PRALEKHA
收藏arXiv2024-11-28 更新2024-12-03 收录
下载链接:
https://huggingface.co/datasets/ai4bharat/Pralekha
下载链接
链接失效反馈官方服务:
资源简介:
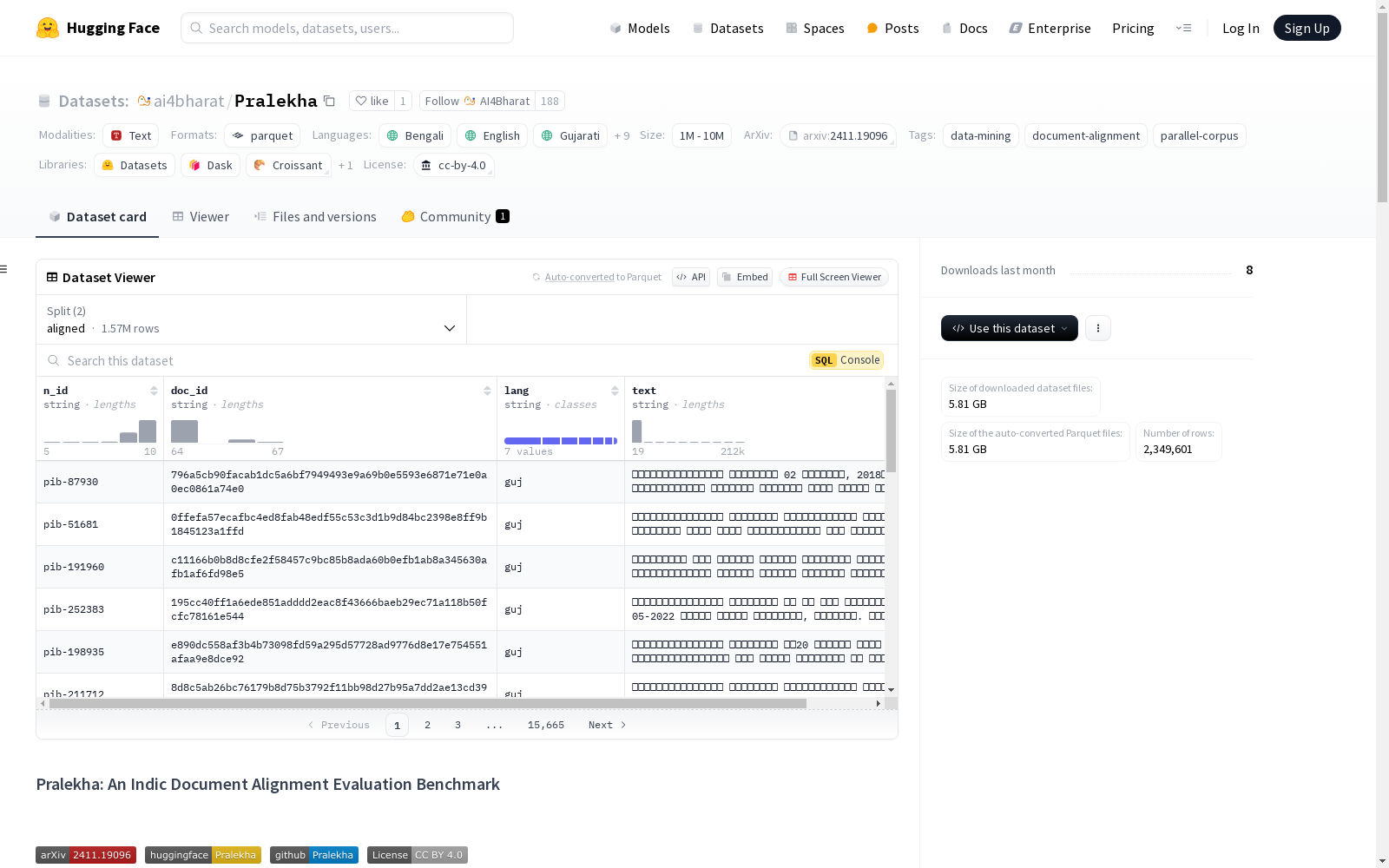
PRALEKHA是由AI4Bharat的尼勒卡尼中心创建的一个大规模文档对齐评估基准数据集,涵盖11种印度语言和英语,包含超过200万份文档,其中对齐与未对齐文档的比例为1:2。数据集内容包括新闻简报和播客脚本,涵盖书面和口语形式。数据集的创建过程包括从印度新闻信息局和曼尼·基巴特广播节目等可靠平台收集和校对数据。PRALEKHA旨在评估和提升多语言文档对齐技术,特别是在印度语言中的应用,以支持文档级神经机器翻译等应用。
PRALEKHA is a large-scale document alignment evaluation benchmark dataset developed by the Neelakantan Center at AI4Bharat. It covers 11 Indian languages and English, containing over 2 million documents with an aligned-to-unaligned document ratio of 1:2. The dataset encompasses news briefs and podcast scripts, spanning both written and spoken modalities. The dataset construction process involved collecting and proofreading data from trusted platforms including the Press Information Bureau and the Mann Ki Baat radio program. PRALEKHA is designed to evaluate and enhance multilingual document alignment technologies, especially their deployment in Indian languages, to facilitate applications such as document-level neural machine translation.
