flwrlabs/fed-phishing-urls
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/flwrlabs/fed-phishing-urls
下载链接
链接失效反馈官方服务:
资源简介:
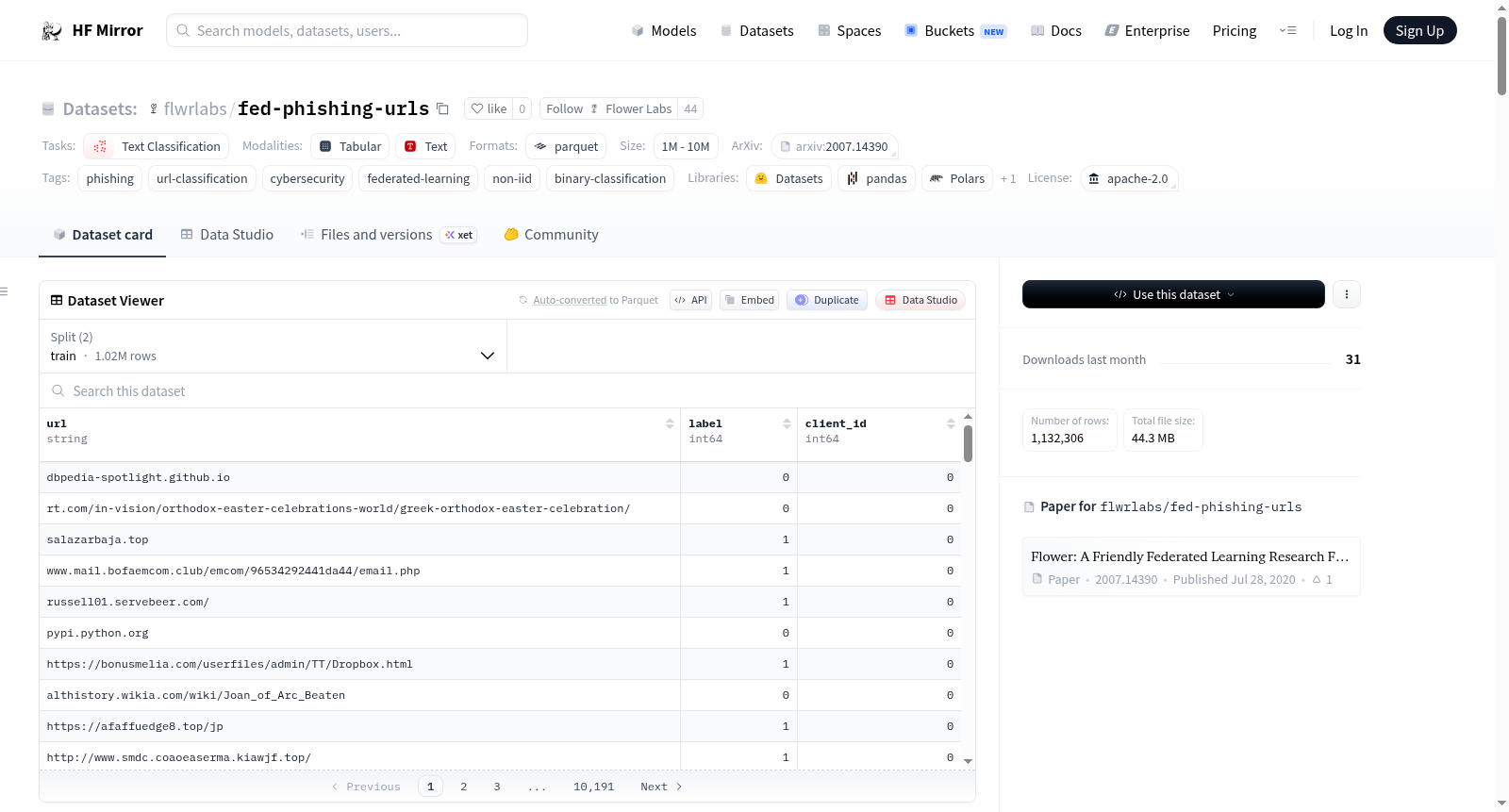
该数据集是一个联邦学习、非独立同分布(non-IID)钓鱼URL分类基准数据集,来源于两个公开的Hugging Face数据集。数据集包含URL字符串、二进制钓鱼标签(1表示钓鱼或恶意,0表示良性或合法)和模拟客户端ID字段(范围0到99)。数据集经过预处理,包括URL字符串和标签的合并、去重、特征提取、客户端分配和分割等步骤。数据集分为训练集和测试集,适用于联邦二元分类、跨客户端泛化研究、非IID鲁棒性基准测试、钓鱼URL检测、网络安全模型评估等用途。
This dataset is a federated, non-IID phishing URL classification benchmark derived from two public Hugging Face datasets. It contains URL strings, binary phishing labels (1 for phishing or malicious, 0 for benign or legitimate), and a simulated client ID field (ranging from 0 to 99). The dataset has undergone preprocessing steps including merging URL strings and labels, deduplication, feature extraction, client allocation, and splitting. It is divided into training and test sets and is suitable for federated binary classification, cross-client generalization studies, non-IID robustness benchmarking, phishing URL detection, cybersecurity model evaluation, and other uses.
