MNIST
收藏Papers with Code2024-05-15 收录
下载链接:
https://paperswithcode.com/dataset/mnist
下载链接
链接失效反馈资源简介:
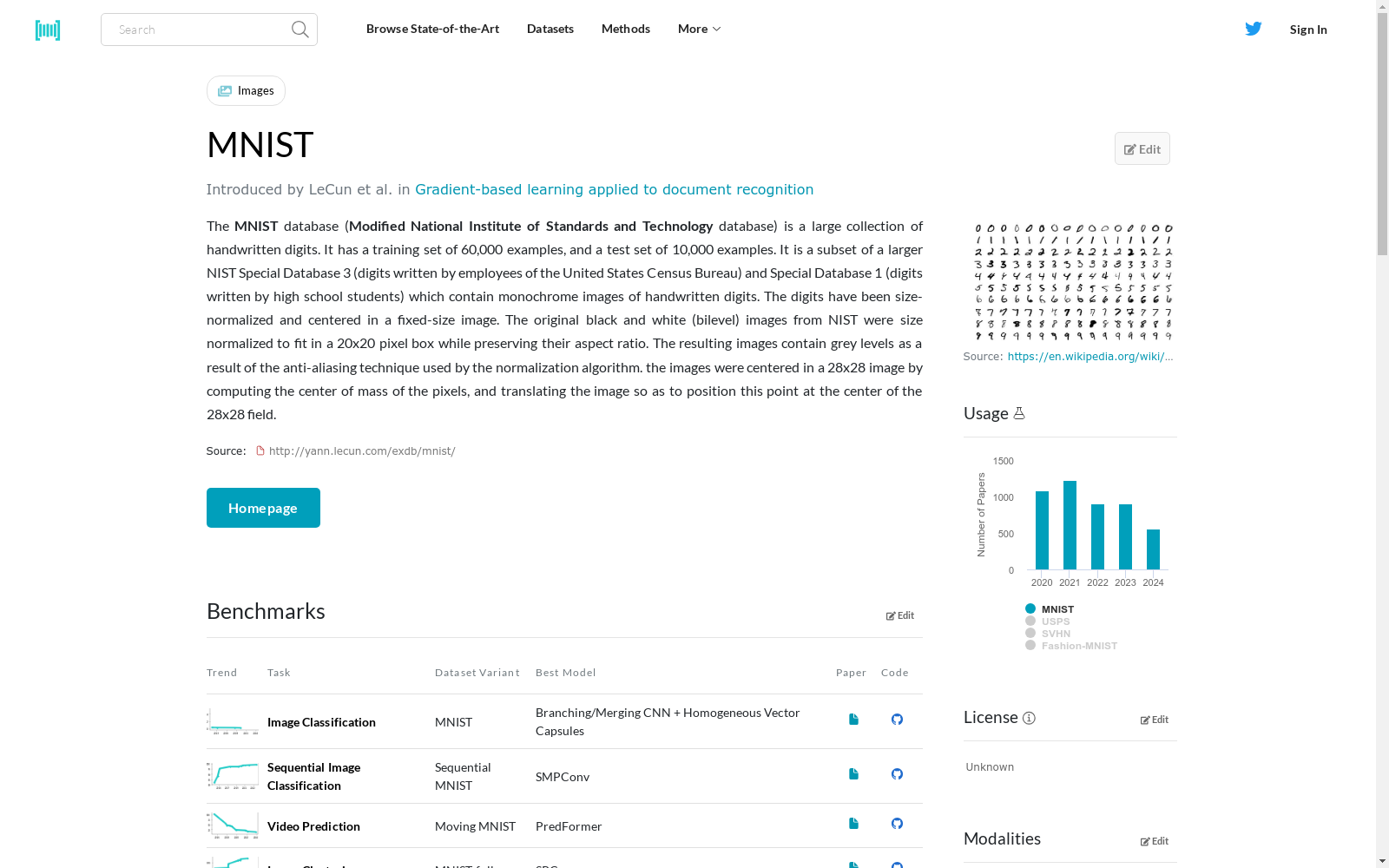
The MNIST database (Modified National Institute of Standards and Technology database) is a large collection of handwritten digits. It has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger NIST Special Database 3 (digits written by employees of the United States Census Bureau) and Special Database 1 (digits written by high school students) which contain monochrome images of handwritten digits. The digits have been size-normalized and centered in a fixed-size image. The original black and white (bilevel) images from NIST were size normalized to fit in a 20x20 pixel box while preserving their aspect ratio. The resulting images contain grey levels as a result of the anti-aliasing technique used by the normalization algorithm. the images were centered in a 28x28 image by computing the center of mass of the pixels, and translating the image so as to position this point at the center of the 28x28 field.
