SuperCLUE-Agent
收藏github2023-10-01 更新2025-02-08 收录
下载链接:
https://github.com/CLUEbenchmark/SuperCLUE-Agent
下载链接
链接失效反馈资源简介:
SuperCLUE-Agent数据集填补了在中文任务和场景中评估大型语言模型(LLMs)代理能力的空白。该评估涵盖了10项任务,分布在三个核心能力领域。任务规划能力包括任务分解、自我反思和逐步推理(CoT)任务;工具使用能力涵盖API调用、API检索、API规划以及通用工具使用任务;长期和短期记忆能力则包括少样本学习、长期对话以及多文档问答等任务。
The SuperCLUE-Agent dataset fills a gap in evaluating the capabilities of Large Language Model (LLMs) agents in Chinese tasks and scenarios. The evaluation covers 10 tasks distributed across three core competence domains. The task planning ability includes tasks such as task decomposition, self-reflection, and step-by-step reasoning (CoT); the tool usage ability encompasses API calls, API retrieval, API planning, and general tool usage tasks; while the long-term and short-term memory abilities include tasks such as few-shot learning, long-term dialogue, and multi-document question answering.
提供机构:
CLUEbenchmark
创建时间:
2023-10-01
原始信息汇总
SuperCLUE-Agent 数据集概述
数据集简介
- 名称: SuperCLUE-Agent
- 类型: Agent智能体中文原生任务能力测评基准
- 更新日期: 2023-10-24
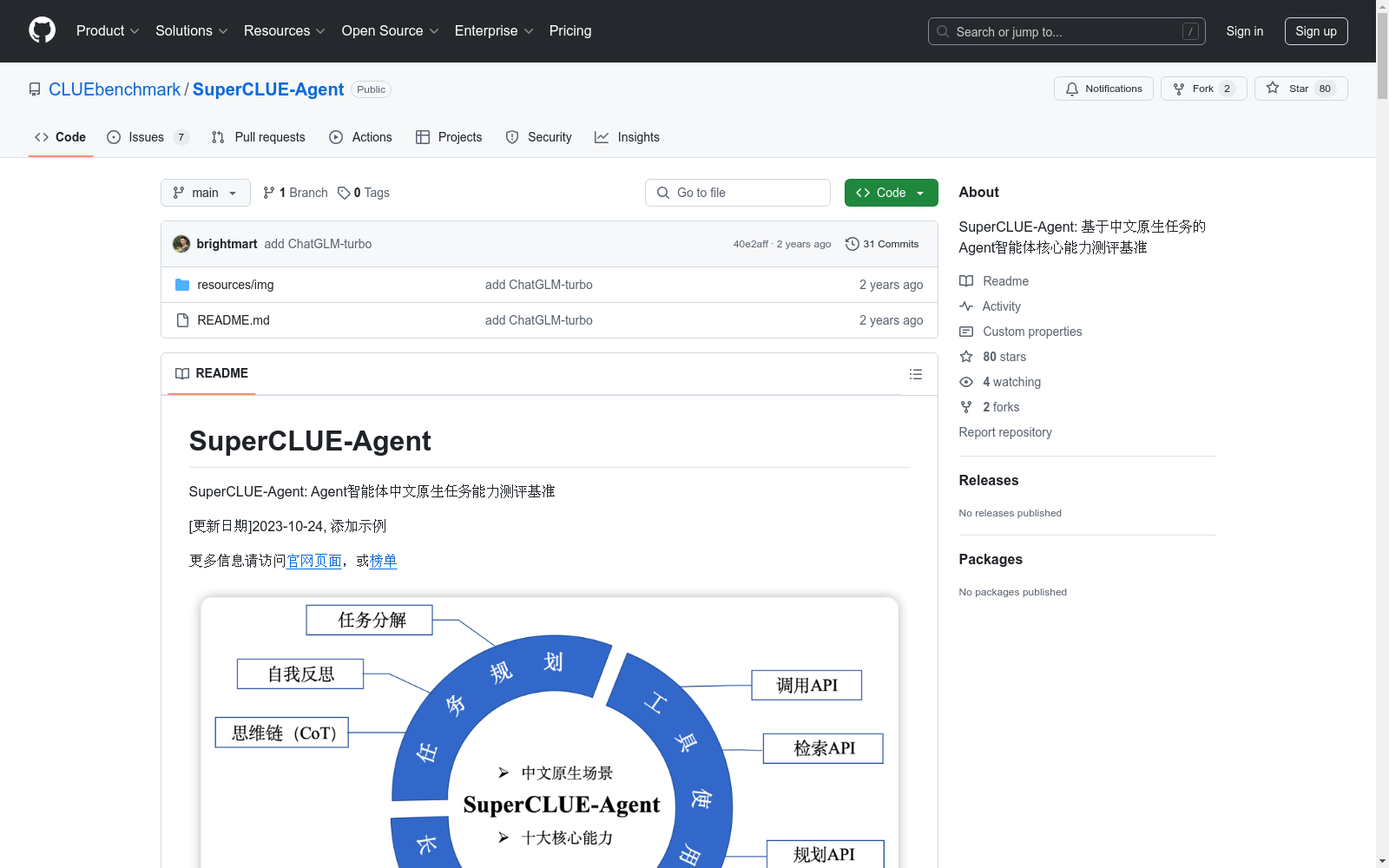
主要功能
- 三大能力测评:
- 工具使用
- 任务规划
- 长短期记忆
- 十大基础任务测评:
- 任务分解
- 自我反思
- 思维链
- 调用API
- 检索API
- 规划API
- 通用工具使用
- 多文档QA
- 长程对话
- 示例学习
排行榜
三大能力排行榜
| 序号 | 模型 | 机构 | 工具使用 | 任务规划 | 长短期记忆 |
|---|---|---|---|---|---|
| 1 | GPT4 | OpenAI | 90.23 | 81.88 | 66.67 |
