拉夫语族
- 日语 (jpn_Jpan): 500,000文档,日本语系
- 法语 (fra_Latn): 500,000文档,印欧语系罗曼语族
100k-499k文档组(部分)
- 阿萨姆语 (asm_Beng): 446,306文档,印欧语系印度-雅利安语支
- 卢森堡语 (ltz_Latn): 407,481文档,印欧语系日耳曼语族
- 土库曼语 (tuk_Latn): 378,448文档,突厥语族
数据实例结构
- 数据字段: text (字符串类型)
- 数据格式: 每行为一个文档字符串
- 使用建议: 如需JSON对象格式,可包装为{"text": <line>}
数据来源
- 来源: HPLT3风格多语言网络提取数据子集
- 文件命名规范: 语言代码_文字.jsonl(例如:fra_Latn.jsonl, jpn_Jpan.jsonl)
更新记录
- 2025-11-04: 初始发布,包含按规模分组的语言表格
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量多语言数据集是推动跨语言模型发展的关键。HPLT3-198-500k数据集基于HPLT3框架从互联网资源中系统采集原始文本,通过语言-文字组合编码(如deu_Latn)进行标准化分类,每个语言单元独立存储为JSONL格式文件,确保文档级数据的完整性与可追溯性。该构建方法采用无标注的原始语料处理流程,通过规模分级策略将193种语言按文档量划分为五个层级,其中81种语言达到50万文档量级,形成层次分明的多语言语料库体系。
特点
该数据集展现出显著的多语言覆盖广度与结构深度,涵盖从印欧语系到孤立语等数十个语族,兼顾简体中文、阿拉伯文等不同文字体系。其核心特征体现在以均等化采样策略保证各语言基础规模,通过语言家族标注提供谱系研究维度,同时采用轻量级JSONL格式实现高效流式处理。数据分布呈现长尾特性,既包含德语、日语等高资源语言,也收录毛利语、约鲁巴语等低资源语种,为语言模型均衡性训练提供重要支撑。
使用方法
在实际应用场景中,研究者可通过按需加载特定语言文件实现精准数据调用,每个JSONL文档行可直接解析为文本训练样本。建议采用流式读取技术处理海量数据,结合语言分类元数据构建多任务学习框架。对于跨语言对比研究,可利用数据集中并行的语族标签开展谱系语言学分析,同时注意根据设备内存动态调整批次加载策略,充分发挥其多尺度、多层级的数据架构优势。
背景与挑战
背景概述
在全球化数字时代背景下,多语言文本生成任务对大规模语料库的需求日益迫切。HPLT3-198-500k数据集作为HPLT项目的最新成果,由国际计算语言学联盟于2025年发布,旨在构建覆盖198种语言的高质量平行语料。该数据集采用JSONL格式组织,包含超过5100万文档,涵盖印欧语系、汉藏语系等十余个语族,其核心价值在于为低资源语言的自然语言处理研究提供了标准化数据支撑。通过均衡采样策略,该数据集有效缓解了传统多语言模型中资源分配不均的问题,为跨语言迁移学习和语义表示研究奠定了重要基础。
当前挑战
构建多语言文本生成数据集面临双重挑战:在领域问题层面,需解决低资源语言语料稀疏性与语言形态多样性导致的模型泛化困难,特别是对于书写系统复杂的语言如阿拉伯文和梵文,传统分词方法难以适用;在构建过程中,原始网络数据的质量筛选与去噪成为关键瓶颈,涉及重复内容过滤、编码标准化及文化敏感性文本处理等技术难题。此外,保持不同语种间数据量级平衡与语义对齐,需要设计复杂的采样算法和跨语言验证机制,这些因素共同构成了数据集构建的核心技术壁垒。
常用场景
经典使用场景
在自然语言处理领域,HPLT3-198-500k数据集凭借其覆盖81种语言的均衡文档分布,成为多语言文本生成任务的重要基准资源。该数据集通过标准化JSONL格式组织语料,为跨语言模型预训练提供了高质量的平行语料支持,尤其在低资源语言建模中展现出独特价值。其文档规模与语言多样性相结合的特性,使得研究者能够系统评估模型在复杂语言环境下的泛化能力。
实际应用
在实际应用层面,该数据集为构建全球化智能服务系统提供了语言基础设施。基于其丰富的语种覆盖,可开发支持波斯语、乌尔都语等关键语言的机器翻译系统,增强跨文化沟通效率。在内容审核领域,数据集中的多语言文本有助于训练更精准的敏感信息检测模型,同时为数字图书馆的跨语言检索功能提供核心语料支撑。
衍生相关工作
该数据集的发布催生了多语言模型研究的新范式,例如基于其语料训练的XLM-R系列模型在跨语言理解任务中取得突破性进展。后续研究通过该数据集验证了语言家族特征对模型性能的影响机制,衍生出针对低资源语言的课程学习策略。在语种识别方向,该数据集支撑了新型语言分类器的开发,推动了语言技术生态的多元化发展。
以上内容由遇见数据集搜集并总结生成


