COOPER
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/CelfAI/COOPER
下载链接
链接失效反馈官方服务:
资源简介:
COOPER 是一个开源的移动网络性能测量时间序列合成数据集,旨在支持无线网络中可重复的AI/ML研究。数据集模拟了真实5G网络性能测量数据的统计分布、时间动态和结构模式,同时不包含任何敏感或运营商可识别的信息。数据集包含45个性能指标,覆盖84个小区,12个基站,地理区域约1.35平方公里,数据采集周期为31天,采样间隔为1小时。数据表示形式为多小区时间序列。数据集适用于时间序列预测研究、网络异常检测、AI/ML基准测试、根因分析建模、RAN性能优化研究以及5G/6G系统中的可重复学术研究。数据集还附带一个可重复的评估框架,用于比较不同的合成数据生成方法。
COOPER is an open-source time-series synthetic dataset for mobile network performance measurements, designed to support reproducible AI/ML research in wireless networks. This dataset mimics the statistical distributions, temporal dynamics, and structural patterns of real 5G network performance measurement data, while excluding any sensitive or carrier-identifiable information. It includes 45 performance metrics, covering 84 cells and 12 base stations across a geographic area of approximately 1.35 square kilometers. The data collection period spans 31 days, with a sampling interval of 1 hour. The data is represented as multi-cell time series. This dataset is applicable to research in time series forecasting, network anomaly detection, AI/ML benchmarking, root cause analysis modeling, RAN performance optimization, and reproducible academic research in 5G/6G systems. The dataset also comes with a reproducible evaluation framework for comparing different synthetic data generation methods.
创建时间:
2026-01-29
原始信息汇总
COOPER 数据集概述
数据集基本信息
- 名称: COOPER (Cellular Operational Observations for Performance and Evaluation Research)
- 许可证: Apache 2.0
- 主要语言: 英语 (en)
- 标签: mobileNetwork, 5G
- 任务ID: univariate-time-series-forecasting, multivariate-time-series-forecasting
数据集配置与文件
数据集包含以下配置及对应的数据文件:
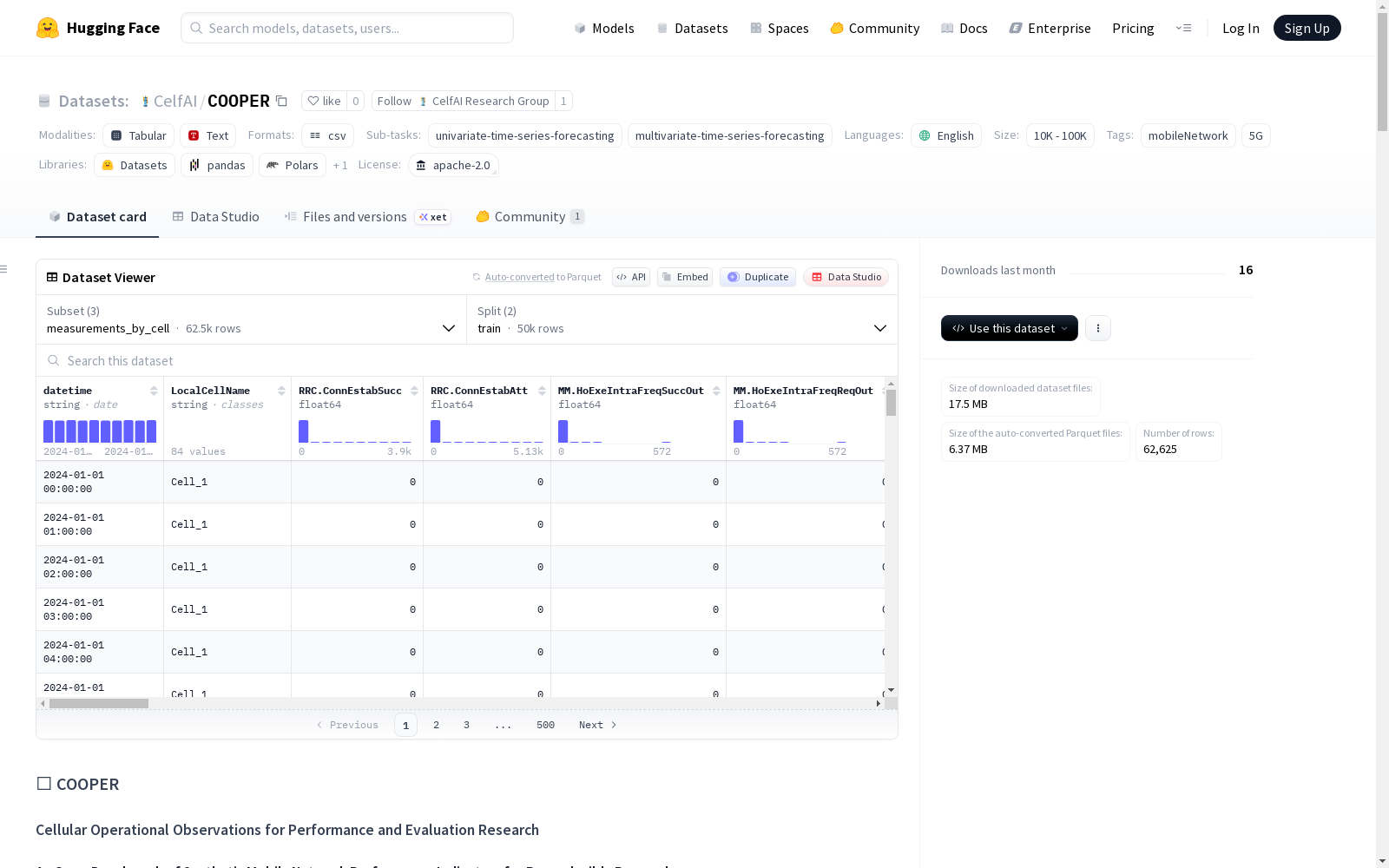
