BUT-FIT/OARelatedWork
收藏Hugging Face2026-04-20 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/BUT-FIT/OARelatedWork
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个配置,主要涉及学术论文的元数据和内容信息。特征字段包括论文的ID、标题、摘要、作者、年份、研究领域、引用文献等。数据集还包含论文的层次结构、相关工作、引用和参考文献的详细信息。数据集被分割为训练集、验证集和测试集,适用于自然语言处理任务,如文本分类、信息抽取等。
该数据集包含多个配置,主要涉及学术论文的元数据和内容信息。特征字段包括论文的ID、标题、摘要、作者、年份、研究领域、引用文献等。数据集还包含论文的层次结构、相关工作、引用和参考文献的详细信息。数据集被分割为训练集、验证集和测试集,适用于自然语言处理任务,如文本分类、信息抽取等。
提供机构:
BUT-FIT
原始信息汇总
数据集概述
数据集信息
特征
- id: 数据类型为
uint64 - s2orc_id: 数据类型为
uint64 - mag_id: 数据类型为
uint64 - doi: 数据类型为
string - title: 数据类型为
string - abstract: 包含以下子特征
- title_path: 数据类型为
list的string - text: 数据类型为
string - citations: 包含以下子特征
- index: 数据类型为
uint16 - start: 数据类型为
uint32 - end: 数据类型为
uint32
- index: 数据类型为
- references: 包含以下子特征
- index: 数据类型为
uint16 - start: 数据类型为
uint32 - end: 数据类型为
uint32
- index: 数据类型为
- title_path: 数据类型为
- related_work: 数据类型为
string - hierarchy: 数据类型为
string - authors: 数据类型为
list的string - year: 数据类型为
uint16 - fields_of_study: 数据类型为
list的string - referenced: 包含以下子特征
- id: 数据类型为
uint64 - s2orc_id: 数据类型为
uint64 - mag_id: 数据类型为
uint64 - doi: 数据类型为
string - title: 数据类型为
string - hierarchy: 数据类型为
string - authors: 数据类型为
list的string - year: 数据类型为
uint16 - fields_of_study: 数据类型为
list的string - citations: 数据类型为
list的uint64 - bibliography: 包含以下子特征
- id: 数据类型为
uint64 - title: 数据类型为
string - year: 数据类型为
uint16 - authors: 数据类型为
list的string
- id: 数据类型为
- non_plaintext_content: 包含以下子特征
- type: 数据类型为
string - description: 数据类型为
string
- type: 数据类型为
- id: 数据类型为
- bibliography: 包含以下子特征
- id: 数据类型为
uint64 - title: 数据类型为
string - year: 数据类型为
uint16 - authors: 数据类型为
list的string
- id: 数据类型为
- non_plaintext_content: 包含以下子特征
- type: 数据类型为
string - description: 数据类型为
