AudioMCQ
收藏Hugging Face2025-11-26 更新2025-11-27 收录
下载链接:
https://huggingface.co/datasets/inclusionAI/AudioMCQ
下载链接
链接失效反馈官方服务:
资源简介:
AudioMCQ是一个为大型音频语言模型(LALMs)的后期训练设计的全面音频多项选择题数据集。该数据集包含571,118个高质量样本,涵盖多种音频场景,并提供了两种类型的链式思维(CoT)注释,以支持音频理解和多模态学习的高级研究。
创建时间:
2025-11-14
原始信息汇总
AudioMCQ数据集概述
数据集基本信息
- 数据集名称: AudioMCQ
- 官方论文: "Measuring Audios Impact on Correctness: Audio-Contribution-Aware Post-Training of Large Audio Language Models"
- 许可证: Apache-2.0
- 数据总量: 571,118个样本
核心特性
- 音频类型: 声音、音乐、语音、时序
- 标注类型: 结构化思维链、非结构化思维链
- 音频贡献度划分: 弱音频贡献子集、强音频贡献子集
- 源数据集: Clotho、AudioCaps (v2.0)、CompA-R、MusicCaps、LP-MusicCaps (MTT split)、SpeechCraft (LibriTTS-R split)、TACOS
数据格式
每个样本包含以下字段:
source_dataset: 源数据集名称id: 唯一标识符question_type: 问题类型audio_path: 音频文件路径question: 多项选择题文本answer: 正确答案choices: 四个答案选项列表structured_cot: 结构化思维链推理unstructured_cot: 自然语言思维链推理audio_contribution: 音频贡献度标签("weak"或"strong")
数据集文件结构
数据集以JSONL格式组织在./datasets/目录下:
- AudioMCQ_AudioCaps.jsonl
- AudioMCQ_Clotho.jsonl
- AudioMCQ_CompA-R.jsonl
- AudioMCQ_LP-MusicCaps-MTT.jsonl
- AudioMCQ_MusicCaps.jsonl
- AudioMCQ_SpeechCraft.jsonl
- AudioMCQ_TACOS.jsonl
方法学
音频贡献度过滤
- 多模型共识: 使用3个无声音频的LALM,如果≥2个回答正确→弱子集
- 数据划分: 弱音频贡献子集(54.8%)、强音频贡献子集(45.2%)
后训练范式
- 弱到强: 阶段1在弱音频贡献数据上进行SFT,阶段2在强音频贡献数据上进行GRPO(RL)
- 混合到强: 阶段1在混合音频贡献数据(弱+强)上进行SFT,阶段2在强音频贡献数据上进行GRPO(RL)
模型检查点
- 弱到强: https://huggingface.co/inclusionAI/AudioMCQ-Weak-To-Strong
- 混合到强: https://huggingface.co/inclusionAI/AudioMCQ-Mixed-To-Strong
评估方法
- 采用与Qwen2.5-Omni相同的模型加载和使用方法
- 系统提示词: "You are an audio understanding model that answers multiple choice questions based on audio content."
- 输入提示结构: "[Question] Please choose the answer from the following options: [Option1, Option2, Option3, Option4]. Output the final answer in <answer> </answer>."
