MathSpeech
收藏arXiv2024-12-20 更新2024-12-24 收录
下载链接:
https://huggingface.co/datasets/AAAI2025/MathSpeech
下载链接
链接失效反馈官方服务:
资源简介:
MathSpeech是由首尔国立大学开发的一个用于评估自动语音识别(ASR)模型在数学语音识别能力上的基准数据集。该数据集包含1101个从YouTube上的数学讲座录音中提取的音频样本,旨在解决当前ASR模型在处理数学表达式时的性能不足问题。数据集的创建过程包括从公开的数学讲座视频中提取音频,并通过特定的处理方法生成用于训练和评估的数据。MathSpeech数据集主要应用于数学教育领域,旨在通过提高数学语音到公式转换的准确性,改善学习者的理解效果。
MathSpeech is a benchmark dataset developed by Seoul National University to evaluate the performance of automatic speech recognition (ASR) models on mathematical speech recognition tasks. This dataset comprises 1101 audio samples extracted from publicly available math lecture recordings on YouTube, and is designed to address the performance limitations of current ASR models when dealing with mathematical expressions. The creation of the MathSpeech dataset involves extracting audio from math lecture videos hosted on YouTube, and generating dedicated training and evaluation data via specific processing workflows. Primarily applied in the field of mathematics education, the MathSpeech dataset aims to enhance learners' comprehension by improving the accuracy of mathematical speech-to-formula conversion.
提供机构:
首尔国立大学
创建时间:
2024-12-20
搜集汇总
数据集介绍
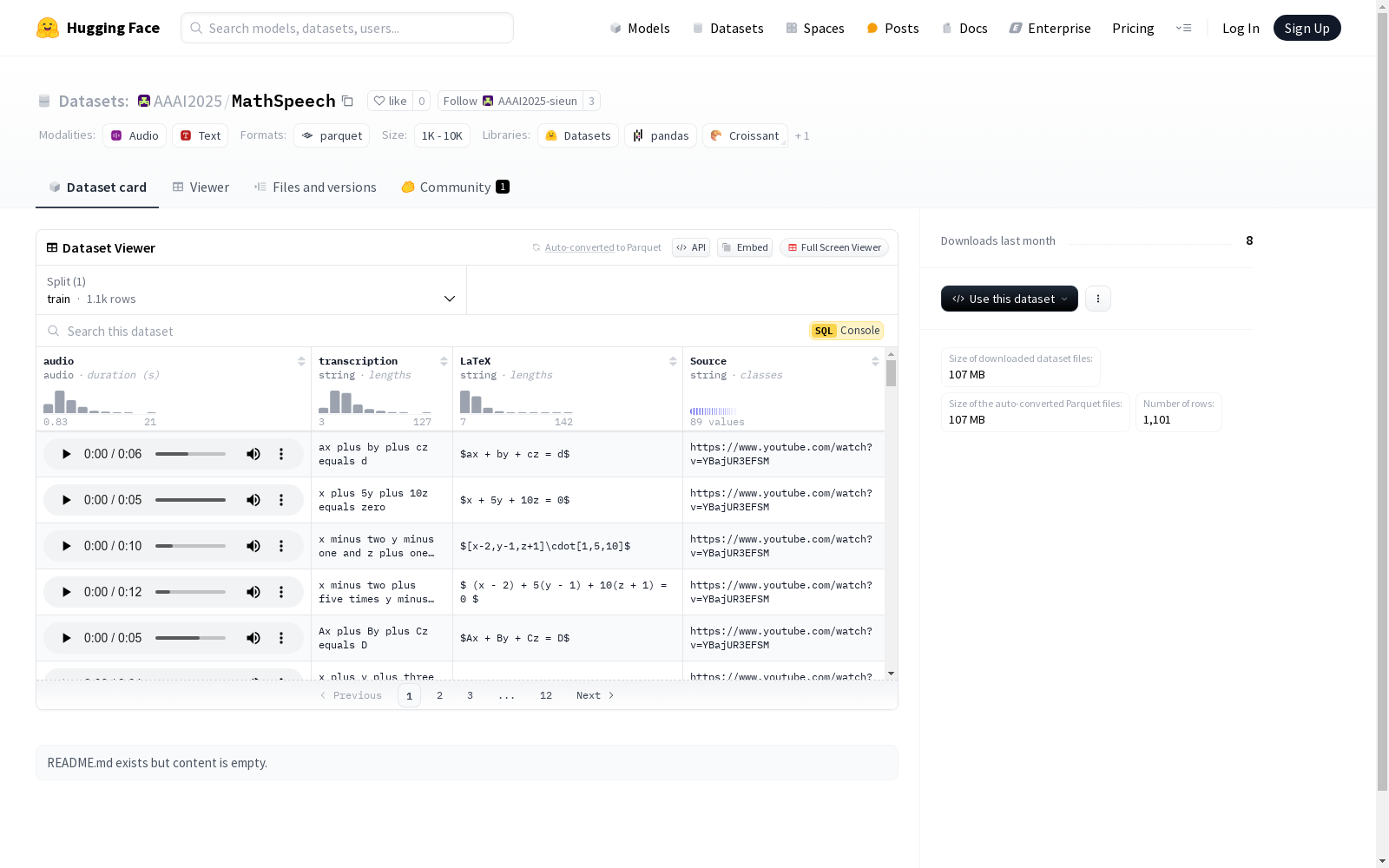
构建方式
MathSpeech数据集的构建基于从YouTube上收集的真实数学讲座录音,共包含1,101个音频样本,总时长为5,583秒。该数据集的构建旨在评估自动语音识别(ASR)模型在数学语音识别中的表现,特别是其在将数学表达式转换为结构化LATEX格式时的能力。数据集的构建过程中,研究团队通过提取MIT OpenCourseWare上的数学讲座音频,确保了数据的多样性和真实性,从而为后续的模型评估提供了可靠的基准。
特点
MathSpeech数据集的主要特点在于其专注于数学领域的语音识别任务,涵盖了复杂的数学表达式和公式。与传统的ASR数据集不同,MathSpeech不仅关注语音到文本的转换,还特别强调将语音转换为LATEX格式的能力。此外,数据集包含了不同性别和口音的演讲者,确保了数据的多样性和广泛适用性。通过这些特点,MathSpeech为评估和改进数学语音识别模型提供了独特的资源。