string
- type: 数据类型为
数据分割
- train: 字节数为 39235598318,样本数为 91445
- validation: 字节数为 581643389,样本数为 1127
- test: 字节数为 965353630,样本数为 1878
数据大小
- 下载大小: 15174246190 字节
- 数据集大小: 40782595337 字节
配置
- default: 包含以下数据文件
- train: 路径为
data/train-* - validation: 路径为
data/validation-* - test: 路径为
data/test-*
- train: 路径为
数据集描述
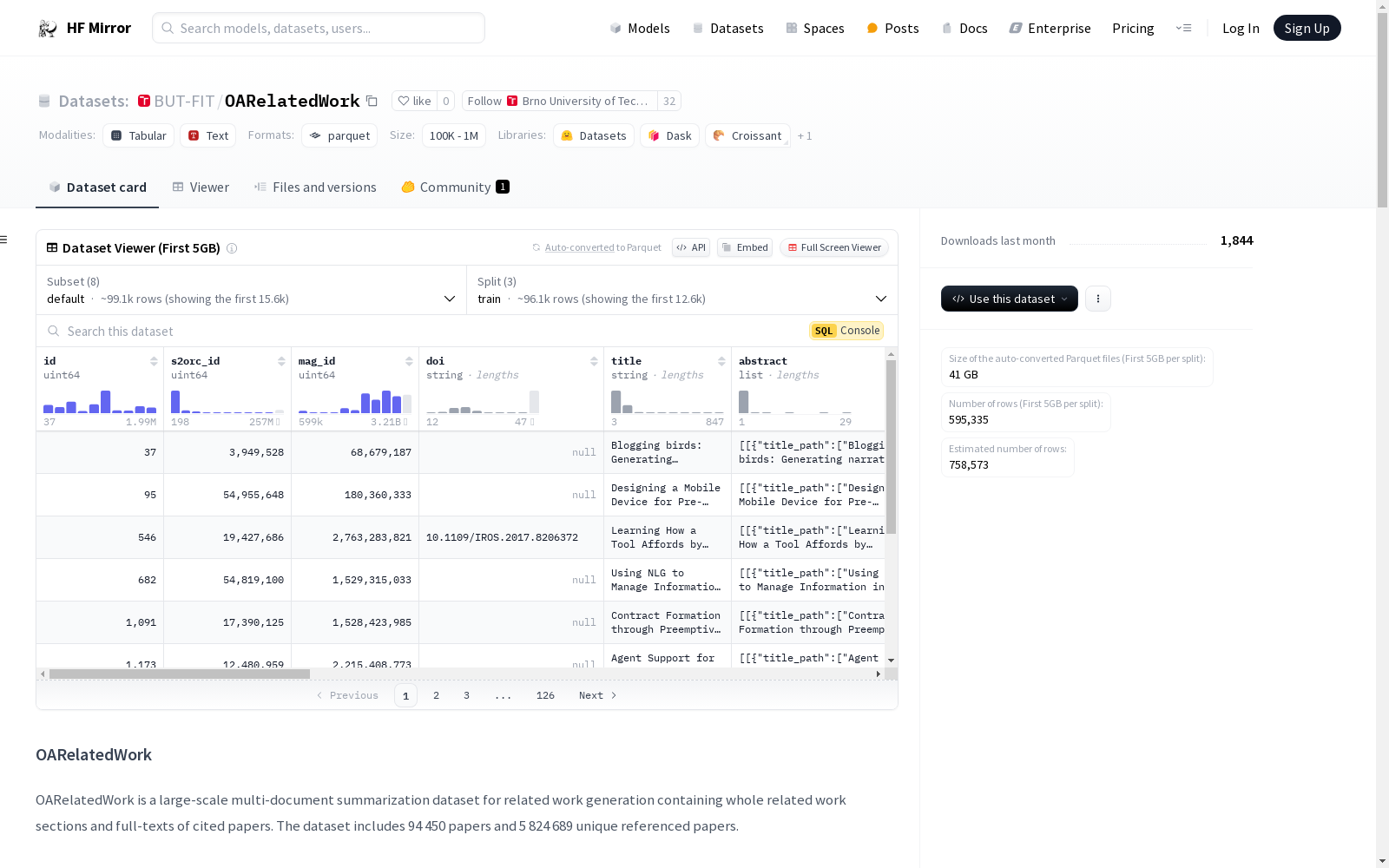
OARelatedWork 是一个大规模的多文档摘要数据集,用于生成相关工作部分,包含整个相关工作部分和被引用论文的全文。数据集包括 94,450 篇论文和 5,824,689 篇独特的被引用论文。
数据分割
| 分割 | 样本数 |
|---|---|
| Train | 91,445 |
| Validation | 1,127 |
| Test | 1,878 |
字段
- id: 数据集中的 ID
- s2orc_id: SemanticScholar ID
- mag_id: Microsoft Academic Graph ID
- DOI: 可能与处理文档的版本不同
- title: 出版物标题
- abstract: 摘要中的段落列表,每个段落是句子的列表
- related_work: 目标相关工作部分,格式根据使用的配置不同而不同
- hierarchy: 文档正文,但不包括摘要和相关工作部分,格式根据使用的配置不同而不同
- authors: 出版物的作者
- year: 出版年份
- fields_of_study: 研究领域列表
- referenced: 被引用文档列表,每个被引用文档具有相同的字段,但不包括摘要、相关工作和被引用字段。所有引用文档的摘要部分作为层次结构中的第一个部分
- bibliography: 文档参考文献
- non_plaintext_content: 表格和图表
结构
数据集提供了多种配置,以简化数据集的使用。由于在发布数据集时无法使用层次结构,因此我们使用了一些变通方法,例如展平层次结构或使用 JSON 表示层次结构。
我们将文档内容分为章节、子章节、段落和句子。并非所有文档都有全文和子章节。
展平的层次结构
层次结构在章节级别上展平,意味着它是一个(子)章节列表。每个(子)章节由树路径上的标题列表和给定(子)章节中的段落列表表示。每个段落表示为句子的列表。每个句子还包含元数据,如引用跨度。
配置
- oa_related_work: 使用 JSON 格式表示层次结构
- abstracts: 仅提供被引用论文的摘要,目标论文的层次结构被展平
- flattened_sections: 层次结构被展平,参见展平的层次结构部分
- greedy oracle based configurations: 这些配置使用贪婪预言机提供过滤后的内容。由于贪婪预言机是一个作弊基线,请谨慎使用。
- greedy_oracle_sentences: 每个被引用文档由贪婪抽取预言机摘要中的句子表示,使用与 flattened_sections 相同的格式
- greedy_oracle_paragraphs: 每个被引用文档由包含贪婪抽取预言机摘要中句子的段落表示,使用与 flattened_sections 相同的格式
- greedy_oracle_per_input_doc_sentences: 每个被引用文档由在每个文档上分别进行的贪婪抽取预言机摘要中的句子表示,使用与 flattened_sections 相同的格式
- greedy_oracle_per_input_doc_paragraphs: 每个被引用文档由包含在每个文档上分别进行的贪婪抽取预言机摘要中句子的段落表示,使用与 flattened_sections 相同的格式