基准测试准备
- 对MMAR和MMSU基准进行数据整理
- 手动修复少量样本中正确答案不在选项中的问题
- 为MMAR数据集中的所有问题添加适当标点符号
- 精炼版本位于仓库的
./benchmarks/目录中
引用信息
bibtex @article{he2025audiomcq, title={Measuring Audios Impact on Correctness: Audio-Contribution-Aware Post-Training of Large Audio Language Models}, author={He, Haolin and others}, journal={arXiv preprint arXiv:2509.21060}, year={2025} }
搜集汇总
数据集介绍
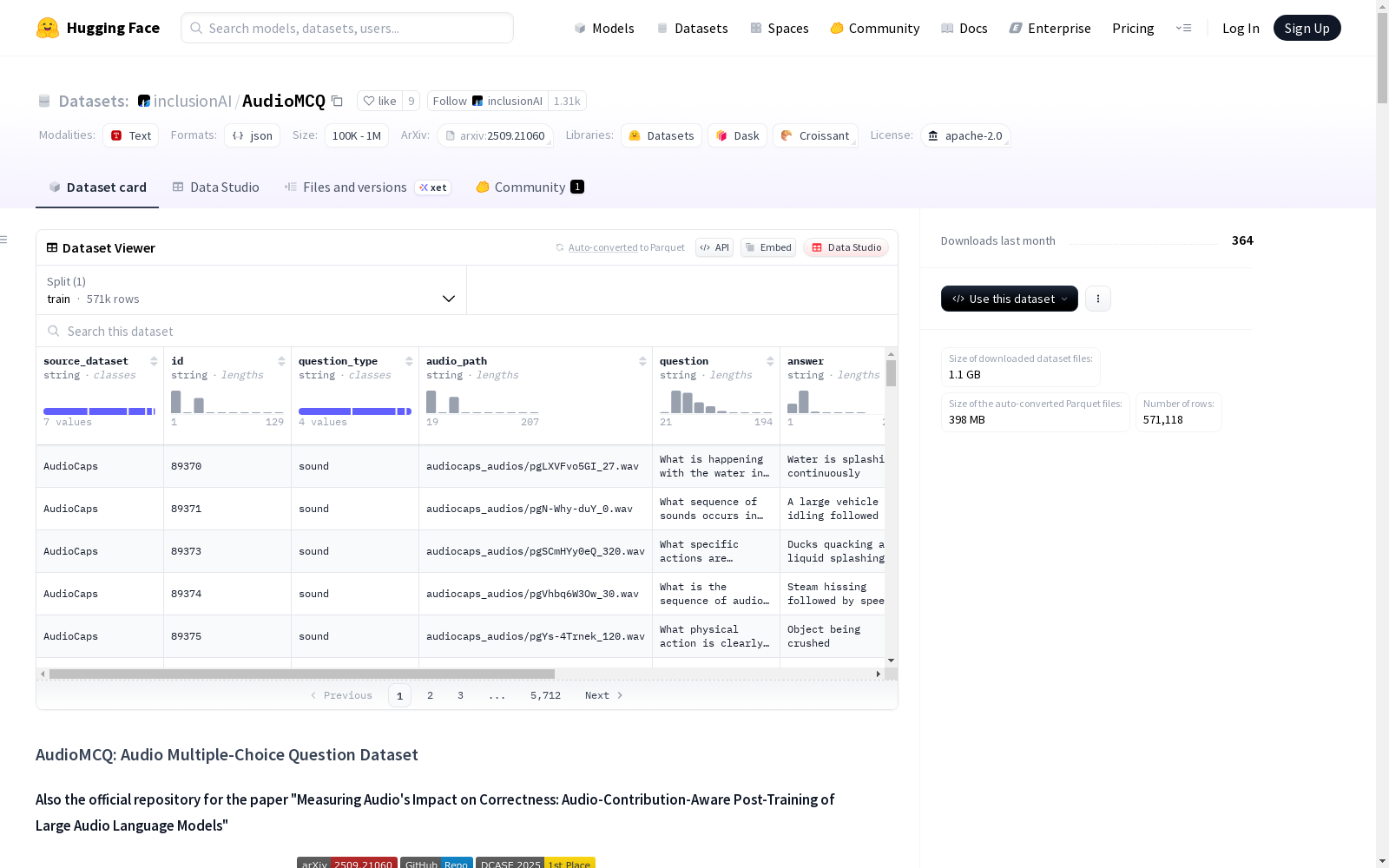
构建方式
在音频语言模型研究领域,AudioMCQ数据集通过系统化整合七个权威音频数据集构建而成,涵盖声音、音乐、语音和时序分析等多模态场景。构建过程采用多模型共识机制进行音频贡献度过滤,由三个大型音频语言模型对静音音频进行推理,当至少两个模型能正确回答问题则归类为弱音频贡献子集,最终形成包含57.1万样本的均衡数据架构。该数据集创新性地引入结构化与非结构化双重思维链标注,为模型训练提供了多维度的推理路径支持。
使用方法
在实践应用层面,AudioMCQ支持两种创新性训练范式:弱到强范式首先在弱音频贡献数据上进行监督微调,继而通过强化学习优化强贡献数据;混合到强范式则采用混合数据初始化后专注强贡献样本的精调。数据集采用标准化JSONL格式存储,每个样本包含音频路径、多选题题干、选项矩阵及双重思维链标注。使用者需预先下载源音频文件并更新本地路径,通过特定提示模板构建输入序列,即可开展端到端的音频语言联合建模研究。
背景与挑战
背景概述
音频多模态学习领域近年来蓬勃发展,AudioMCQ数据集于2025年9月由inclusionAI团队正式发布,作为论文《衡量音频对正确性的影响:基于音频贡献度感知的大型音频语言模型后训练》的核心成果。该数据集聚焦于大型音频语言模型的后训练优化,通过整合Clotho、AudioCaps等七大权威音频数据源,构建了包含57.1万样本的大规模多选问答集合。其创新性地引入强弱音频贡献度划分机制,为探索音频在认知任务中的关键作用提供了重要实验基础,并在DCASE 2025音频问答挑战赛中助力团队斩获冠军,显著推动了音频语义理解研究的发展进程。
