oxford-iiit-pet-clean
收藏Hugging Face2026-01-31 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/KPatelis/oxford-iiit-pet-clean
下载链接
链接失效反馈官方服务:
资源简介:
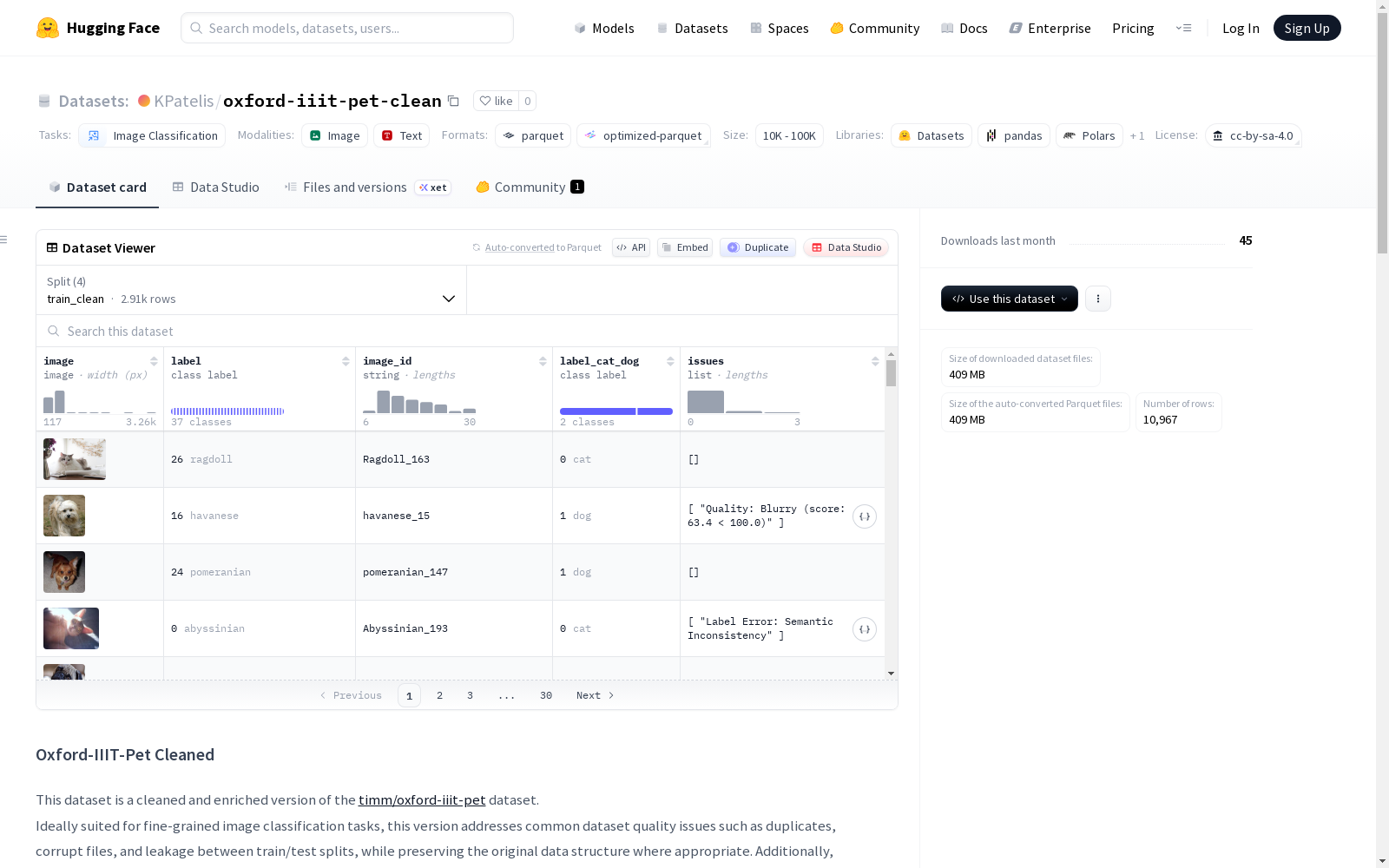
Oxford-IIIT-Pet Cleaned 数据集是原始 Oxford-IIIT Pet 数据集的清理和增强版本,专为细粒度图像分类任务设计。该版本解决了原始数据集中的常见质量问题,如重复文件、损坏文件以及训练/测试集之间的泄漏问题,同时保留了原始数据结构。数据集包含37个宠物类别,每个类别约有200张图像,图像在尺度、姿态和光照方面存在较大变化。
数据集包含四个分割:train_clean(80%的训练集,移除所有关键问题)、val_clean(20%的训练集,同样移除关键问题)、test_clean(移除内部重复和损坏文件)和test_original(原始测试集,未更改行但增加了问题标注)。
数据字段包括:image(图像)、label(分类标签,0-36)、image_id(唯一标识符)、label_cat_dog(猫或狗的分类标签,0或1)以及issues(标注潜在问题的列表)。issues列可能包含文件损坏、健康问题、质量问题、标签错误、内部重复或泄漏等标注。
数据集适用于细粒度图像分类任务和数据质量研究,采用CC-BY-SA 4.0许可。
创建时间:
2026-01-26
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,精细粒度图像分类任务对数据质量提出了更高要求。Oxford-IIIT-Pet Cleaned数据集基于经典宠物图像数据集构建,通过系统化清洗流程移除了原始数据中的重复样本、损坏文件及训练测试集间的泄露问题。构建过程中,采用自动化检测技术识别并标注图像存在的各类质量问题,同时依据品种分层策略将训练集划分为训练与验证子集,既保持了原始数据结构,又显著提升了数据集的可靠性与一致性。
使用方法
针对精细粒度分类研究,使用者可直接加载清洗后的训练与验证集进行模型训练,利用问题标注列过滤低质量样本以定制数据子集。数据集中包含的测试清洗版本与原始版本支持公平的性能对比分析。在实践应用中,研究人员可基于图像标识符追踪样本来源,结合品种与大类标签开展分层评估,或利用标注问题探索数据质量对学习过程的影响机制,为计算机视觉领域提供高质量基准数据。
背景与挑战
背景概述