- abstracts_with_greedy_oracle_target_sentences: 与 abstracts 相同,但目标是目标文档的贪婪预言机摘要。目标文档是为其生成相关工作的文档
搜集汇总
数据集介绍
构建方式
BUT-FIT/OARelatedWork数据集的构建基于学术论文的摘要、相关工作、层次结构、作者信息、年份、研究领域以及引用和参考文献等详细信息。数据集通过整合多个学术资源,如S2ORC和MAG,确保了数据的全面性和多样性。每个条目不仅包含论文的基本信息,还详细记录了其引用和被引用的关系,以及相关的段落和层次结构,从而为研究者提供了丰富的学术背景信息。
特点
该数据集的显著特点在于其结构化的数据组织方式,不仅涵盖了论文的标题、摘要等基本信息,还详细记录了论文的引用网络、层次结构以及相关工作的段落信息。此外,数据集提供了多种配置选项,如‘abstracts’、‘abstracts_with_greedy_oracle_target_sentences’等,以满足不同研究需求。这种多层次、多维度的数据结构使得该数据集在学术研究中具有广泛的应用潜力。
使用方法
使用BUT-FIT/OARelatedWork数据集时,研究者可以根据具体需求选择不同的配置,如‘abstracts’配置适用于仅需要摘要信息的研究,而‘abstracts_with_greedy_oracle_target_sentences’配置则适合需要更详细引用信息的研究。数据集提供了训练、验证和测试三个数据集划分,便于模型训练和评估。通过HuggingFace的datasets库,用户可以轻松加载和处理数据,进行文本分析、引用网络研究等多种学术任务。
背景与挑战
背景概述
BUT-FIT/OARelatedWork数据集由BUT-FIT(布尔诺理工大学信息与通信技术系)的研究团队创建,专注于学术论文的摘要及其相关工作部分的内容分析。该数据集的核心研究问题在于如何有效提取和分析学术论文中的相关工作部分,以支持学术研究的知识图谱构建和文献综述的自动化生成。通过整合来自不同学术资源的数据,如S2ORC和MAG,该数据集提供了丰富的元数据和结构化信息,包括论文的标题、摘要、引用、参考文献等,为学术领域的研究提供了宝贵的资源。
当前挑战
该数据集在构建过程中面临多重挑战。首先,如何从海量的学术论文中准确提取相关工作部分的内容,确保信息的完整性和准确性,是一个复杂的技术难题。其次,数据集的多样性和复杂性要求在处理过程中保持高度的结构化,以便于后续的分析和应用。此外,数据集的规模庞大,涉及多个领域的学术论文,如何在不同领域之间保持一致性和可比性也是一个重要的挑战。最后,数据集的更新和维护需要持续的资源投入,以确保其时效性和可靠性。
常用场景
经典使用场景
BUT-FIT/OARelatedWork数据集在学术研究中广泛应用于文献综述的自动化生成与分析。通过该数据集,研究者可以提取学术论文的摘要、相关工作部分以及引用信息,进而构建知识图谱或进行文献间的关联性分析。其经典使用场景包括自动生成文献综述、识别研究领域的关键文献以及预测未来研究趋势。
解决学术问题
该数据集解决了学术研究中常见的文献综述生成效率低下、文献关联性分析复杂等问题。通过自动化处理大量文献数据,研究者能够快速获取相关领域的研究进展,减少人工筛选文献的时间成本。此外,数据集的引用信息和相关工作部分为研究者提供了深入分析文献间关系的基础,有助于揭示学术领域的知识结构和发展脉络。
衍生相关工作
基于BUT-FIT/OARelatedWork数据集,研究者开发了多种衍生工具和方法。例如,有学者利用该数据集构建了学术知识图谱,用于可视化学术领域的研究脉络。此外,还有研究团队基于数据集的引用信息,提出了新的文献推荐算法,显著提升了文献推荐的准确性和相关性。这些衍生工作进一步拓展了数据集的应用范围,推动了学术研究的智能化发展。
以上内容由遇见数据集搜集并总结生成


