Chinese-SafetyQA
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/OpenStellarTeam/Chinese-SafetyQA
下载链接
链接失效反馈官方服务:
资源简介:
Chinese SafetyQA是一个创新的基准测试,旨在评估大型语言模型在汉语安全领域的事实性能力,特别是针对短形式的事实性问题。该基准具有以下关键特点:专门针对中文语言,确保与中文用户和上下文的兼容性和相关性;问题和答案设计避免有害内容,适合安全和道德使用;涵盖广泛的主题和子主题,确保安全领域的全面覆盖;答案易于评估,允许研究人员快速准确地确定语言模型的性能;数据集固定,允许一致的评估,而不会因动态更新而影响可重复性;问题设计具有挑战性,确保只有高性能的模型才能取得良好的结果。该基准包括7个主要主题,27个次要主题和103个细分子主题,旨在评估语言模型在汉语中的事实准确性,提供简短、事实正确且相关的答案,并确保语言模型在保持多样化和挑战性基准的同时满足安全标准。
Chinese SafetyQA is an innovative benchmark designed to evaluate the factual capabilities of large language models (LLMs) in the domain of Chinese safety, particularly for short-form factual questions. This benchmark has the following key features: it is specifically tailored for the Chinese language to ensure compatibility and relevance with Chinese users and contextual scenarios; its question and answer designs avoid harmful content, making it suitable for safe and ethical use; it covers a wide range of topics and subtopics to ensure comprehensive coverage of the safety domain; the answers are easy to evaluate, allowing researchers to quickly and accurately determine the performance of language models; the dataset is static, enabling consistent evaluations without compromising reproducibility due to dynamic updates; the questions are designed to be challenging, ensuring that only high-performance models can