txchmechanicus/CodeX-2M-Thinking
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/txchmechanicus/CodeX-2M-Thinking
下载链接
链接失效反馈官方服务:
资源简介:
CodeX-5M-Thinking是一个精心策划的编码数据集,专门用于基于指令的模型调优和现有模型的微调,增强代码生成和推理能力。这个完全合成的数据集代表了Hugging Face平台上大量且经过全面过滤的编码数据语料库,强调通过逐步推理进行更深层次的模型训练。数据集包含200万个经过高度筛选的编码示例,涵盖从基本语法到高级软件工程的编程领域,质量经过多阶段过滤和验证过程,包括基于排名的过滤和专家选择。数据集特别注重思考过程,响应中包含逐步推理,优化了带有详细思维过程的指令训练。所有代码执行和正确性验证均通过自动化测试框架进行验证。
CodeX-5M-Thinking is a meticulously curated coding dataset designed specifically for instruction-based model tuning and fine-tuning of existing models with enhanced code generation and reasoning capabilities. This fully synthetic dataset represents a large and comprehensively filtered corpus of coding data on the Hugging Face platform, emphasizing a thinking approach with step-by-step reasoning for deeper model training. The dataset includes 2 million examples of highly curated coding data, covering programming domains from basic syntax to advanced software engineering, with quality ensured through multi-stage filtering and verification processes, including ranking-based filtering and expert selections. The dataset has a strong thinking focus, with step-by-step reasoning included in responses, optimized for instruction training with detailed thought processes. All code executions and correctness are verified using automated testing frameworks.
提供机构:
txchmechanicus
搜集汇总
数据集介绍
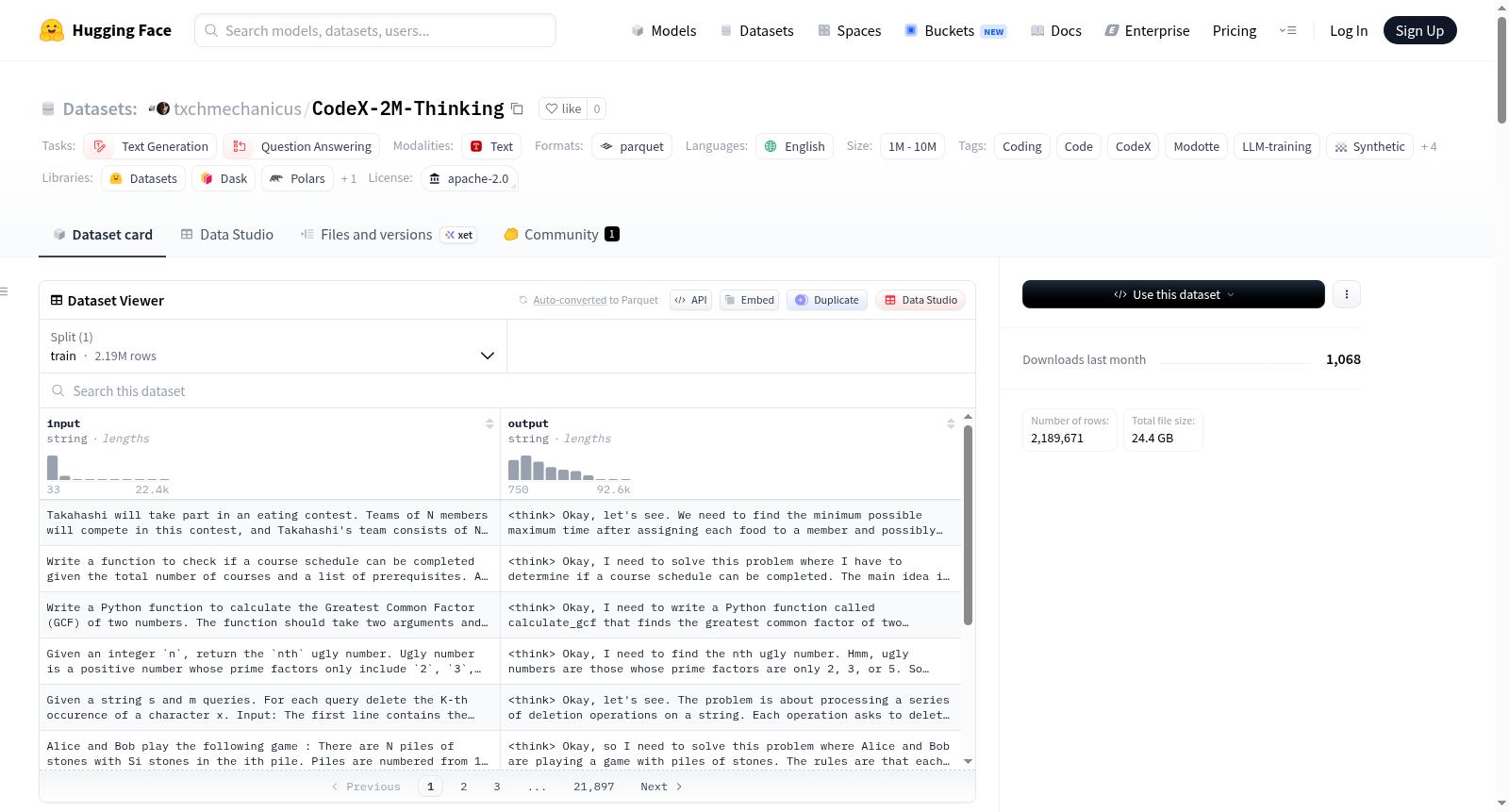
构建方式
CodeX-2M-Thinking数据集采用全合成与精心策展相结合的方式构建而成。其数据来源涵盖公开的高质量编码语料库(如NVIDIA的参考数据集)及Modotte内部生成的合成数据,并借助闭源与开源语言模型进行扩充。构建流程涉及多阶段过滤与验证管线,包括去重、代码规范化、停用词处理、多维度质量评分、基于排名的筛选、专家人工精选、自动化测试框架验证以及内容过滤与多样性平衡,最终保留两百万条高质量编码示例。该过程确保了数据的纯净度、正确性与覆盖面,为指令调优与推理增强提供了坚实的数据基础。
特点