提供机构:
AI4Bharat的尼勒卡尼中心
创建时间:
2024-11-28
搜集汇总
数据集介绍
构建方式
PRALEKHA数据集的构建基于大规模的文档对齐评估需求,涵盖11种印度语言和英语。数据集包含超过200万份文档,其中未对齐与对齐文档的比例为1:2。对齐文档集通过人工验证,来源于印度新闻信息局(PIB)和曼尼·基巴特广播节目等可靠平台。数据收集过程包括自定义抓取和文档对齐,确保了数据的高质量和多样性。
使用方法
PRALEKHA数据集主要用于评估文档级对齐方法的性能,涵盖嵌入模型、粒度级别和算法三个维度。研究者可以通过该数据集测试不同嵌入模型(如LaBSE和SONAR)在不同粒度(句子、块、文档)下的对齐效果,并比较不同对齐算法的优劣。此外,数据集还可用于训练文档级神经机器翻译模型,提升长文本翻译的准确性和连贯性。
背景与挑战
背景概述
随着互联网上多语言内容的爆炸性增长,自然语言处理(NLP)领域,特别是在机器翻译和跨语言信息检索方面,面临着前所未有的机遇与挑战。文档级别的对齐,即在文档层面识别跨语言的语义等价文本,对于构建支持文档级别神经机器翻译(NMT)等应用的数据集至关重要。尽管在句子级别平行数据挖掘方面已取得显著进展,但文档级别的对齐,尤其是对于印度语言,仍然相对未被充分探索。PRALEKHA数据集由Nilekani Centre at AI4Bharat和印度理工学院等机构的研究人员创建,旨在填补这一空白,通过包含超过200万份文档,涵盖11种印度语言和英语,提供了一个大规模的文档级别对齐评估基准。
当前挑战
PRALEKHA数据集面临的挑战主要集中在两个方面。首先,现有的句子嵌入模型通常具有有限的上下文窗口,无法有效捕捉文档级别的信息,这限制了其在文档对齐任务中的应用。其次,缺乏高质量的平行文档对齐评估基准,特别是针对印度语言,使得评估文档级别挖掘方法变得困难。此外,印度语言因其语言多样性、复杂脚本和有限的平行资源而面临额外的复杂性。这些挑战突显了为文档级别对齐任务开发专门策略和资源的必要性。
常用场景
经典使用场景
PRALEKHA数据集的经典使用场景主要集中在多语言文档对齐任务中。该数据集通过提供大规模的平行文档对,支持研究人员评估和开发新的文档对齐算法。具体而言,PRALEKHA被广泛用于测试不同嵌入模型、粒度级别和算法在文档对齐任务中的表现,特别是在处理印度语言和英语之间的对齐问题时。通过这种系统性的评估,研究人员能够识别出在多语言环境下表现最佳的对齐策略,从而为构建高质量的平行文档数据集奠定基础。
解决学术问题
PRALEKHA数据集解决了多语言文档对齐领域中长期存在的学术研究问题。首先,它填补了印度语言和英语之间高质量平行文档数据集的空白,为研究人员提供了宝贵的资源。其次,通过引入文档对齐系数(DAC),该数据集显著提升了对齐算法的精度和F1分数,特别是在噪声环境下。这些改进不仅提高了对齐任务的准确性,还为长上下文神经机器翻译(NMT)模型的训练提供了有力支持,从而推动了多语言自然语言处理(NLP)领域的发展。
实际应用
PRALEKHA数据集在实际应用中具有广泛的前景。首先,它为多语言文档对齐算法的研究和开发提供了基准测试平台,有助于提升文档级机器翻译的质量和效率。其次,通过提供高质量的平行文档对,该数据集支持构建更强大的NMT模型,这些模型能够捕捉文档级别的语义和上下文信息,从而在跨语言信息检索和多语言内容生成等应用中发挥重要作用。此外,PRALEKHA还为印度语言的NLP研究提供了宝贵的资源,有助于推动这些语言在实际应用中的普及和提升。
数据集最近研究
最新研究方向
在多语言自然语言处理(NLP)领域,文档级对齐技术正逐渐成为研究的前沿。PRALEKHA数据集的引入,为评估文档级对齐方法提供了大规模的基准,涵盖了11种印度语言和英语。该数据集不仅填补了印度语言文档级对齐评估的空白,还通过引入文档对齐系数(DAC)显著提升了对齐精度,特别是在噪声环境下,DAC在精度和F1分数上分别实现了20-30%和15-20%的提升。这些研究成果不仅为文档级神经机器翻译(NMT)模型的训练提供了高质量的平行文档数据,还为跨语言信息检索等应用奠定了坚实的基础。未来,研究将聚焦于从网络爬取数据中挖掘大规模平行文档,进一步优化对齐策略,以支持更广泛的多语言NLP应用。
相关研究论文
- 1Pralekha: An Indic Document Alignment Evaluation BenchmarkAI4Bharat的尼勒卡尼中心 · 2024年
以上内容由遇见数据集搜集并总结生成