当前挑战
构建AudioMCQ过程中面临双重挑战:在领域问题层面,需解决音频语义与文本选项的精准对齐难题,特别是针对音乐、语音等复杂音频场景的细粒度标注;在技术实现层面,多源数据集融合时存在标注标准差异,且链式思维注释需要平衡结构化与自然语言表达的完整性。数据质量控制环节需通过多模型共识机制筛选有效样本,而音频贡献度划分则要求精确量化音频信息对决策的影响权重,这些技术难点共同构成了数据集构建的核心挑战。
常用场景
经典使用场景
在音频语言模型研究领域,AudioMCQ数据集凭借其57.1万条多模态样本,为大规模音频语言模型的后期训练提供了标准化测试平台。该数据集通过声音、音乐、语音和时序四类问题构建的多样化场景,使研究者能够系统评估模型在复杂音频环境下的推理能力,其双链思维标注机制更开创了多步骤音频理解的评估范式。
解决学术问题
该数据集有效解决了多模态学习中音频贡献度量化难题,通过弱强音频贡献度划分机制,首次实现了对音频信息在决策过程中作用的精确度量。其提出的后期训练范式突破了传统模型在音频理解任务中的性能瓶颈,为构建更可靠的音频语言模型提供了理论支撑,显著推动了跨模态表示学习领域的发展。
实际应用
在智能语音助手和音频内容分析等实际场景中,AudioMCQ支撑的模型已展现出卓越的应用价值。基于该数据集训练的模型能够准确解析环境声音语义,在DCASE2025音频问答挑战赛中取得冠军成绩,证实了其在医疗监护、智能家居、安防监控等领域的落地潜力,为构建下一代听觉智能系统奠定了技术基础。
数据集最近研究
最新研究方向
在音频与语言融合的交叉学科领域,AudioMCQ数据集正推动大型音频语言模型的后训练范式革新。该数据集通过571k样本的双重思维链标注,开创性地构建了弱音频贡献与强音频贡献的数据划分机制,为模型在复杂音频场景下的推理能力评估提供了新范式。其提出的弱到强与混合到强两阶段训练框架,在DCASE 2025音频问答挑战中取得突破性成果,显著提升了模型对声音、音乐、语音等多元音频模态的语义理解精度。这种基于音频贡献度的分层训练策略,不仅解决了传统多模态模型中音频信息利用不充分的核心难题,更为构建具有细粒度音频感知能力的下一代智能系统奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