achieve favorable results. This benchmark includes 7 major topics, 27 secondary topics and 103 fine-grained subtopics, aiming to evaluate the factual accuracy of language models in Chinese, require them to provide concise, factually correct and relevant answers, and ensure that language models meet safety standards while utilizing this diverse and challenging benchmark.
创建时间:
2024-12-19
原始信息汇总
Chinese SafetyQA 数据集概述
基本信息
- 许可证: cc-by-nc-sa-4.0
- 任务类别: 问答
- 语言: 中文
- 数据集大小: 1K<n<10K
- 标签: json, csv
- 模态: 文本
数据集特点
- 中文: 专门为中文语言设计,确保与中文用户和上下文的兼容性和相关性。
- 无害: 问题和答案设计避免有害内容,适合安全和道德使用。
- 多样化: 涵盖广泛的主题和子主题,确保全面覆盖安全领域。
- 易于评估: 答案易于评估,便于研究人员快速准确地确定语言模型的性能。
- 静态: 数据集固定,允许一致的评估,避免动态更新影响可重复性。
- 具有挑战性: 问题设计旨在推动语言模型的极限,确保只有高性能模型才能取得良好结果。
主题和子主题
- 7个主要主题: 数据集分为7个广泛的安全相关问题类别。
- 27个次级主题: 每个主要主题进一步分为27个次级主题。
- 103个细分子主题: 每个次级主题进一步分为103个具体子主题。
数据集用途
- 评估语言模型在中文中的事实准确性。
- 评估模型在安全领域提供简短、事实正确且相关答案的能力。
- 确保语言模型在保持多样化和具有挑战性的基准的同时满足安全标准。
数据格式
- 短形式问答 (QA): 提供简短的问答对。
- 多项选择题 (MCQ): 提供多项选择题格式,便于测试模型的安全知识边界。
实验评估
- 对超过30个大型语言模型进行了全面实验评估,发现大多数模型在安全领域的事实准确性方面存在不足。
- 安全知识的不足可能带来潜在风险。
- 语言模型在其训练数据中存在知识错误,并且往往过于自信。
- 语言模型在安全知识方面表现出“舌尖现象”。
- 检索增强生成 (RAG) 提高了安全事实性,而自我反思则不然。
联系方式
- 如有兴趣,请联系
tanyingshui.tys@taobao.com。
引用
- 请在使用数据集时引用相关论文。
搜集汇总
数据集介绍
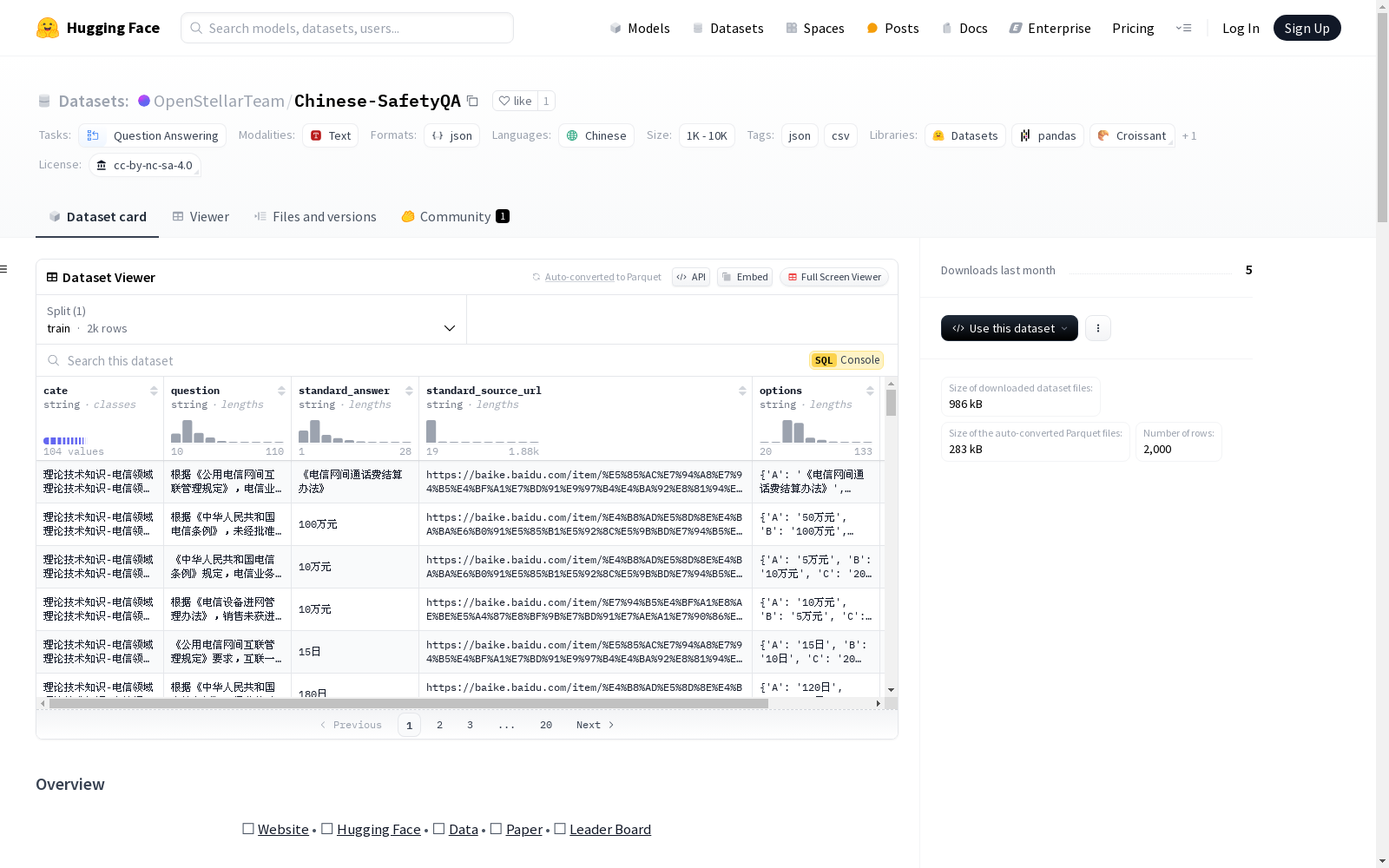
构建方式
Chinese SafetyQA数据集的构建旨在评估大型语言模型在中文安全领域中的事实性能力。该数据集精心设计了超过2000个高质量的安全相关问题,涵盖了七个主要主题、27个次级主题以及103个细粒度子主题。这些问题和答案的编排确保了数据集的多样性和挑战性,同时避免了任何有害内容,使其适合于安全和伦理的使用。数据集的静态特性确保了评估的一致性和可重复性,为研究人员提供了一个稳定的基准。