提供机构:
flwrlabs
搜集汇总
数据集介绍
构建方式
该数据集通过整合两个公开HuggingFace数据集构建而成,分别是ealvaradob/phishing-dataset与kmack/Phishing_urls,融合了其中的URL字符串与二分类标签。在预处理阶段,先对URL进行小写转换与百分号解码,完成基于字节表示的全局去重,随后提取每个URL的粗粒度特征桶(如ip_host、shortener等)。采用非独立同分布的客户端优先分配策略,将去重后的样本按数量偏斜、标签偏斜与特征偏斜模拟分配给100个客户端。每个客户端的数据再按约9:1的比例分层划分为本地训练集与测试集,最终将各客户端的本地切片拼接为全局的训练集与测试集。
特点
该数据集的核心特点在于其联邦学习友好的非独立同分布性质。通过从对数正态分布中采样客户端大小并在标签层面利用贝塔分布调控钓鱼样本的流行倾向,模拟了现实世界中客户端数据数量与分布的异质性。同时,基于特征桶为每个客户端分配偏好的URL模式(如短链接或可疑顶级域),引入了语义维度的数据偏斜。数据集包含超过百万条训练样本与十万余条测试样本,每条记录均附有URL原文、二分类标签及模拟客户端标识,便于开展跨客户端泛化与鲁棒性基准研究。
使用方法
用户可通过HuggingFace datasets库加载该数据集,示例代码为`load_dataset('flwrlabs/fed-phishing-urls')`,即可获取训练与测试分片。若需进行联邦学习实验,推荐使用Flower Datasets库中的FederatedDataset与NaturalIdPartitioner,依据client_id字段将数据自然划分至各个客户端分区。加载后可通过字段名称(如url、label、client_id)访问各数据项。请注意,数据集中包含真实钓鱼URL,应在安全沙箱环境中处理,避免直接访问这些链接。
背景与挑战
背景概述
在网络安全的严峻挑战中,钓鱼(phishing)攻击作为窃取用户敏感信息的核心手段,其检测技术始终是学术界与工业界关注的焦点。联邦学习作为一种隐私保护范式,能够在多方数据不出本地的前提下联合训练模型,为钓鱼URL的跨组织协同检测开辟了新路径。由Flower Labs主导的fed-phishing-urls数据集于近年创建,旨在填补联邦学习场景下非独立同分布(non-IID)钓鱼URL分类基准的空白。该数据集融合了ealvaradob/phishing-dataset与kmack/Phishing_urls两个公开来源,通过精心设计的预处理流程——包括URL标准化去重、特征桶提取与基于数量和分布的异构客户端分配——构建了一个包含100个模拟客户端、逾百万条样本的标准评测平台。其发布推动了联邦学习在网络安全领域的鲁棒性研究,为跨客户端泛化与分布偏移分析提供了关键资源。
当前挑战
fed-phishing-urls数据集所应对的领域问题挑战在于,真实世界中钓鱼URL的分布高度非独立同分布:不同组织的用户群体在URL模式(如短链接、可疑顶级域、深层子域)上存在显著偏好,且钓鱼样本比例因地域与防护策略而异。传统集中式分类器难以建模这种异构性,导致在全局性能优异时,局部客户端面临严重的分布偏移与过拟合风险。在构建过程中,研究人员遭遇了多项技术障碍:一是如何从公开数据集中精确合并并去除重复URL,尤其是面对编码格式混淆的文本;二是设计启发式特征桶以模拟真实客户端的URL偏好,既需保持可解释性又要避免信息泄露;三是采用对数正态采样与贝塔分布控制客户端数量及标签倾斜,同时引入温度参数调节特征偏好强度,确保非IID属性符合实际联邦场景。此外,钓鱼URL的时效性导致数据集难以反映当前威胁态势,加之上游标注可能存在噪声,模型的跨时间泛化能力仍需审慎评估。
常用场景
经典使用场景
在网络安全与隐私保护的交叉领域,fed-phishing-urls数据集被广泛应用于联邦学习框架下的钓鱼URL检测任务。该数据集通过模拟100个非独立同分布(non-IID)的客户端,真实再现了分布式环境中各节点数据分布不均的挑战。研究者常利用该数据集评估联邦学习算法在面对客户端数量倾斜、标签偏好差异以及特征分布偏移时的鲁棒性。其经典使用场景包括:在保持数据不出本地的前提下,协同训练一个全局的钓鱼网址二分类模型,从而在保护用户隐私的同时提升跨客户端的泛化能力。
解决学术问题
该数据集系统性地解决了联邦学习中数据异构性带来的学术难题,尤其是非独立同分布数据下的模型收敛与性能退化问题。通过引入标签偏斜和特征偏斜的生成机制,fed-phishing-urls为验证个性化联邦学习、聚类联邦学习及梯度压缩等方法的有效性提供了标准化基准。其意义在于,将真实世界的钓鱼URL分布与模拟的客户端异构性相结合,推动了隐私保护机器学习在网络安全领域的理论进展,使研究者能够深入剖析客户端漂移对全局模型准确率的影响,并催生了针对长尾攻击模式的新型检测策略。
衍生相关工作
围绕fed-phishing-urls数据集已衍生出多项经典研究工作,涵盖数据分区策略优化与模型聚合算法创新。例如,Flower框架将其作为非IID场景的默认测试集,用于评估FedAvg、FedProx等聚合算法的收敛速度。后续工作进一步提出了基于URL语义特征的客户端聚类方法,将特征偏斜参数与图神经网络相结合,以增强对短链接及混淆域名的识别能力。此外,该数据集还被用于验证梯度扰动和差分隐私机制在钓鱼检测中的有效性,催生了诸如FedURLShield等兼具隐私保护与高检测率的联邦学习原型系统,为产学研深度融合提供了范本。
以上内容由遇见数据集搜集并总结生成