使用方法
MathSpeech数据集主要用于训练和评估自动语音识别模型在数学语音识别中的表现。研究者可以通过该数据集对ASR模型进行微调,以提高其在数学表达式识别和LATEX转换中的准确性。具体使用时,可以将数据集中的音频样本输入到ASR模型中,并将其输出与标准LATEX格式进行对比,从而评估模型的性能。此外,该数据集还可用于开发和测试新的语音识别和错误校正技术,特别是在数学教育领域的应用中具有重要价值。
背景与挑战
背景概述
MathSpeech数据集由首尔国立大学电气与计算机工程系、数学系以及人工智能跨学科项目等多个机构的研究人员共同开发,旨在解决数学语音识别与转换为LaTeX格式的难题。该数据集的创建源于当前自动语音识别(ASR)模型在处理数学表达时的显著不足,尤其是在将数学公式转换为文本时,往往产生冗长且易出错的描述,而非简洁的LaTeX格式。MathSpeech数据集通过整合ASR模型与小型语言模型(sLMs),旨在纠正数学表达中的错误,并将其准确转换为结构化的LaTeX表示。该数据集的发布为评估ASR模型在数学语音识别中的性能提供了重要基准,推动了数学教育与学术交流的进一步发展。
当前挑战
MathSpeech数据集面临的主要挑战包括:1) 当前ASR模型在处理数学语音时的性能显著下降,尤其是在识别复杂数学公式时,错误率较高;2) 构建过程中遇到的音频质量问题,如旧录音中的噪音、非母语口音以及标签模糊性,这些因素均增加了数据集的复杂性;3) 缺乏适用于数学语音识别的标准化评估指标,现有的BLEU、ROUGE等指标在处理LaTeX格式时表现不佳。此外,MathSpeech在实际应用中还需解决公式检测与分离的问题,以确保在复杂语音环境中准确生成LaTeX格式。
常用场景
经典使用场景
MathSpeech数据集的经典使用场景主要集中在数学语音识别与转换领域。该数据集通过整合自动语音识别(ASR)模型与小型语言模型(sLMs),能够将口头表达的数学公式准确转换为结构化的LATEX格式。这一功能在数学教学、学术演讲以及在线教育平台中尤为重要,尤其是在需要为听力障碍者或语言障碍者提供辅助字幕的场景中,MathSpeech能够显著提升数学内容的可理解性。
衍生相关工作
MathSpeech数据集的发布催生了一系列相关研究工作,尤其是在数学语音识别与LATEX生成领域。许多研究者基于该数据集开发了新的ASR错误纠正方法,并探索了如何通过小型语言模型提升数学公式的转换精度。此外,MathSpeech的成功也启发了其他领域的研究,如光学字符识别(OCR)与数学公式图像的转换,进一步推动了数学内容自动化处理技术的发展。
数据集最近研究
最新研究方向
MathSpeech数据集的最新研究方向主要集中在数学语音识别与公式转换的精确性提升上。该数据集通过整合自动语音识别(ASR)模型与小型语言模型(sLMs),旨在解决现有ASR模型在处理数学表达时的错误率高、输出冗长且难以理解的问题。研究者们提出了一种创新的管道,能够将口语数学表达准确转换为结构化的LATEX格式,从而提升学习者的理解效率。该研究不仅构建了首个用于评估ASR模型数学语音识别能力的基准数据集,还通过实验验证了其在LATEX生成方面的卓越性能,尤其是在字符错误率(CER)、BLEU和ROUGE评分上显著优于商业大型语言模型(LLMs)。这一研究为数学教育领域的字幕生成提供了新的解决方案,具有重要的应用价值。
相关研究论文
- 1MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula首尔国立大学 · 2024年
以上内容由遇见数据集搜集并总结生成


