有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
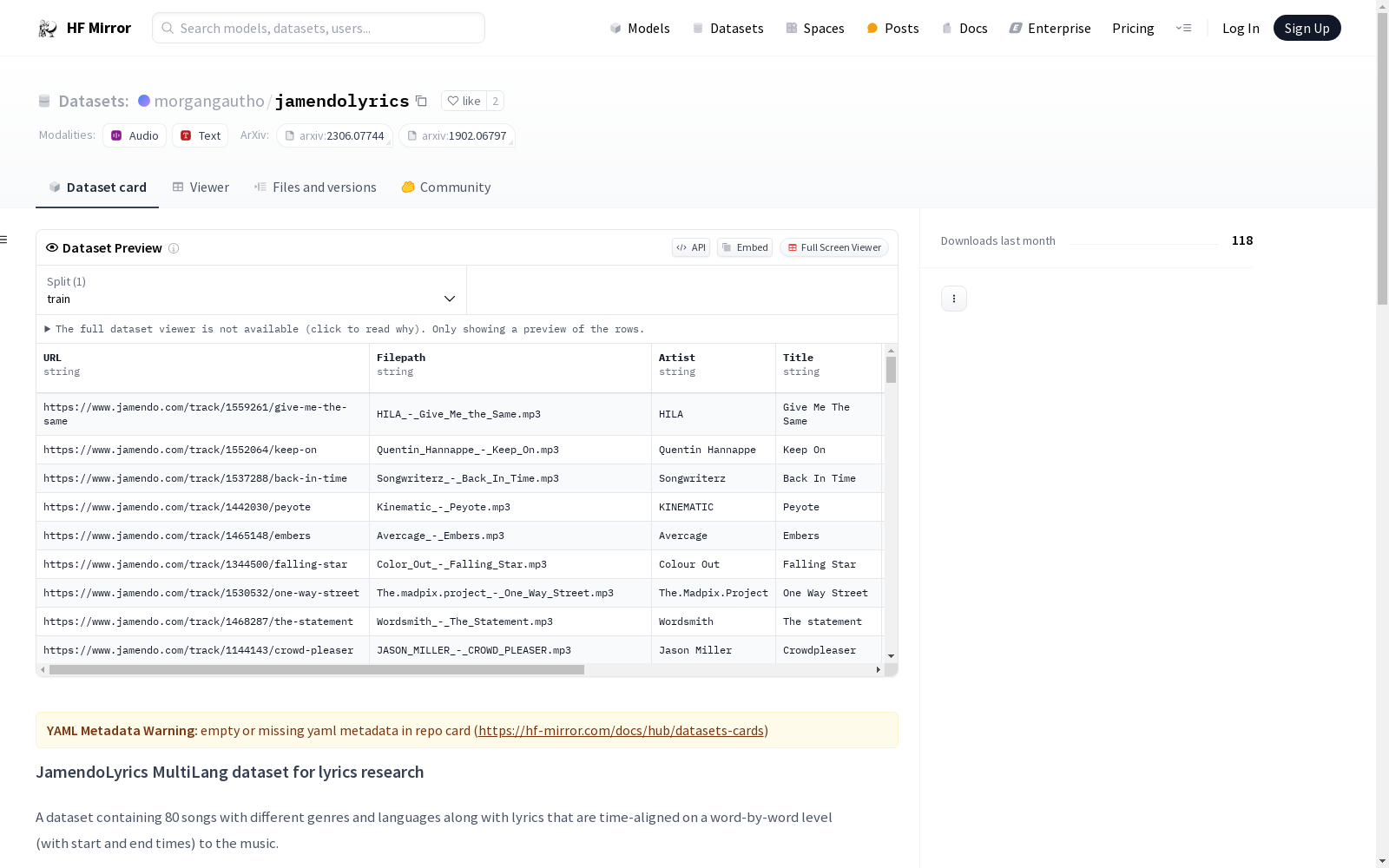
该数据集包含80首不同流派和语言的歌曲及其歌词,歌词以单词为单位进行时间对齐(包含开始和结束时间)。
所有歌曲的元数据列在JamendoLyrics.csv文件中。元数据包括:
LyricOverlap:歌词是否重叠Polyphonic:是否有多个歌手以不同旋律唱同一歌词NonLexical:是否有非词汇演唱(如scatting)lyrics子文件夹中提供每首歌曲的歌词文件SONG_NAME.txt(已规范化,特殊字符和不支持的字符已移除)SONG_NAME.words.txt包含所有单词,按行分隔,忽略原始歌词的段落结构,用于单词级时间戳注释annotations/words子文件夹中,并指示单词是否代表一行的结束annotations/lines子文件夹中,以CSV文件形式表示每行歌词的开始和结束时间如果修改单词级时间戳,需要运行generate_lines.py以相应更新annotations/lines中的行级时间戳文件。
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
UAVDT
UAVDT是一个用于目标检测任务的数据集。
github 收录
THUCNews
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。本次比赛数据集在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。提供训练数据共832471条。
github 收录
PlantVillage
在这个数据集中,39 种不同类别的植物叶子和背景图像可用。包含 61,486 张图像的数据集。我们使用了六种不同的增强技术来增加数据集的大小。这些技术是图像翻转、伽玛校正、噪声注入、PCA 颜色增强、旋转和缩放。
OpenDataLab 收录
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录