MNIST数据库(Modified National Institute of Standards and Technology database)是一款大型手写数字数据集。其包含60000个样本的训练集与10000个样本的测试集。该数据集是规模更大的NIST特殊数据库3(由美国人口普查局员工书写的数字)与特殊数据库1(由高中生书写的数字)的子集,上述两个数据库均收录手写数字的单色图像。所有手写数字均经过尺寸标准化处理,并居中于固定尺寸的图像框架内:原始NIST提供的黑白(二值)图像经尺寸归一化处理,被适配至20×20像素的矩形框中,同时保留原始宽高比。由于归一化算法采用了抗锯齿技术,最终生成的图像带有灰度层级。研究人员通过计算像素的质心,并将该质心平移至28×28图像区域的中心,以此将图像居中于28×28的画布中。
搜集汇总
数据集介绍
构建方式
MNIST数据集源自美国国家标准与技术研究所(NIST)的手写数字数据库,经过Yann LeCun等研究者精心处理与标准化,构建为适用于机器学习任务的格式。该数据集由60,000张训练图像和10,000张测试图像组成,每张图像均为28x28像素的灰度图像,代表0到9的手写数字。图像数据被归一化为0到1之间的浮点数,标签则采用独热编码形式,确保了数据的高效利用与模型训练的便捷性。
特点
MNIST数据集以其简洁性和广泛适用性著称,成为图像分类领域的基准数据集。其图像尺寸小巧,便于处理,同时数据量适中,既能保证训练效率,又能提供足够的多样性。此外,MNIST数据集的标签准确无误,减少了数据预处理的工作量,使得研究者能够专注于模型设计和优化。尽管数据集相对简单,但其广泛的应用范围和持续的挑战性使其在学术界和工业界均具有重要地位。
使用方法
MNIST数据集常用于初学者入门和算法验证,研究者可通过加载数据集并将其划分为训练集和测试集,进行模型的训练与评估。常见的使用方法包括构建卷积神经网络(CNN)或全连接神经网络(FCN),通过交叉验证调整模型参数,以提高分类准确率。此外,MNIST数据集还可用于探索数据增强技术、模型压缩方法等前沿研究,为更复杂的数据集处理提供基础和参考。
背景与挑战
背景概述
MNIST数据集,全称为Modified National Institute of Standards and Technology数据库,由Yann LeCun、Corinna Cortes和Christopher J.C. Burges于1998年创建。该数据集由手写数字的灰度图像组成,每张图像大小为28x28像素,涵盖0到9的数字类别。MNIST在机器学习领域具有里程碑意义,因其简单且标注良好的特性,成为图像分类任务的基准数据集。它不仅推动了深度学习技术的发展,还为研究人员提供了一个标准化的测试平台,促进了算法性能的比较和改进。
当前挑战
尽管MNIST数据集在图像分类领域具有广泛应用,但其简单性也带来了一些挑战。首先,MNIST图像的低分辨率和单一背景使得其在处理复杂图像任务时表现不佳。其次,由于数据集规模较小,模型容易过拟合,限制了其在实际应用中的泛化能力。此外,MNIST的图像类别较少,无法充分评估模型在多类别分类任务中的性能。因此,研究人员在构建更复杂和多样化的数据集时,需要克服这些挑战,以推动图像识别技术的发展。
发展历史
创建时间与更新
MNIST数据集创建于1998年,由Yann LeCun等人首次发布,旨在为手写数字识别提供一个标准化的基准。该数据集自发布以来,经历了多次更新和扩展,以适应不断发展的机器学习技术需求。
重要里程碑
MNIST数据集的发布标志着计算机视觉领域的一个重要里程碑。它不仅为研究人员提供了一个标准化的测试平台,还极大地推动了深度学习和神经网络的发展。随着时间的推移,MNIST数据集被广泛应用于各种机器学习算法的研究和开发中,成为评估模型性能的基准数据集之一。此外,该数据集的成功应用也激发了更多类似数据集的创建,进一步丰富了计算机视觉领域的研究资源。
当前发展情况
当前,MNIST数据集仍然是机器学习和计算机视觉领域的重要参考资源。尽管现代数据集如ImageNet等在规模和复杂性上超越了MNIST,但MNIST因其简洁性和广泛的应用基础,仍然在教育和基础研究中占据重要地位。它不仅被用于教学和入门级实验,还经常作为新算法和模型的测试基准。MNIST数据集的成功和持续使用,证明了其在推动技术进步和知识传播方面的持久价值。
发展历程
- MNIST数据集首次发表,由Yann LeCun、Corinna Cortes和Christopher J.C. Burges创建,旨在成为手写数字识别的标准基准。
- MNIST数据集在计算机视觉和机器学习领域得到广泛应用,成为评估和比较算法性能的重要工具。
- 随着深度学习的兴起,MNIST数据集被用作训练和测试卷积神经网络(CNN)的基础数据集,进一步巩固了其在学术界和工业界的地位。
- MNIST数据集的变体和扩展版本开始出现,以应对更复杂和多样化的手写数字识别任务,推动了数据集的进一步发展和应用。
常用场景
经典使用场景
在计算机视觉领域,MNIST数据集被广泛用于手写数字识别任务。该数据集由70,000张28x28像素的灰度图像组成,每张图像代表一个手写数字(0-9)。研究人员常利用MNIST数据集来验证和比较不同的机器学习算法,特别是深度学习模型,如卷积神经网络(CNN)。通过这一经典数据集,学者们能够系统地评估模型在图像分类任务中的性能,从而推动算法的发展和优化。
解决学术问题
MNIST数据集在学术研究中解决了手写数字识别这一基础问题,为研究人员提供了一个标准化的基准。通过这一数据集,学者们能够深入探讨图像处理、特征提取和模式识别等关键技术。此外,MNIST数据集还促进了深度学习技术的早期发展,为后续更复杂的图像识别任务奠定了基础。其广泛应用和标准化特性,使得不同研究团队的工作具有可比性,推动了计算机视觉领域的整体进步。
衍生相关工作
基于MNIST数据集,许多经典工作得以展开,如LeNet-5卷积神经网络的提出,该网络首次展示了卷积层在图像识别中的强大能力。此外,MNIST数据集还催生了大量研究,探讨如何通过数据增强、迁移学习和模型压缩等技术提升模型的泛化能力和效率。这些研究不仅深化了对图像识别技术的理解,还为其他领域的数据集和任务提供了宝贵的经验和方法论。
以上内容由遇见数据集搜集并总结生成


