european-gender-drama-jina-embeddings
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/awlassche/european-gender-drama-jina-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
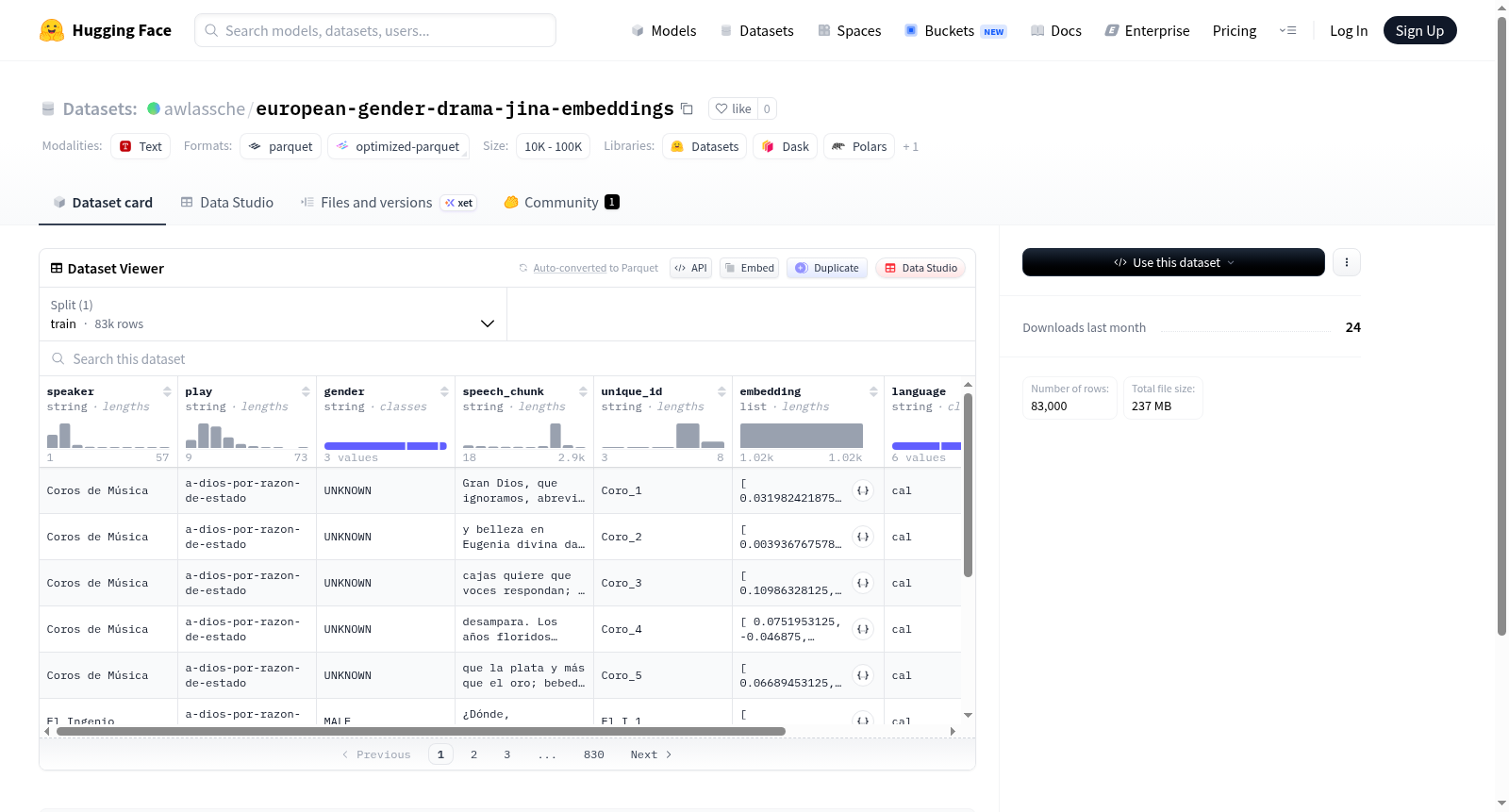
该数据集包含83,000个训练样本,每个样本代表一个戏剧或类似表演中的语音片段。每个样本具有结构化信息,包括说话者身份(speaker)、所属戏剧或剧目名称(play)、说话者性别(gender)、语音片段的文本内容(speech_chunk)、唯一标识符(unique_id)、文本的向量化嵌入表示(embedding,为浮点数列表)、语言信息(language)以及年份(year,为整数)。数据集总大小约为842MB,以训练集形式组织,适用于戏剧文本分析、说话者属性研究、自然语言处理嵌入应用或跨年份/语言的语言特征分析相关任务。
This dataset contains 83,000 training samples, each representing a speech segment from a drama or similar performance. Each sample includes structured information such as speaker identity (speaker), play or performance name (play), speaker gender (gender), text content of the speech chunk (speech_chunk), unique identifier (unique_id), vectorized embedding representation of the text (embedding, as a list of floating-point numbers), language information (language), and year (year, as an integer). The total dataset size is approximately 842MB, organized as a training set, and it is suitable for tasks related to drama text analysis, speaker attribute research, natural language processing embedding applications, or cross-year/language linguistic feature analysis.
