COREval
收藏arXiv2024-11-27 更新2024-11-29 收录
下载链接:
http://arxiv.org/abs/2411.18145v1
下载链接
链接失效反馈官方服务:
资源简介:
COREval是由武汉大学国家重点实验室LIESMARS创建的,旨在全面客观评估大型视觉语言模型在遥感领域的感知和推理能力。数据集包含6263个问题,涵盖21个任务,涉及图像级别的理解、单实例识别和跨实例辨别等多个维度。数据集通过从全球50个城市收集的遥感图像构建,避免了公开数据集的使用,确保了数据的独特性和客观性。COREval的应用领域主要集中在遥感图像的分类、视觉定位和视觉推理等任务,旨在解决现有模型在遥感领域能力评估不足的问题。
COREval was developed by the State Key Laboratory of LIESMARS at Wuhan University, aiming to comprehensively and objectively evaluate the perception and reasoning capabilities of large vision-language models in the remote sensing domain. The dataset consists of 6,263 questions covering 21 tasks, spanning multiple dimensions including image-level understanding, single-instance recognition and cross-instance discrimination. Constructed using remote sensing images collected from 50 cities worldwide, it avoids the use of public datasets to ensure the uniqueness and objectivity of the data. The main application scenarios of COREval focus on tasks such as remote sensing image classification, visual localization and visual reasoning, aiming to address the gap in adequate capability evaluation for existing models in the remote sensing field.
提供机构:
武汉大学
创建时间:
2024-11-27
搜集汇总
数据集介绍
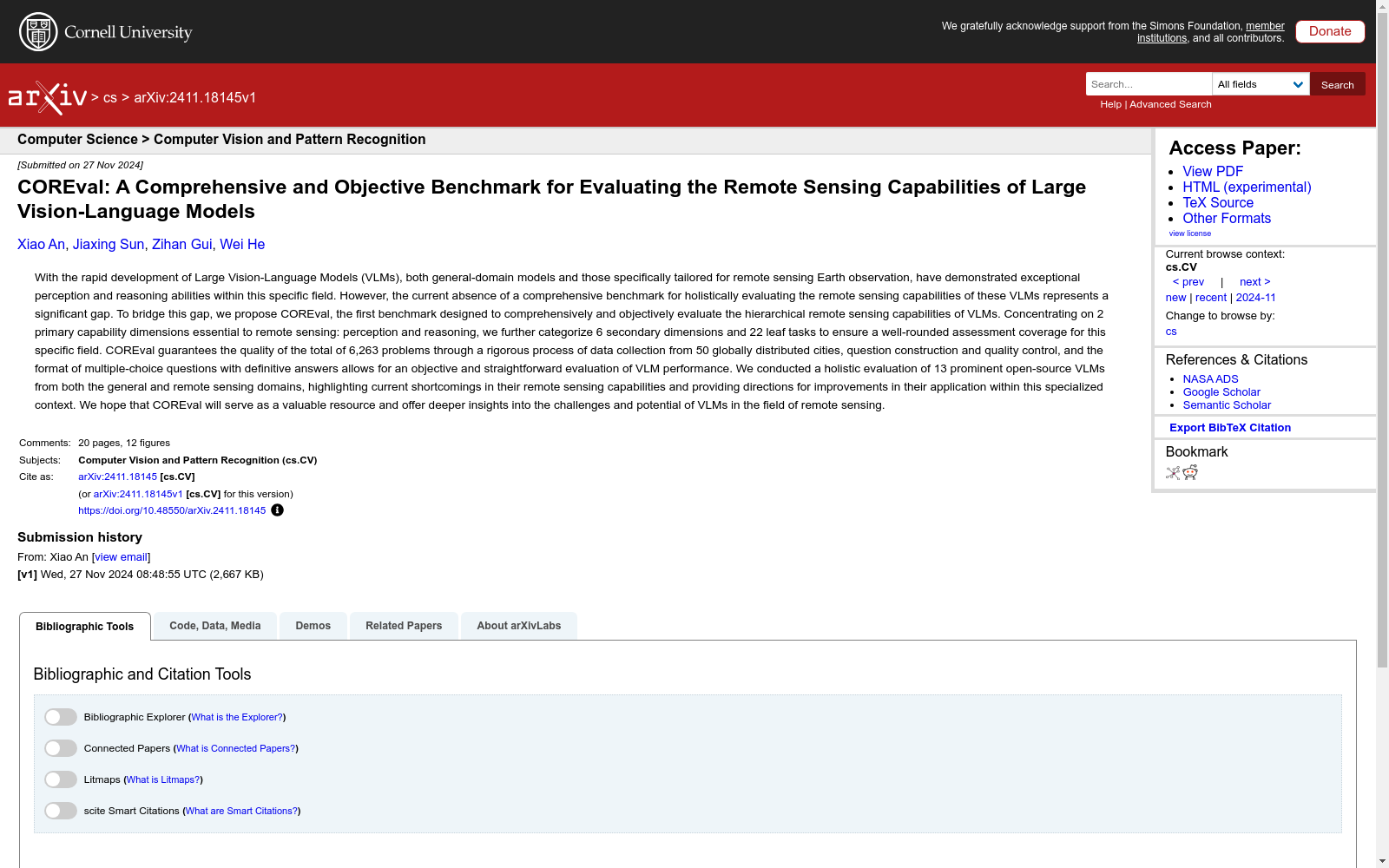
构建方式
COREval数据集通过严格的构建过程确保了其全面性和客观性。首先,数据集从全球50个分布广泛的城市中收集了6,263个问题,涵盖了感知和推理两大核心能力维度。其次,问题构建采用了三种方法:标签驱动构建、基础模型驱动构建和人类-GPT4协作构建。最后,通过多阶段的质量控制流程,包括12名专业背景的志愿者参与,确保了问题的准确性和质量。
使用方法