该数据集的核心特点在于规模庞大、覆盖全面且强调推理过程。共包含两百万条经过严格筛选的编码数据,横跨基础语法、算法与数据结构、Web开发、机器学习、系统编程、数据库管理及软件工程等多个编程领域,并按基础、中级和高级三个难度层次分布(高级占40%)。每个示例不仅包含清晰的问题陈述与可执行代码,更附有详尽的逐步推理过程,旨在训练模型生成具备逻辑连贯性、可解释性与正确性的代码解决方案。此外,数据集经过自动化执行验证与人类专家复审,保证了准确性与实用性。
使用方法
使用者可通过Hugging Face Datasets库轻松加载该数据集,只需执行`pip install -U datasets fsspec`安装依赖,随后使用`load_dataset("Modotte/CodeX-2M-Thinking")`导入。该数据集适配文本生成与问答任务,适用于微调代码生成与推理能力的语言模型、训练指令跟随模型、在编程与逻辑推理场景下进行模型性能基准测试,以及开展AI辅助编程、自动化代码补全和可解释AI研究。其标准化的格式——包含问题描述、逐步解答与最终代码——使得数据可直接用于监督式微调与指令微调流程。
背景与挑战
背景概述
CodeX-2M-Thinking数据集由Modotte团队于2024年创建,核心研究人员Parvesh Rawal主导,旨在为指令调优与微调提供高质量的编码推理数据。该数据集聚焦于编程领域的思维链(Chain-of-Thought)生成,融合了多种编程语言与复杂领域知识。作为CodeX系列的重要组成部分,它被设计用于提升模型在代码生成、逻辑推理和问题求解方面的能力。凭借其大规模的样本数量与精细化的筛选流程,该数据集在AI辅助编程、自动化代码理解及可解释人工智能研究中具有显著影响力,为学术界和工业界的模型训练提供了坚实的数据基础。
当前挑战
该数据集面临的核心挑战在于解决领域内代码生成与推理的结合难题,传统数据集往往忽略了逐步推理过程,导致模型输出缺乏可解释性和准确性。此外,构建过程中需应对多重挑战:一是从海量、来源多样(如NVIDIA公开数据与内部合成数据)的编码语料中,通过去重、标准化、质量评分等九阶段过滤流程,确保仅保留最优质的样本;二是平衡基础、中级与高级问题的分布比例(3:3:4),同时覆盖超5种编程语言和8大类编程领域,以避免数据偏斜;三是保障代码可执行性,需借助自动化测试框架进行逐例验证,排除错误或过时的代码。
常用场景
经典使用场景
CodeX-2M-Thinking 数据集作为一款专为指令调优与模型微调设计的高质量合成语料库,其经典使用场景集中于提升语言模型的代码生成与逐步推理能力。在自然语言处理与软件工程交叉领域,该数据集通过提供两百万条经过精心筛选的编程示例,每一条均包含清晰的问题陈述、分步骤的推理过程以及可执行的代码解决方案,从而构建了一个兼具深度与广度的训练资源。研究人员常将其用于监督式微调,以增强模型在理解复杂编程问题后,输出符合逻辑链条的推理文本与准确代码的能力。这一场景有效弥合了传统代码数据集仅关注最终答案的局限,推动模型从“结果复现”向“过程理解”的范式转变。
衍生相关工作
CodeX-2M-Thinking 数据集的发布催生了一系列具有影响力的衍生研究工作。在模型架构方面,研究者借鉴其逐步推理格式,探索了链式思维提示(Chain-of-Thought Prompting)在代码生成中的变体,并提出了融合结构化注意力机制的编码器-解码器模型,以更精确地捕捉推理步骤间的依赖关系。在数据集构建方法论上,其多阶段筛选与专家验证流程为后续合成数据生成提供了范式模板,例如出现了针对特定编程语言(如 Rust 或 Go)的推理增强数据集。此外,该数据集还作为基准用于对比不同规模模型在复杂编程问题上的推理深度与准确性,推动了关于数据质量与模型性能之间非线性关系的实证研究,成为代码智能领域引用率较高的关键资源之一。
数据集最近研究
最新研究方向
在当前大语言模型能力跃升的背景下,CodeX-2M-Thinking数据集聚焦于“推理增强型代码生成”这一前沿方向,通过融合人工校验与多阶段过滤的合成数据,为指令微调模型提供包含逐步推理过程的代码样本。该数据集的设计呼应了业界对模型可解释性与逻辑一致性的迫切需求,特别是在自动化编程、AI辅助软件工程及教育领域,其强调的“思维链”训练范式有望缓解模型生成代码的幻觉问题,推动从简单代码补全向复杂问题求解的范式转变,成为连接高质量数据构建与前沿推理技术的关键桥梁。
以上内容由遇见数据集搜集并总结生成