- measurements_by_cell:
train分割:dataset/train_data.csvtest分割:dataset/test_data.csv
- topology:
main分割:metadata/topology.csv
- performance_indicators_meanings:
main分割:metadata/performance_indicators_meanings.csv
数据集简介
COOPER 是一个开源的、合成的移动网络性能测量时间序列数据集,旨在支持无线网络中可重复的人工智能/机器学习研究。该数据集以蜂窝通信先驱 Martin Cooper 的名字命名。它模拟了真实 5G 网络性能管理数据的统计分布、时间动态和结构模式,同时不包含任何敏感或运营商可识别信息。
创建动机
由于保密协议、隐私法规和商业敏感性,获取真实的电信性能管理/关键绩效指标数据通常受到限制。这种开放数据的缺乏限制了无线网络人工智能驱动研究的可重复性。COOPER 通过提供一个现实且保护隐私的合成替代方案来弥补这一差距。
数据生成方法
为生成 COOPER,评估了三种互补的合成数据生成范式:
- 对抗性方法
- 概率模型
- 基于模型的时间序列方法 这些方法通过一个统一的定量和定性评估框架进行基准测试,该框架考虑了分布相似性、时间保真度、形状对齐、判别性能和下游预测能力。选择在上述标准中表现最平衡、最一致的生成器来生成 COOPER。
源数据特征(匿名化前)
用于建模合成数据的真实数据集经过完全匿名化处理,并进行了清理和标准化。
| 属性 | 值 |
|---|---|
| 无线接入技术 | 5G |
| 性能管理指标数量 | 45 |
| 小区总数 | 84 |
| 基站数量 | 12 |
| 地理区域 | ~1.35 km² |
| 收集周期 | 31 天 |
| 采样间隔 | 1 小时 |
| 数据表示形式 | 多小区时间序列 |
网络部署特征
建模的网络包含两个频段和两种 5G 架构:
| 频段 | 架构 | 小区数量 |
|---|---|---|
| N28 (700 MHz) | Option 2 (独立组网) | 6 |
| N28 (700 MHz) | Option 3 (非独立组网) | 48 |
| N78 (3500 MHz) | Option 2 (独立组网) | 6 |
| N78 (3500 MHz) | Option 3 (非独立组网) | 24 |
性能管理指标类别
指标遵循 3GPP TS 28.552 性能测量定义,分为以下几类:
- 无线资源控制连接: 用于建立用户设备无线连接和跟踪活跃用户的程序。
- 移动性管理: 跨频率的切换和重定向性能。
- 信道质量指示: 下行链路信道质量报告的分布。
- 吞吐量和数据量: 流量和传输时长。
- 可用性: 由于故障或节能机制导致的小区停机。
- 用户设备上下文: 用户会话建立尝试和成功次数。
基准测试框架
COOPER 附带一个可重复的评估流程,允许研究人员使用以下方法比较合成数据生成器:
- 统计相似性度量
- 时间对齐度量
- 基于形状的相似性
- 分类可区分性
- 预测任务性能
预期用途
COOPER 适用于:
- 时间序列预测研究
- 网络异常检测
- 人工智能/机器学习基准测试
- 根本原因分析建模
- 无线接入网络性能优化研究
- 5G/6G 系统中可重复的学术研究
贡献与可重复性
该项目旨在促进开放和可重复的电信人工智能研究。鼓励研究人员使用提供的框架对新生成模型进行基准测试、分享改进和衍生数据集,并在相同的评估协议下比较方法。
搜集汇总
数据集介绍
构建方式
在移动通信网络研究领域,真实运营数据常因商业机密与隐私法规而难以获取,COOPER数据集通过合成数据生成技术填补了这一空白。其构建过程系统评估了对抗生成、概率建模与基于模型的时间序列方法等多种生成范式,并采用统一的量化与定性评估框架,从分布相似性、时序保真度、形态对齐及下游预测性能等维度进行综合比较,最终选取表现最为均衡的生成器来合成数据。该数据集以真实5G网络性能测量数据为蓝本,经过彻底的匿名化与标准化处理,确保了数据在统计特性与动态模式上的真实性,同时完全剥离了敏感信息。