| 2 | ChatGLM3-Turbo | 清华&智谱AI | 73.87 | 68.37 | 77.03 |
| 3 | Claude2-100K | Anthropic | 65.08 | 52.04 | 73.97 |
十大基础任务排行榜
| 模型 | 总分 | 任务分解 | 自我反思 | 思维链 | 调用API | 检索API | 规划API | 通用工具使用 | 多文档QA | 长程对话 | 示例学习 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT4 | 80.56 | 76.15 | 94.69 | 76.35 | 87.70 | 90.66 | 82.22 | 100.00 | 67.97 | 60.20 | 73.79 |
| ChatGLM3-Turbo | 73.09 | 100.00 | 52.13 | 51.00 | 49.00 | 93.88 | 72.00 | 81.00 | 90.62 | 63.00 | 78.00 |
| Claude2-100K | 63.82 | 42.77 | 64.04 | 51.73 | 52.36 | 74.52 | 73.14 | 61.42 | 59.55 | 68.60 | 94.53 |
示例展示
工具使用
- 调用API: 考察AI Agent根据API描述精确调用API并正确响应的能力。
- 检索API: 考察AI Agent选择解决用户需求的API并通过文档学习使用的能力。
- 规划API: 考察AI Agent在复杂请求中进行多次API调用的能力。
- 通用工具使用: 考察大模型使用通用工具的能力。
任务规划
- 任务分解: 评估AI Agent将大型任务分解为较小、可管理子目标的能力。
- 自我反思: 评估AI Agent对过去行为进行自我批评和反思的能力。
- 思维链(CoT): 考察AI Agent通过逐步思考解决问题的能力。
长短期记忆
- 示例学习(In-context Learning): 考察AI Agent通过提示工程解决新任务的能力。
- 长程对话: 考察AI Agent在长对话中检索和切换主题的能力。
- 多文档问答: 考察AI Agent在多个文档中提取并组合答案的能力。
搜集汇总
数据集介绍
构建方式
SuperCLUE-Agent数据集的构建基于对中文原生任务能力的深度测评需求,旨在评估智能体在工具使用、任务规划和长短期记忆等方面的表现。数据集的构建过程涵盖了多个维度的任务设计,包括调用API、检索API、规划API等工具使用任务,以及任务分解、自我反思、思维链等任务规划能力。此外,数据集还通过长程对话、多文档问答等任务,评估智能体在复杂场景下的表现。所有任务均经过精心设计,以确保测评的全面性和科学性。
特点
SuperCLUE-Agent数据集的特点在于其多维度的测评框架,涵盖了工具使用、任务规划和长短期记忆三大核心能力。数据集不仅提供了丰富的任务类型,如API调用、任务分解、思维链推理等,还通过长程对话和多文档问答等复杂场景,全面评估智能体的综合能力。此外,数据集还支持对多种中文大模型的测评,提供了详细的排行榜和性能对比,为研究者和开发者提供了宝贵的参考依据。
