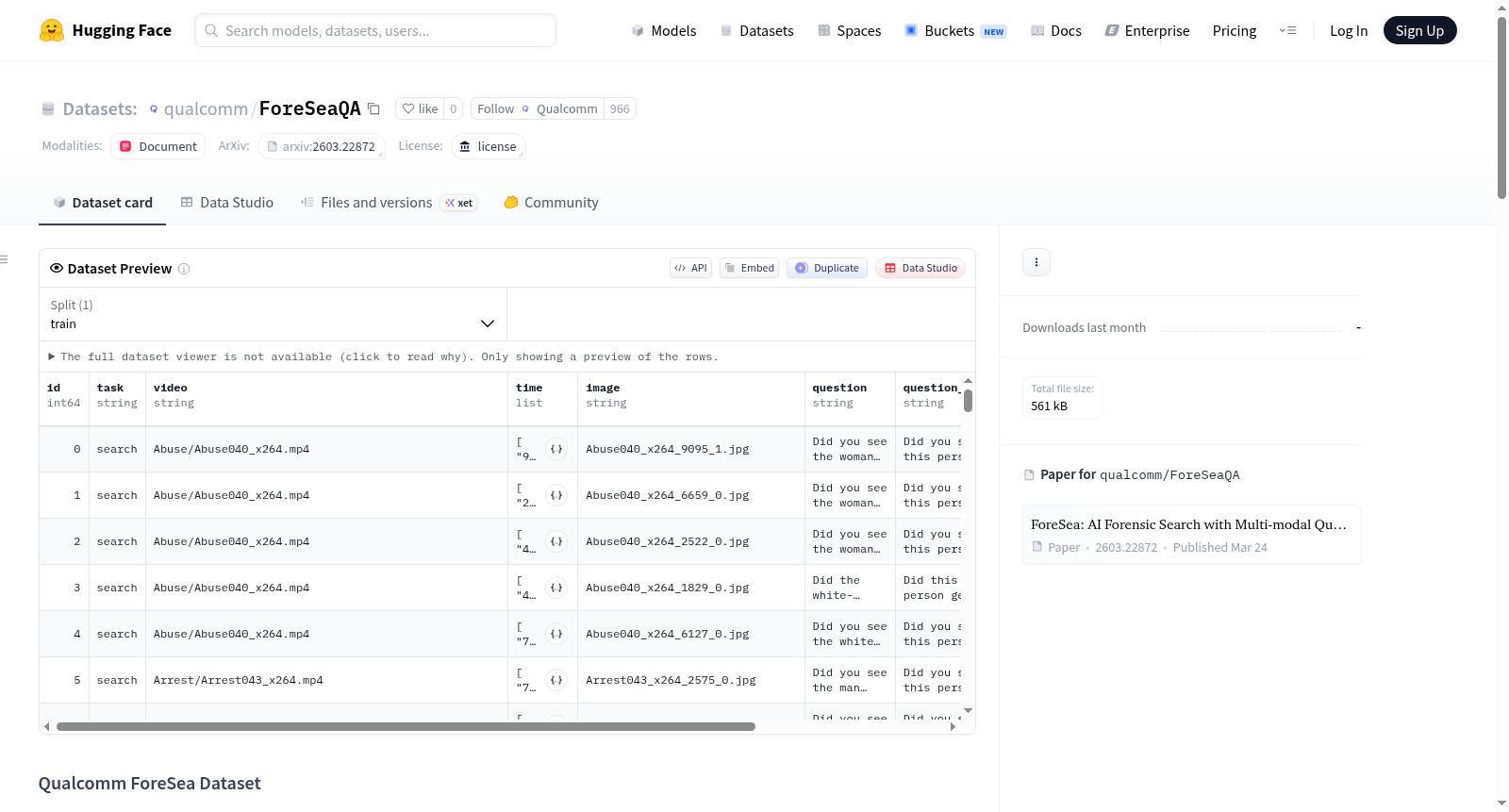
ForeSeaQA
收藏ForeSeaQA 数据集概述
基本信息
- 数据集名称:ForeSeaQA
- 发布机构:Qualcomm AI Research
- 许可证:仅限研究用途(Research Use)
- 数据集地址:https://huggingface.co/datasets/qualcomm/ForeSeaQA
数据集描述
ForeSeaQA 是一个面向视频监控/法医搜索领域的视频问答(VideoQA) 基准数据集,专门用于评估视频大语言模型(VideoLLMs)和视频检索增强生成(Video-RAG)系统在真实分析工作流中的表现。该数据集支持多模态查询,即结合参考图像(如人物快照)与文本问题进行推理。
评估维度
ForeSeaQA 联合评估以下三方面能力:
- 答案准确性(多项选择正确率)
- 时间定位能力(预测包含充分证据的时间区间)
- 多模态查询推理(图像+文本组合查询)
查询类型
- 纯文本查询:仅包含问题文本
- 多模态查询:
Q = (Q_I, Q_T),其中Q_I为参考图像,Q_T为引用该图像的文本问题(例如:“照片中的人何时进入大楼?”)
任务类别
数据集包含六个子任务:
- 搜索(Search, SE)
- 活动(Activity, AC)
- 事件(Event, EV)
- 时间(Temporal, TM)
- 计数(Counting, CT)
- 异常(Anomaly, AN)
数据构建流程
ForeSeaQA 采用半自动数据引擎生成:
- 从密集描述中提取人物实体
- 对实体进行视觉定位,生成查询图像裁剪
- 生成带有时间戳范围的问答对
- 人工验证问答有效性、答案正确性和时间定位准确性
视频来源
数据集使用的视频来自 UCF-Crime 数据集,该数据集是一个大规模监控视频数据集,包含约 128小时/1,900个视频,最初用于异常检测研究。
UCF-Crime 数据集链接:https://www.crcv.ucf.edu/research/real-world-anomaly-detection-in-surveillance-videos/
仓库内容
AI_Forensic-QA.json:ForeSeaQA 注释文件(问题、多项选择选项、正确答案、时间戳、任务类型等)ForeSea_QA_image_mapping.json:用于生成/查询多模态问题参考图像的映射元数据crop_image.py:利用ForeSea_QA_image_mapping.json从 UCF-Crime 视频中裁剪查询图像的工具脚本
使用方式
用户需从官方来源下载 UCF-Crime 视频,然后运行 crop_image.py 脚本生成查询图像。
引用信息
若使用该数据集进行研究,请引用以下论文:
@misc{park2026foreseaaiforensicsearch, title={ForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance}, author={Hyojin Park and Yi Li and Janghoon Cho and Sungha Choi and Jungsoo Lee and Taotao Jing and Shuai Zhang and Munawar Hayat and Dashan Gao and Ning Bi and Fatih Porikli}, year={2026}, eprint={2603.22872}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2603.22872}, }