morgangautho/jamendolyrics
收藏Hugging Face2023-08-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/morgangautho/jamendolyrics
下载链接
链接失效反馈官方服务:
资源简介:
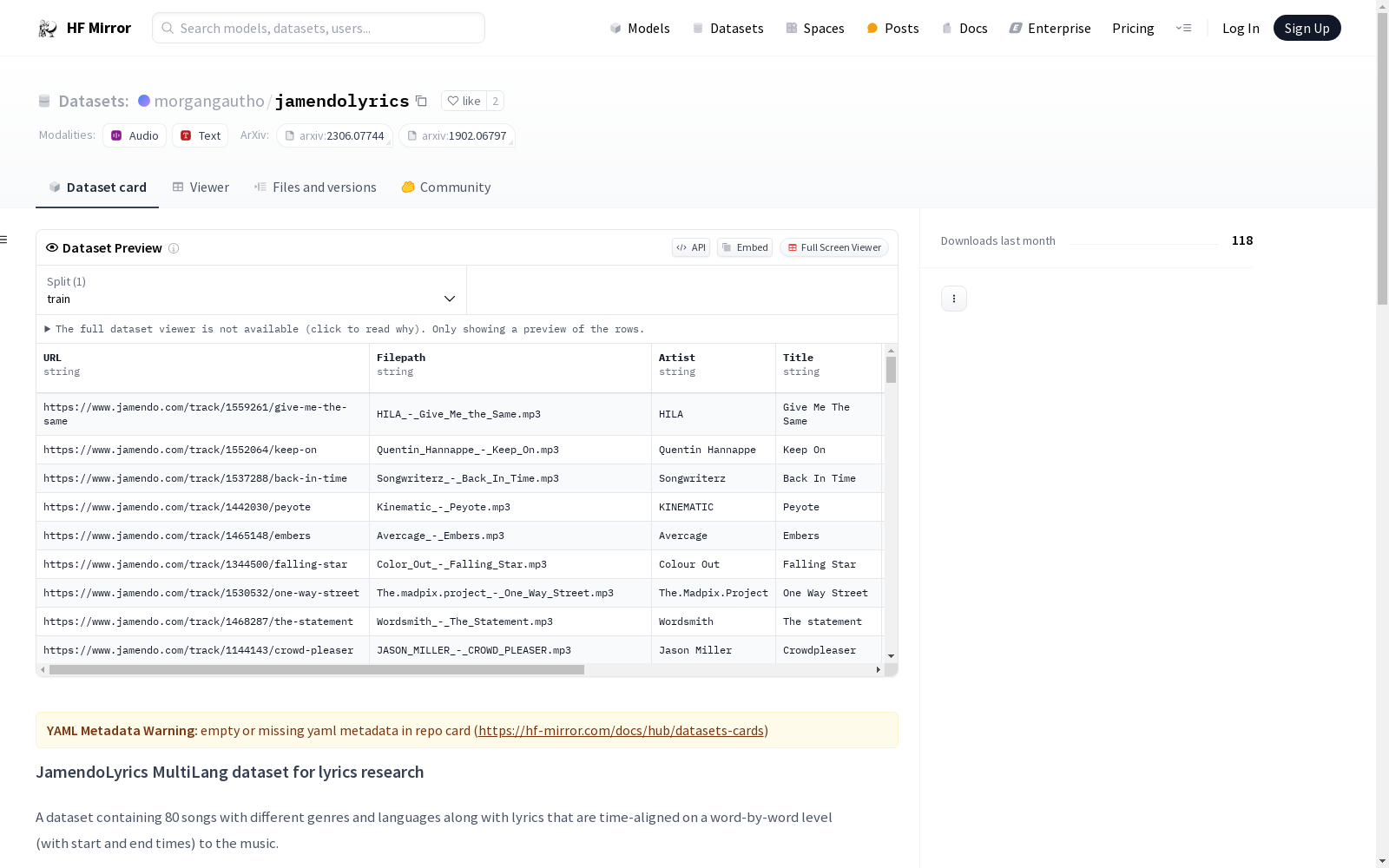
JamendoLyrics MultiLang数据集包含80首不同流派和语言的歌曲,歌词与音乐在逐字级别上进行了时间对齐(包含开始和结束时间)。数据集还包括元数据CSV文件、歌词文件以及时间对齐的歌词注释。元数据CSV文件中列出了所有歌曲及其元数据,歌词文件提供了每首歌曲的歌词,时间对齐的歌词注释包括逐字和逐行的时间戳。此外,文件还提到了如何安装和使用数据集,以及如何修改和更新时间戳注释。数据集是原始JamendoLyrics数据集的扩展版本,原始数据集仅包含20首英文歌曲,现已弃用。
The JamendoLyrics MultiLang dataset contains 80 songs with different genres and languages along with lyrics that are time-aligned on a word-by-word level (with start and end times) to the music. The datasets metadata CSV file lists all songs along with their metadata, including whether the lyrics overlap, whether there are multiple melodies, and whether there is non-lexical singing. Lyrics files provide the lyrics text for each song, as well as word-level annotations. Time-aligned lyrics annotations include word-level and line-level start and end times. The dataset also includes a script to generate line-level timestamp files and encourages users to submit pull requests if they find timestamp annotation errors.