创建时间:
2026-05-05
搜集汇总
数据集介绍
构建方式
在戏剧文学与计算语言学的交叉领域中,该数据集以欧洲戏剧文本为基底,精心提取了说话者、戏剧名称、性别、语段内容及唯一标识符等结构化字段。通过整合多语言剧本资源,依据年份与语言信息进行系统分类,并利用先进的嵌入技术为每个语段生成高维向量表示,从而构建起一个包含八万三千条训练样本的丰富语料库。
特点
该数据集的核心特色在于其多维度的标注体系,不仅涵盖了说话者的性别属性与戏剧年份,还提供了语言种类与嵌入向量。分层结构使得研究者能够灵活筛选特定性别、语言或时代的语段,而嵌入向量的加入则极大便利了语义相似度计算与上下文建模,为性别语言差异的量化分析提供了坚实的数据基础。
使用方法
使用时,可通过HuggingFace Datasets库直接加载默认配置的训练分割,获取包含说话者、性别、语段及嵌入向量等字段的完整样本。适用于训练性别识别模型、分析戏剧中性别角色语言模式,或作为预训练嵌入的评估基准。支持按语言、年份或性别字段进行过滤,便于开展针对性研究。
背景与挑战
背景概述
该数据集名为european-gender-drama-jina-embeddings,由研究机构或团队创建于近年,聚焦于欧洲戏剧文本中的性别表征分析。通过整合多语种戏剧语料,提取说话者角色、剧本、性别、语言及年代等信息,并利用嵌入技术将文本转化为向量表示,旨在探索语言使用与性别身份之间的深层关联。数据集收录约8.3万个训练样本,涵盖多部欧洲戏剧作品,为计算语言学和数字人文领域提供了结构化资源,助力性别角色在历史戏剧中的分布与演变研究。其对理解性别刻板印象的文本化再现、推动社会语言学与文学分析的计算方法具有重要影响,已成为性别语言研究的基准数据集之一。
当前挑战
该数据集面临的挑战涵盖领域问题与构建过程两方面。领域问题方面,欧洲戏剧文本中的性别表征分析需突破传统定性研究的局限,即如何从大规模多语种、跨时代的文本中量化性别差异和动态演变,而数据集中语种多样性(如英语、法语、德语等)及年代跨度(需覆盖数百年)更增加了建模复杂性。构建过程中,挑战在于戏剧文本的清洗与对齐:原始语料可能存在说话者标注歧义、角色性别模糊(如中性或未指定性别)以及不同版本戏剧的文本变异,需手动或半自动校正。此外,确保嵌入表示捕捉到文本中的语义和语用维度,同时避免引入语言或历史偏见,对数据质量和后续分析的有效性构成严峻考验。
常用场景
经典使用场景
该数据集汇聚了欧洲戏剧文本中角色台词与说话者的性别、剧目、语言及年份等结构化信息,并预计算了稠密语义嵌入向量。其经典应用在于构建基于语料库的戏剧性别话语分析系统,研究人员可借助嵌入向量进行角色间的语义相似性度量与聚类,揭示不同性别角色在戏剧叙事中的话语模式差异、主题倾向演变及跨语言共性现象。
实际应用
在实际应用中,该数据集可赋能戏剧史研究平台,辅助学者自动标注角色性别话语风格。同时,它亦可用于开发面向文学教育的智能检索工具,支持按性别、剧目或年代查询特定语境下的台词样本。此外,其嵌入特征可作为训练下游模型的基础,服务于戏剧角色关系预测与剧本自动分类。
衍生相关工作
该数据集衍生了多个经典工作,包括基于性别话语嵌入的戏剧角色社交网络分析研究、跨世纪欧洲戏剧性别话语演进的时间序列建模,以及将多语言戏剧嵌入作为预训练信号,迁移至低资源戏剧文本的情感分析任务。这些工作共同展现了该数据集在计算戏剧学方法论创新中的基石作用。
以上内容由遇见数据集搜集并总结生成