使用COREval数据集进行评估时,首先需要根据模型的类型选择合适的评估策略。对于基于LLM的视觉语言模型,可以直接输出A/B/C/D选项或相应的内容,便于后续的选择提取和准确率计算。对于基于CLIP的模型,则需要将多选题转换为n个陈述句,并通过计算RSI与每个句子之间的相似度得分来确定模型的响应。评估过程中,应确保模型在所有任务上的表现均得到客观和全面的评价。
背景与挑战
背景概述
随着大型视觉-语言模型(VLMs)的快速发展,无论是通用领域模型还是专门针对遥感地球观测的模型,都在这一特定领域展示了卓越的感知和推理能力。然而,当前缺乏一个全面的基准来全面评估这些VLMs的遥感能力,这成为一个显著的缺口。为了填补这一空白,我们提出了COREval,这是首个旨在全面和客观评估VLMs层次化遥感能力的基准。COREval专注于遥感中两个关键的能力维度:感知和推理,并进一步细分为六个二级维度和22个叶任务,以确保对该特定领域的全面评估覆盖。
当前挑战
COREval面临的挑战包括:1) 解决领域问题的复杂性,如图像分类和实例识别;2) 构建过程中遇到的挑战,如数据收集的多样性和质量控制。具体来说,COREval需要从50个全球分布的城市收集数据,确保数据的广泛地理覆盖和多样性。此外,构建过程中采用了三种方法来生成问题,并进行了严格的质量控制,以确保所有问题的准确性和客观性。这些挑战不仅要求技术上的创新,还需要对遥感领域的深入理解和实践经验。
常用场景
经典使用场景
COREval数据集的经典使用场景在于评估大型视觉-语言模型(VLMs)在遥感领域的感知和推理能力。通过集中于感知和推理这两个主要能力维度,COREval进一步细分为六个次级维度和22个叶任务,确保对遥感特定领域的全面评估覆盖。该数据集通过严格的流程,从全球50个分布城市收集数据,构建和质量控制问题,并采用多选题形式,确保对VLM性能的客观和直接评估。
解决学术问题
COREval数据集解决了当前缺乏全面评估大型视觉-语言模型在遥感领域能力的问题。通过提供一个综合且客观的基准,COREval不仅反映了VLMs的进展,还指导了未来的研究方向。该数据集通过多维度的评估,揭示了现有模型在遥感能力方面的不足,并为改进其在该专业领域的应用提供了方向。
实际应用
COREval数据集在实际应用中具有广泛的价值,特别是在需要高精度遥感图像分析的领域,如环境监测、灾害评估和资源管理。通过评估和提升VLMs在遥感图像理解和推理方面的能力,COREval有助于开发更高效和准确的遥感应用系统,从而在实际操作中提供更可靠的数据支持。
数据集最近研究
最新研究方向
在遥感领域,大型视觉-语言模型(VLMs)的快速发展引发了对其感知和推理能力全面评估的需求。COREval数据集应运而生,成为首个针对VLMs在遥感能力上进行综合和客观评估的基准。该数据集聚焦于感知和推理两大核心能力维度,进一步细分为六个次级维度和二十二个叶任务,确保了对遥感特定领域的全面覆盖。COREval通过严格的全球50个城市数据收集和多重质量控制流程,构建了6,263个问题,采用多选题形式,确保评估的客观性和直接性。研究结果揭示了当前VLMs在基本遥感能力上的表现,同时也指出了在细粒度对象感知和复杂推理任务上的显著不足,为未来模型在遥感应用中的改进提供了方向。
相关研究论文
- 1COREval: A Comprehensive and Objective Benchmark for Evaluating the Remote Sensing Capabilities of Large Vision-Language Models武汉大学 · 2024年
以上内容由遇见数据集搜集并总结生成