提供机构:
morgangautho
原始信息汇总
JamendoLyrics MultiLang 歌词研究数据集
数据集概述
该数据集包含80首不同流派和语言的歌曲及其歌词,歌词以单词为单位进行时间对齐(包含开始和结束时间)。
元数据CSV
所有歌曲的元数据列在JamendoLyrics.csv文件中。元数据包括:
LyricOverlap:歌词是否重叠Polyphonic:是否有多个歌手以不同旋律唱同一歌词NonLexical:是否有非词汇演唱(如scatting)
歌词文件
lyrics子文件夹中提供每首歌曲的歌词文件SONG_NAME.txt(已规范化,特殊字符和不支持的字符已移除)SONG_NAME.words.txt包含所有单词,按行分隔,忽略原始歌词的段落结构,用于单词级时间戳注释
时间对齐的歌词注释
- 单词级时间戳注释存储在
annotations/words子文件夹中,并指示单词是否代表一行的结束 - 行级歌词注释存储在
annotations/lines子文件夹中,以CSV文件形式表示每行歌词的开始和结束时间
修改单词级时间戳
如果修改单词级时间戳,需要运行generate_lines.py以相应更新annotations/lines中的行级时间戳文件。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于对80首不同风格和语言的歌曲进行精心挑选,并通过逐字逐句的时间对齐技术,将歌词与音乐精确匹配。具体而言,歌词的时间戳标注分为逐字和逐行两种形式,分别存储在'annotations/words'和'annotations/lines'子文件夹中。逐字时间戳标注包括每个词的开始和结束时间,并标明是否为行尾。逐行时间戳则以CSV文件形式存储,每行包含开始时间、结束时间和对应的歌词行。此外,数据集还包含详细的元数据,如歌词是否重叠、是否为多声部演唱以及是否包含非词汇演唱等。
使用方法
使用该数据集时,用户可以直接从GitHub仓库克隆数据,无需额外安装。数据集的元数据存储在'JamendoLyrics.csv'文件中,用户可以通过该文件构建文件路径以访问每首歌曲的音频和歌词数据。歌词文件分别存储在'lyrics'子文件夹中,包括标准化后的歌词文本和逐字分隔的歌词文本。时间对齐的歌词标注则分别存储在'annotations/words'和'annotations/lines'子文件夹中,用户可以根据需要选择逐字或逐行的标注进行模型训练或评估。
背景与挑战
背景概述
JamendoLyrics数据集是一个专注于歌词研究的多语言数据集,由Simon Durand、Daniel Stoller和Sebastian Ewert等研究人员于2023年首次提出,并在ICASSP 2023会议上发表。该数据集包含80首不同风格和语言的歌曲,其歌词与音乐在单词级别上进行了时间对齐,提供了详细的开始和结束时间。这一数据集的创建旨在解决多语言音频与歌词对齐的核心研究问题,对音乐信息检索和语音处理领域具有重要影响。此外,该数据集是基于2019年提出的原始JamendoLyrics数据集的扩展,原始数据集仅包含20首英语歌曲,现已弃用。
当前挑战
JamendoLyrics数据集在构建过程中面临多项挑战。首先,实现多语言歌词与音频的精确对齐是一项技术难题,尤其是在处理不同语言和音乐风格时。其次,数据集的元数据中包含的“LyricOverlap”、“Polyphonic”和“NonLexical”等特性增加了数据处理的复杂性,需要精确的标注和验证。此外,时间戳的准确性对研究结果至关重要,任何错误都可能影响模型的训练和评估。最后,数据集的扩展和维护也是一个持续的挑战,需要不断更新和修正以确保其质量和适用性。
常用场景
经典使用场景
morgangautho/jamendolyrics数据集以其多语言和多风格的歌词与音乐时间对齐特性,成为歌词研究领域的经典工具。该数据集不仅提供了80首歌曲的歌词,还通过逐字级别的时间戳标注,使得研究者能够精确分析歌词与音乐的同步关系。这种精细的时间对齐方式,特别适用于开发和评估音频与歌词对齐模型,尤其是在多语言环境下,为跨语言歌词研究提供了宝贵的资源。
解决学术问题
该数据集解决了歌词与音乐对齐研究中的关键学术问题,尤其是在多语言和多风格音乐中的应用。通过提供逐字和逐行的时间戳标注,它为研究者提供了一个标准化的数据集,用于训练和测试音频与歌词对齐算法。这不仅推动了歌词研究的发展,还为音乐信息检索(MIR)领域提供了新的研究方向,特别是在处理非标准歌词(如非词汇歌唱)和多声部音乐时,展现了其独特的价值。
实际应用
在实际应用中,morgangautho/jamendolyrics数据集被广泛用于开发歌词同步软件和音乐信息检索系统。例如,它可以用于构建自动卡拉OK系统,通过精确的歌词时间戳实现歌词与音乐的实时同步。此外,该数据集还可用于音乐教育软件,帮助学习者更好地理解歌词与音乐的结构关系。在娱乐产业中,它也为歌词翻译和本地化提供了技术支持,增强了跨文化音乐体验的准确性和流畅性。
数据集最近研究
最新研究方向
在音乐与语言交叉领域,morgangautho/jamendolyrics数据集因其多语言歌词与音频的时间对齐特性,成为研究歌词与音乐同步的前沿工具。该数据集不仅涵盖多种语言和音乐风格,还提供了逐字和逐行的歌词时间戳,为音频与歌词的相似性对齐研究提供了丰富的资源。近期研究主要集中在多语言环境下的歌词与音频对齐算法优化,以及如何利用这些对齐数据提升音乐信息检索和歌词生成模型的性能。此外,该数据集的开放性也促进了社区对歌词时间戳标注错误的研究与修正,进一步推动了该领域的标准化和精确化发展。
以上内容由遇见数据集搜集并总结生成