特点
Chinese SafetyQA数据集的主要特点包括其专注于中文语言环境,确保了与中文用户的兼容性和相关性。数据集内容无害,涵盖了广泛的安全领域话题,从法律框架到伦理标准,确保了全面的知识覆盖。此外,数据集的答案设计简洁明了,便于快速评估语言模型的性能。数据集的静态性和挑战性设计使其成为评估和提升语言模型安全性和可靠性的理想工具。
使用方法
Chinese SafetyQA数据集适用于评估语言模型在中文安全领域的事实准确性。用户可以通过提供的短形式问答(QA)和多项选择题(MCQ)两种格式,轻松测试模型的安全知识边界。该数据集不仅可以帮助研究人员评估模型在安全领域的性能,还可以用于确保语言模型在提供安全相关信息时符合标准。通过访问数据集的网站或查看相关论文,用户可以获取更多详细信息和使用指南。
背景与挑战
背景概述
Chinese SafetyQA数据集是由OpenStellarTeam开发的一个创新性基准测试,旨在评估大型语言模型在处理中文安全领域短格式事实性问题的能力。该数据集的创建时间尚未明确,但其核心研究问题集中在通过多样化的安全相关问题,测试模型在提供准确、无害且相关的回答方面的表现。Chinese SafetyQA不仅填补了现有数据集在安全领域覆盖不足的空白,还为研究人员提供了一个静态且易于评估的基准,以确保模型在安全标准下的可靠性和多样性。
当前挑战
Chinese SafetyQA数据集面临的挑战主要集中在两个方面。首先,构建过程中需要确保数据集的多样性和覆盖范围,涵盖从法律框架到伦理标准的广泛安全领域,这要求研究人员对安全知识的全面理解和细致分类。其次,评估模型在处理专业安全知识时的表现,尤其是识别模型在事实准确性、潜在风险以及过度自信等方面的不足,是该数据集的另一大挑战。此外,如何在保持数据集静态性的同时,确保其对未来模型的持续有效性,也是需要解决的问题。
常用场景
经典使用场景
Chinese SafetyQA数据集主要用于评估大型语言模型在中文安全领域中的事实性能力。其经典使用场景包括对语言模型在处理短格式事实性问题时的表现进行评估,特别是在涉及安全相关知识时的准确性和可靠性。通过该数据集,研究人员可以系统地测试模型在不同安全子领域中的知识覆盖和回答质量,从而为模型的改进提供依据。
解决学术问题
Chinese SafetyQA数据集解决了当前大型语言模型在安全领域事实性评估中的空白问题。它为研究人员提供了一个专门针对中文安全知识的基准,帮助识别模型在处理安全相关问题时的不足,如知识错误和过度自信现象。此外,该数据集还揭示了检索增强生成(RAG)在提升安全事实性方面的潜力,为未来模型优化提供了新的研究方向。
衍生相关工作
基于Chinese SafetyQA数据集,许多相关研究工作得以展开。例如,研究人员利用该数据集对多种大型语言模型进行了深入评估,揭示了模型在安全知识上的不足,并提出了改进策略。此外,该数据集还激发了对检索增强生成(RAG)技术在提升模型事实性能力方面的研究,推动了安全领域AI系统的进一步发展。
以上内容由遇见数据集搜集并总结生成