使用方法
该数据集旨在为无线网络人工智能研究提供可复现的基准平台。研究人员可通过加载不同的配置项,分别获取以小区为单位的性能测量时间序列训练集与测试集、网络拓扑关系以及性能指标释义表。数据集适用于多元与单元时间序列预测、网络异常检测、根因分析建模及无线接入网性能优化等一系列任务。随数据集发布的标准化评估框架允许研究者使用统一的统计相似性度量、时序对齐指标与预测任务性能评估方法,对不同合成数据生成技术进行基准测试,从而推动移动网络领域机器学习研究的透明化与可比性。
背景与挑战
背景概述
在第五代移动通信技术迅猛发展的时代背景下,网络性能数据的开放获取成为推动人工智能与机器学习在无线网络领域创新研究的关键瓶颈。COOPER数据集应运而生,其命名旨在向蜂窝通信先驱马丁·库珀致敬,由致力于推动可重复性研究的学术或工业界团队于近年创建。该数据集的核心研究问题在于解决真实电信性能测量数据因商业机密、隐私法规等限制而难以获取的困境,通过生成合成数据来模拟5G网络性能指标的统计分布、时间动态与结构模式。COOPER的发布为网络监控、关键绩效指标预测、异常检测及5G/6G性能评估等研究方向提供了高质量的基准数据,显著增强了相关领域研究的可复现性与可比性,对无线网络智能化研究产生了深远影响。
当前挑战
COOPER数据集致力于解决无线网络性能分析与预测这一领域问题,其核心挑战在于如何确保合成数据在分布相似性、时间保真度及形态对齐等多个维度上高度逼近真实网络数据,同时完全剥离敏感或可识别信息以符合隐私要求。在构建过程中,研究团队面临多重挑战:首先,需要设计并评估对抗生成、概率模型及基于模型的时间序列方法等多种合成数据生成范式,以筛选出在统计相似性与下游预测任务间取得最佳平衡的生成器;其次,必须基于真实匿名化数据建立统一的定量与定性评估框架,涵盖判别性能与预测能力等复杂指标,确保合成数据的实用性与可靠性。这些挑战的克服是数据集得以成功构建并服务于可复现研究的基础。
常用场景
经典使用场景
在移动通信网络研究领域,COOPER数据集为时间序列预测任务提供了标准化的基准平台。该数据集模拟了真实5G网络性能指标的统计分布与动态特征,涵盖45个性能指标,跨越84个蜂窝单元,采样间隔为一小时,持续31天。研究人员可基于此数据集,开发并验证多元时间序列预测模型,以准确预估网络负载、吞吐量等关键性能指标的未来趋势,从而优化资源分配策略。
解决学术问题
COOPER数据集有效解决了电信领域因数据敏感性导致的公开基准缺失问题。通过提供高度逼真且完全匿名的合成数据,它支持了网络性能预测、异常检测、根因分析等方向的复现性研究。该数据集遵循3GPP标准定义,涵盖了RRC连接、移动性管理、信道质量等多类指标,为评估人工智能模型在无线网络环境中的泛化能力与鲁棒性奠定了坚实基础。
实际应用
在实际网络运维中,COOPER数据集可用于训练智能监控系统,实现网络性能的主动管理与故障预警。运营商可借助基于该数据构建的模型,预测小区级流量波动,提前进行容量规划;或识别吞吐量下降、连接失败率升高等异常模式,辅助自动化根因定位。这显著提升了5G/6G网络运营的效率与可靠性。
数据集最近研究
最新研究方向
在移动通信网络智能化研究领域,COOPER数据集作为首个开源的合成移动网络性能指标基准,正推动着5G/6G网络AI原生自动化方向的前沿探索。该数据集通过模拟真实5G网络数据的统计分布与时序动态,为受限的电信数据访问提供了隐私安全的替代方案,促进了网络性能预测、异常检测及根因分析等任务的复现性研究。当前热点聚焦于利用生成对抗网络与概率模型提升合成数据的时空保真度,以支持网络数字孪生与自主优化系统的开发,其标准化评估框架亦成为比较不同生成方法的关键工具,加速了AI驱动无线网络研究的可重复创新。
以上内容由遇见数据集搜集并总结生成


