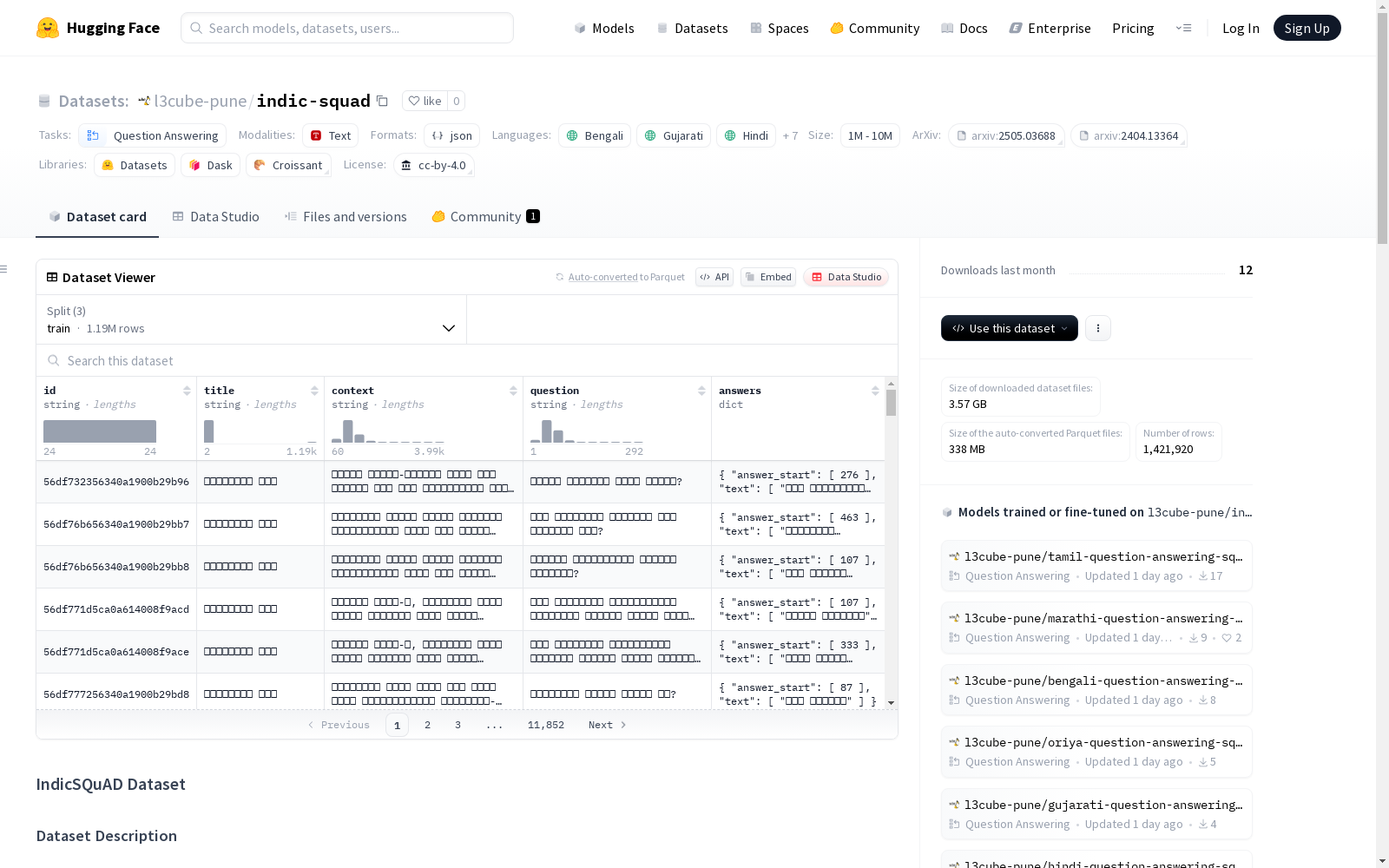
indic-squad
收藏IndicSQuAD 数据集概述
数据集基本信息
- 许可证: cc-by-4.0
- 任务类别: 问答系统
- 语言: 包括孟加拉语(bn)、古吉拉特语(gu)、印地语(hi)、卡纳达语(kn)、马拉雅拉姆语(ml)、马拉地语(mr)、奥里亚语(or)、旁遮普语(pa)、泰米尔语(ta)、泰卢固语(te)
- 数据集名称: IndicSQuAD
- 规模分类: 10K<n<100K
数据集描述
IndicSQuAD 是一个全面的多语言抽取式问答数据集,涵盖九种主要的印度语言:印地语、孟加拉语、泰米尔语、泰卢固语、马拉地语、古吉拉特语、乌尔都语、卡纳达语、奥里亚语和马拉雅拉姆语。该数据集系统地源自流行的英语SQuAD(斯坦福问答数据集)。
语言覆盖
数据集涵盖以下10种印度语言:
- 印地语 (
hi) - 孟加拉语 (
bn) - 泰米尔语 (
ta) - 泰卢固语 (
te) - 马拉地语 (
mr) - 古吉拉特语 (
gu) - 旁遮普语 (
pa) - 卡纳达语 (
kn) - 奥里亚语 (
or) - 马拉雅拉姆语 (
ml)
数据集结构
数据集结构与原始SQuAD数据集相似,包含上下文、问题和相应的答案范围。每个示例包括:
id: 问题-答案对的唯一标识符。title: 提取上下文的维基百科文章标题。context: 包含答案的文本段落。question: 关于上下文的问题。answers: 包含以下内容的字典:text: 来自上下文的可能答案范围列表。answer_start: 上下文中每个答案范围的起始字符索引列表。
引用
如果使用IndicSQuAD数据集,请引用以下论文:
@article{endait2025indicsquad, title={IndicSQuAD: A Comprehensive Multilingual Question Answering Dataset for Indic Languages}, author={Endait, Sharvi and Ghatage, Ruturaj and Kulkarni, Aditya and Patil, Rajlaxmi and Joshi, Raviraj}, journal={arXiv preprint arXiv:2505.03688}, year={2025} }
@article{ghatage2024mahasquad, title={MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering}, author={Ghatage, Ruturaj and Kulkarni, Aditya and Patil, Rajlaxmi and Endait, Sharvi and Joshi, Raviraj}, journal={arXiv preprint arXiv:2404.13364}, year={2024} }
相关BERT模型
| 语言 | 模型链接 |
|---|---|
| 马拉地语 | https://huggingface.co/l3cube-pune/marathi-question-answering-squad-bert |
| 印地语 | https://huggingface.co/l3cube-pune/hindi-question-answering-squad-bert |
| 孟加拉语 | https://huggingface.co/l3cube-pune/bengali-question-answering-squad-bert |
| 泰卢固语 | https://huggingface.co/l3cube-pune/telugu-question-answering-squad-bert |
| 泰米尔语 | https://huggingface.co/l3cube-pune/tamil-question-answering-squad-bert |
| 古吉拉特语 | https://huggingface.co/l3cube-pune/gujarati-question-answering-squad-bert |
| 旁遮普语 | https://huggingface.co/l3cube-pune/punjabi-question-answering-squad-bert |
| 卡纳达语 | https://huggingface.co/l3cube-pune/kannada-question-answering-squad-bert |
| 奥里亚语 | https://huggingface.co/l3cube-pune/oriya-question-answering-squad-bert |
| 马拉雅拉姆语 | https://huggingface.co/l3cube-pune/malayalam-question-answering-squad-bert |