牛津大学与印度理工学院于2012年联合发布的Oxford-IIIT Pet数据集,标志着细粒度视觉识别领域的重要进展。该数据集由Omkar M. Parkhi、Andrea Vedaldi、Andrew Zisserman等学者共同构建,专注于猫狗品种的精细分类,涵盖37个类别,每类约200张图像。其核心研究问题在于解决在姿态、光照和尺度存在显著差异条件下,实现高精度物种亚类识别的挑战。该数据集已成为计算机视觉领域模型评估与迁移学习的关键基准,推动了细粒度图像分析技术的发展。
当前挑战
在细粒度图像分类任务中,该数据集需应对类间相似度高、类内差异大的固有难题,例如不同犬种间视觉特征的微妙区别。构建过程中的挑战集中于数据质量控制,包括消除训练集与测试集之间的样本泄漏、剔除损坏或无法解码的图像文件,以及识别并标注近重复样本。此外,自动化清理流程还需平衡数据完整性与清洁度,保留可能存在标签噪声或质量问题的样本以供研究,同时确保基准测试的可靠性与可比性。
常用场景
经典使用场景
在细粒度图像分类领域,Oxford-IIIT-Pet Cleaned数据集凭借其精心标注的37种猫狗品种图像,为模型训练提供了标准化的基准。该数据集中的图像在尺度、姿态和光照方面展现出显著差异,这使其成为评估分类算法鲁棒性的理想选择。研究者通常利用该数据集训练深度神经网络,以探索模型在复杂视觉特征下的识别能力,从而推动计算机视觉技术在精细对象识别方向的发展。
解决学术问题
该数据集有效解决了细粒度视觉分类中因数据质量缺陷导致的模型性能评估偏差问题。通过去除重复样本、修复损坏文件并标注潜在问题,它提供了更纯净的数据环境,使研究者能够更准确地分析模型在真实场景下的泛化能力。这一改进有助于揭示数据清洗对模型鲁棒性的影响,为数据集构建方法论提供了实证基础,促进了机器学习可重复性研究。
实际应用
在实际应用中,该数据集为宠物识别系统、智能相册分类及兽医辅助诊断工具的开发提供了关键训练资源。其清晰的品种标注体系可直接服务于宠物行业的信息化管理,例如在宠物保险、遗失寻找等场景中实现自动化品种鉴定。同时,数据集中标注的质量问题也为工业界优化图像采集流程提供了参考标准。
数据集最近研究
最新研究方向
在细粒度图像分类领域,Oxford-IIIT-Pet Cleaned数据集正推动着数据质量与模型鲁棒性的前沿探索。该数据集通过自动化清洗流程,系统性地标注了图像中的模糊、低对比度及潜在标签错误等问题,为研究噪声数据对深度学习模型泛化能力的影响提供了精准的实验平台。当前研究热点聚焦于利用其丰富的质量注释信息,开发自适应训练策略,以提升模型在真实世界复杂视觉场景下的判别性能。这一方向不仅深化了细粒度识别任务的理论基础,也为医疗影像、自动驾驶等关键领域的可靠人工智能系统构建提供了重要参考。
以上内容由遇见数据集搜集并总结生成