使用方法
使用SuperCLUE-Agent数据集时,用户可以通过访问官方页面或GitHub仓库获取数据集和相关资源。数据集提供了详细的示例和任务说明,用户可以根据需求选择特定的任务进行测评。测评过程中,用户可以通过调用API、任务分解、思维链推理等任务,评估智能体的表现。数据集还提供了排行榜功能,用户可以将测评结果与其他模型进行对比,从而更好地理解模型的优势和不足。此外,用户还可以通过讨论交流群组,与其他研究者和开发者分享经验和见解。
背景与挑战
背景概述
SuperCLUE-Agent是由CLUEbenchmark团队于2023年推出的一个专注于中文智能体任务能力测评的基准数据集。该数据集旨在评估智能体在工具使用、任务规划和长短期记忆等方面的能力,涵盖了从API调用到复杂任务分解的多种场景。通过引入多个知名大模型如GPT-4、ChatGLM3-Turbo等,SuperCLUE-Agent为中文自然语言处理领域提供了一个全面的评估框架。该数据集的推出不仅填补了中文智能体测评的空白,还为相关研究提供了重要的参考依据,推动了中文智能体技术的发展。
当前挑战
SuperCLUE-Agent面临的挑战主要体现在两个方面。首先,在领域问题方面,智能体在处理复杂任务时,如何有效地进行任务分解、自我反思以及思维链推理仍是一个难题。尽管现有模型在工具使用和API调用上表现较好,但在长程对话和多文档问答等需要长期记忆和复杂推理的任务上,性能仍有较大提升空间。其次,在数据集构建过程中,如何设计合理的测评任务以全面覆盖智能体的能力,同时确保任务的多样性和难度平衡,也是一个技术难点。此外,中文语境下的语义理解和上下文关联性也为数据集的构建带来了额外的复杂性。
常用场景
经典使用场景
SuperCLUE-Agent数据集在智能体中文任务能力测评中展现了其独特的价值。该数据集通过三大核心能力——工具使用、任务规划和长短期记忆,全面评估了各类AI模型在中文环境下的表现。特别是在工具使用方面,数据集通过调用API、检索API和规划API等任务,深入考察了模型在实际操作中的精确性和适应性。这种多维度的评估方式,为研究者提供了一个全面了解模型性能的平台。
实际应用
在实际应用中,SuperCLUE-Agent数据集为各类中文智能体的开发和优化提供了重要参考。企业可以利用该数据集评估其AI产品在工具使用、任务规划和长短期记忆等方面的表现,从而进行针对性的改进。此外,数据集还为教育、医疗和金融等领域的中文智能体应用提供了技术支撑,推动了智能技术在各行业的深入应用。
衍生相关工作
SuperCLUE-Agent数据集的推出,激发了大量相关研究工作的开展。基于该数据集,研究者们开发了多种新型评估方法和优化策略,进一步提升了中文智能体的性能。例如,一些研究专注于提升模型在长程对话和多文档问答中的表现,而另一些则探索了如何通过自我反思和思维链技术增强模型的推理能力。这些衍生工作不仅丰富了中文智能体的研究内容,也为未来的技术突破奠定了基础。
以上内容由遇见数据集搜集并总结生成


